斯坦福与英伟达:以测促学攻克科学难题


机器之心编辑部
在技术如火如荼发展的当下,业界常常在思考一个问题:如何利用 AI 发现科学问题的新最优解?
一个普遍的解法是「测试时搜索」(Test-time search),即提示一个冻结的(不更新参数的)大语言模型(LLM)进行多次尝试,这一点类似人类在做编程作业时的「猜」解法,尤其是进化搜索方法(如 AlphaEvolve),会将以往的尝试存入缓冲区,并通过人工设计、与领域相关的启发式规则生成新的提示。
可是,尽管这些提示能够帮助 LLM 改进以往的解法,但 LLM 本身并不会真正提升,就像一个学生始终无法内化作业背后的新思想一样。
实际上,能够让 LLM 真正进步的最直接方式是学习。
尽管「学习」和「搜索」都能随着算力扩展而良好地增长,但在 AI 的发展历史中,对于围棋、蛋白质折叠等这类困难问题,「学习」往往最终超越了「搜索」。因为,科学发现本质是:超出训练数据与人类现有知识的 out-of-distribution 问题。
为此,斯坦福大学、英伟达等机构联合提出一种新方法:在测试时进行强化学习(RL),即让 LLM 在尝试解决特定测试问题的过程中持续训练自己。

论文链接:https://www.alphaxiv.org/abs/2601.16175项目地址:https://github.com/test-time-training/discover
具体来看,团队只是把单个测试问题定义为一个环境,并在其中执行强化学习(RL),因此任何标准 RL 技术原则上都可以应用。然而,需要注意的是,这里的目标与标准 RL 存在关键差异,这里的目标不是让模型在各类问题上平均表现更好,而是只为了解决眼前这一个问题,并且只需要产出一个优秀的解决方案,而不是平均产生多个良好的解决方案。
团队将该方法命名为「Test-Time Training to Discover」(TTT-Discover)。为了适应上述目标,其学习目标函数和搜索子程序都旨在优先考虑最有希望的解决方案 。
结果显示,该方法在多种任务上取得了好成绩,包括击败了 DeepMind 的 AlphaEvolve;数学领域 在 Erdős 最小重叠问题上取得了新突破;在 GPUMode 竞赛中,开发出了比人类最佳内核快两倍的全新 A100 GPU 内核;在 AtCoder 测试中超越了最佳 AI 代码和人类代码;在单细胞分析的去噪任务中取得最好成绩……
值得注意的是,该方法在使用开放模型 OpenAI gpt-oss-120b 基础上,计算成本非常低,通过使用 Thinking Machines 的API Tinker ,每个问题只需花费几百美元。
在业界看来,TTT-Discover 所提出的理念,或为持续学习打开了新的想象空间。

TTT-Discover 方法创新
下图展示了 TTT-Discover 的核心机制,展示 TTT-Discover 在测试阶段针对单个问题持续对大语言模型(LLM)进行训练,记 πθi 为在测试时训练第 i 步更新权重后的策略。该图绘制的是 TTT-Discover 在 GPUMode TriMul 竞赛中测试时,第 0 步、第 9 步、第 24 步以及第 49 步(最终阶段)的奖励分布情况,每一步都会生成 512 个候选解。
可以看到,随着训练过程的推进,LLM 逐渐生成更优的解,并最终超越了以往的最优结果(即人类最佳方案)。

