随着大模型参数规模不断增长,混合专家(Mixture-of-Experts, MoE)架构因其稀疏激活特性,成为平衡模型性能与计算开销的主流方案。然而,在实际的Web级应用部署中,一个关键挑战日益凸显:传统MoE的路由机制通常是“无记忆”的。
试想,在搜索引擎、智能问答或多轮对话等高并发场景下,用户请求并非完全孤立。大量查询在语义和结构上存在显著的重复性与相似性。但传统路由器每次面对新输入,都需要重新计算并决定激活哪些专家。这意味着,即使模型刚刚高效处理过一个高度相似的问题,当遇到下一个类似请求时,它可能仍需重复整个路由探索过程。
这种“短视”的路由策略会引发几个核心痛点:首先是重复计算,导致推理延迟增加和计算资源浪费;其次是路由结果不一致,输入微小的扰动可能激活截然不同的专家集合;最后,专家之间有效的协作模式难以积累和复用,模型仅进行单次选择,而无法继承历史上已被验证的“专家团队”经验。
针对这一瓶颈,来自马上消费金融、南京航空航天大学、阿里巴巴等机构的研究团队提出了一种创新解决方案——RMS-MoE(检索-记忆协同混合专家模型)。这项研究的核心,是将MoE路由从一个一次性的分类决策,重新定义为“检索-记忆-融合”的动态协同过程。模型不再仅仅依赖路由器的即时判断,而是能够从历史记忆中检索相似输入曾激活过的高效专家组合,并将其与当前路由结果进行智能融合。

论文标题:Rethinking MoE with Retrieval-Memory Synergy: Towards Efficient Expert Coordination
会议:The ACM Web Conference 2026(WWW 2026)
作者:Wanjie Tao, Qun Dai, Yantong Lv, Quan Lu, Ning Jiang, Zulong Chen
机构:马上消费金融、南京航空航天大学、阿里巴巴
论文链接:https://dl.acm.org/doi/epdf/10.1145/3774904.3792922
MoE 路由为什么需要引入「记忆」机制?
MoE架构的核心优势在于其稀疏激活能力。对于给定的输入,路由器会从众多专家中筛选出少数几个参与计算,从而在维持庞大模型容量的同时,显著降低单次前向传播的算力成本。
问题的关键在于,当前主流的MoE路由方式大多遵循“无状态”范式:每个输入都被独立处理,历史上相似输入所积累的专家选择经验,并未被系统性地记录和利用。
这在离线基准测试中或许影响不大,但在真实的Web应用场景中却至关重要。例如,在搜索引擎优化、开放域问答、智能客服以及多轮对话系统中,用户请求存在大量的语义重叠。同类问题、相似任务、相近表达会反复出现。如果系统每次都重新计算专家分配,就会造成显著的计算冗余。更重要的是,对于语义相近的输入,如果激活的专家集合频繁波动,模型输出的稳定性和一致性将难以保证。
RMS-MoE的设计出发点非常直接:既然用户输入具有高度的重复性,那么那些被验证有效的专家协作模式,也应该能够被记忆和复用。与传统RAG(检索增强生成)从外部知识库检索文本内容不同,RMS-MoE检索的不是知识片段,而是模型内部的专家协作模式。换言之,它构建了一种“架构记忆”,让模型能够记住自己过去是如何高效调度专家的。
RMS-MoE:从「即时路由」演进为「检索增强路由」
RMS-MoE的整体框架由三个核心模块构成:协同激活记忆库、自适应融合模块和强化引导的记忆更新机制。协同激活记忆库负责存储和检索历史上高效的专家组合;自适应融合模块动态地融合记忆先验与当前路由器的实时判断;而强化反馈式更新机制则利用任务反馈持续优化记忆库的质量。
具体工作流程如下:当一个新的输入进入模型时,RMS-MoE首先通过输入编码器获得其向量表示,同时标准路由器会生成一个实时的专家激活概率分布。与此同时,协同激活记忆库会根据当前输入的表示,检索出最相似的若干历史样本,并提取这些样本对应的专家激活模式。随后,模型会根据检索相似度和历史效用信息,聚合得到一个“记忆先验”——即历史上相似输入更倾向于激活哪些专家团队。最后,自适应融合模块会学习一个动态的融合权重,将记忆先验与实时路由器的输出结合起来,生成最终的专家激活决策。
这种设计的优势显而易见:对于熟悉的、重复的、语义相近的输入,模型可以更多地依赖历史上已验证有效的专家组合,提升效率与稳定性;而对于新颖或相似度低的输入,模型则可以回退到实时路由器,保持足够的灵活性和探索能力。
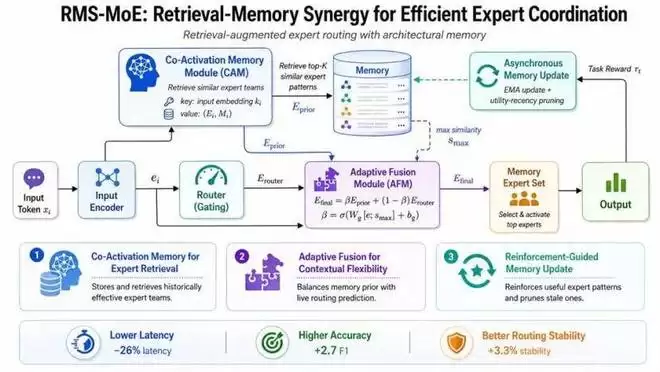
RMS-MoE 方法框架图
协同激活记忆库:记住的不是知识,而是「专家团队」
RMS-MoE的关键创新模块是协同激活记忆库。可以将其理解为一个动态的键值对记忆库。每条记忆记录包含两部分:键是输入文本的嵌入表示,值则是对应的专家激活模式以及相关的元信息,例如历史奖励分数、最近使用时间等。
当新输入到来时,模型会用当前输入的嵌入表示去记忆库中检索最相似的K个条目。每个条目不仅代表一个相似的历史输入,还携带了该输入曾经激活过的专家组合。随后,RMS-MoE会结合检索相似度和历史效用分数,对这些专家组合进行加权聚合,从而得到一个专家选择的先验分布。
这里的核心思想在于:专家之间的共同激活关系,其本身就是一种可复用的结构化知识。传统MoE路由器往往独立评估每个专家是否应该被激活,而RMS-MoE更关注“哪些专家曾经一起有效工作过”。这使得模型不再仅仅是选择单个专家,而是在复用整个专家团队的协作经验。
自适应融合:既相信记忆,也保留实时判断
仅有记忆是不够的。如果模型过度依赖历史经验,在遇到全新任务、新颖表达或低频场景时,就可能产生错误的迁移。因此,RMS-MoE引入了自适应融合模块,它通过一个可学习的动态门控系数β,来平衡记忆先验和实时路由输出之间的权重。
当当前输入与记忆库中的历史样本高度相似时,β值会增大,模型更倾向于使用检索得到的专家组合;当相似度较低时,β值会减小,模型则更多地依赖当前路由器的即时判断。这使得RMS-MoE不会退化为一个简单的缓存系统,而是一个能够根据输入的“熟悉程度”进行自适应决策的智能路由框架。
简而言之,其路由逻辑可以概括为:熟悉的问题,优先复用历史上表现优异的专