需要注意的是,TTT-Discover 没有直接套用标准的 RL 算法(如 PPO/GRPO)。
因为团队认为,标准 RL 优化的是期望奖励(平均分),而科学探索只在乎最大奖励(最高分),只要能找到一个突破性的解,策略在其他时候表现差也没关系;这样的策略容易让发现探索仅仅止步于「安全但平庸」的高分区域,而不敢去尝试可能带来突破的高风险区域。另外,传统算法每次都是从头开始,无法逐步演化复杂解。
为此,团队引入两个关键组件来解决上述问题。
一是熵目标函数,作用是通过指数加权来极端地偏向高奖励样本。随着 β → ∞,熵目标函数趋近于最大值(max)。然而,团队发现,在训练早期若 β 过大,会导致训练不稳定;在训练后期若 β 过小,则随着改进幅度越来越微小,优势函数会逐渐消失,这说明为不同任务设定一个统一且固定的 β 常数是非常困难的。
为此,团队为每一个初始状态自适应地设置 β(s),通过约束由该目标函数诱导的策略的 KL 散度来实现。
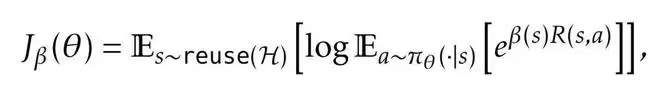
二是受 PUCT 启发的状态复用策略,采用该规则来选择初始状态。每个状态 s 的评分为:
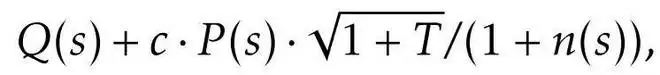
其中,Q (s) 表示当初始状态为 s 时所生成状态中的最大回报(如果 s 尚未被选择过,则取 R (s))。不同于以往研究中采用「平均回报」的做法,团队在 Q (s) 中使用的是子状态的最大回报,这也是关注的核心是从某个状态出发所能达到的最佳结果,而不是平均结果。这种设计确保搜索集中在最有前景的解决路径上,同时保持多样性。
整体来看,熵目标和 PUCT 复用策略的结合使 TTT-Discover 能够优先发现单一的最高奖励解决方案,而不是多个解决方案的平均表现。
结果评估
团队在四个截然不同的领域 —— 数学、GPU 内核工程、算法设计和生物学问题上评估了 TTT-Discover。
除了考虑潜在的影响力外,选择领域的标准还考虑到两个方面,首先,选择能够将自身表现与人类专家进行比较的领域,例如,可以通过与人类工程竞赛中的最佳提交方案或学术论文中报告的最佳结果进行对比来实现,比如数学和算法设计,可以说是近期相关工作取得非常大进展的领域之一。
在每个应用中,团队都报告了已知的人类最佳结果和 AI 最佳结果。
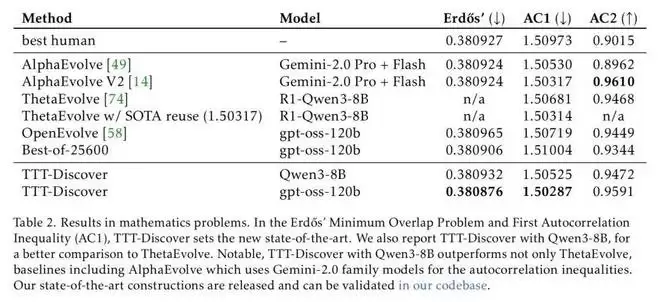
可以看到,在数学领域,关于构造数学对象(如阶跃函数)来证明不等式的更紧致边界 ——Erdős 最小重叠问题任务上,之前人类最佳表现是 0.380927、AI 最佳表现 (AlphaEvolve) 是 0.380924,而 TTT-Discover 刷新记录,拿到了的成绩。
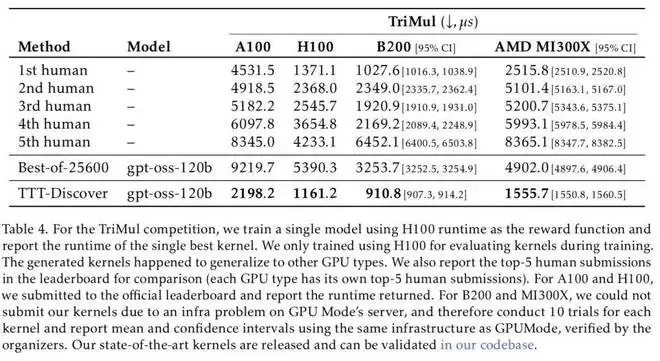
在 GPU 内核优化任务中,首先需要说明的是「新的最优解」(state of the art)意味着实现了比现有方案更快的内核实现。团队选择 GPUMODE 作为评测平台,因为其排行榜经过大量人类竞赛的充分验证,并配备了稳健的评测框架,同时,其基准测试避免了信噪比问题,即避免因操作过于简单或输入规模过小而使系统开销主导运行时间的情况。
结果是,团队的 TriMul 内核在所有 GPU 类型上均达到了当前最优水平。在 A100 上,TTT-Discover 找到的最佳内核比人类专家提交的最优方案快 50%,尽管在训练阶段团队的奖励函数并未在 A100 上直接计时。总体而言,在所有 GPU 类型上,该方法都相对于人类最佳结果实现了超过 15% 的性能提升。
而在另外两项测试中,TTT-Discover 同样取得了非凡的成绩。
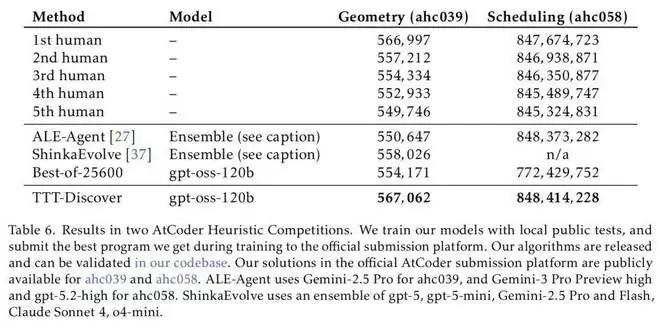
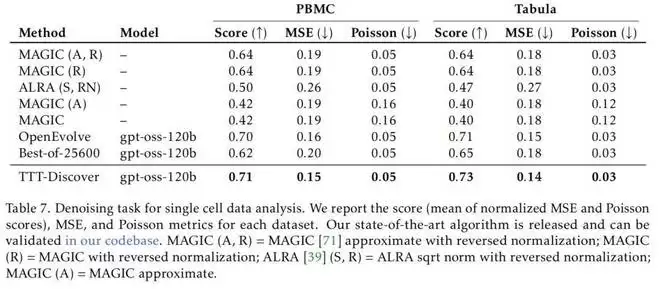
虽然当前 TTT-Discover 方法取得了非常好的成绩,但是团队也承认,该方法目前的形式只能应用于具有连续奖励的问题中,而未来工作最重要的方向是针对具有稀疏奖励或二元奖励的问题,比如数学证明、科学假说,或者不可验证领域的问题(物理、生物推理等)进行测试时训练。
相关攻略

近日,开源具身智能原生框架Dexbotic宣布正式支持以RLinf作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着VLA模型研发中长期存在的「SFT与RL割裂」问题,正在被真正打通。 这是一种典型的「乐高式协作」:双方不强行Fork、不粗暴揉合代码,而是保持清晰边

随着大模型参数规模不断增长,混合专家(Mixture-of-Experts, MoE)架构因其稀疏激活特性,成为平衡模型性能与计算开销的主流方案。然而,在实际的Web级应用部署中,一个关键挑战日益凸显:传统MoE的路由机制通常是“无记忆”的。 试想,在搜索引擎、智能问答或多轮对话等高并发场景下,用户

编程十年的一点分享 在软件开发的路上走过十几年,从一个爱好者到以此为业,有些体会或许值得聊聊,就当是抛砖引玉吧。 最早接触编程,是从BASIC和C语言开始的。工作后,随着需要,陆续学习了dBase、Access这类桌面数据库的开发。真正以开发为职业,可以说始于FoxPro 5 0,之后技术栈随着项目

引言 编程,是一门实践科学。这意味着,学习它的最佳方式就是动手去敲代码。但这是否意味着,我们可以因此轻视理论的学习呢? 入门编程 如果你去各大技术社区提问“该如何入门编程”,五花八门的答案会瞬间涌来。 不过,仔细梳理一下,无外乎以下几种流派: 学院派 他们推荐从C语言入手,并辅以数据结构、操作系统等

想象一下这个场景: 你让 AI Agent 帮你修一个代码 Bug。它打开项目,读了 20 个文件,改了改,跑了一下测试,没过,又改,又跑,还是没过……来回折腾了十几轮,终于——还是没修好。 你关掉电脑,松了口气。然后收到了 API 账单。 上面的数字可能让你倒吸一口凉气——AI Agent 自主修
热门专题







热门推荐

iQOO手机官方今日正式宣布,iQOO 15T已开启全渠道预约。随着预约启动,官方预热海报也首次揭示了新机的侧边轮廓设计。 关于这款新机的更多细节,此前已有数码博主提前剧透。据称,iQOO 15T将延续自家Ultra系列的设计语言,采用标志性的透明风格方形摄像头模组。更引人注目的是其屏幕配置——据爆

期末复习在图书馆熬到深夜,突然下起暴雨,裹紧羽绒服还得冒雨下楼拿外卖;军训结束累得只想瘫倒,宿管阿姨却把骑手拦在宿舍区外;想和室友凑单改善伙食,又被复杂的满减、助力规则搞得晕头转向……这大概是许多大学新生的共同经历,差点以为“冲刺取餐”成了宿舍生存的必备技能。其实,只要掌握正确方法,完全能省去这些奔

一则来自三星(中国)投资有限公司的业务调整通知,在今日引发了广泛关注。通知的核心内容相当明确:为应对急剧变化的市场环境,三星电子决定在中国大陆市场停止销售包括电视、显示器在内的所有家电产品。 这意味着,一个曾经在中国家电市场占据重要地位的品牌,其消费端的产品销售画上了句号。当然,市场更关心的是,存量

关于一加下一代旗舰手机一加 16 的最新爆料信息,近期引发了数码圈的广泛关注。知名数码博主 @数码闲聊站 最新透露了一款代号为 SM8975(即骁龙 8 Elite Gen6 Pro 平台)的子品牌新机细节,结合其暗示的表情符号,这款新机极有可能就是备受期待的一加 16。 根据最新的爆料信息,一加

三星电子的一则公告,在市场上激起了不小的波澜。根据其官方发布的消息,为应对当前急剧变化的市场环境,公司经过慎重评估,决定在中国大陆市场停止销售包括电视、显示器在内的所有家电产品。 图为三星电子发布的公告截图 这意味着,消费者未来将无法在官方渠道购买到三星品牌的电视、显示器等家用电器。不过,对于已经购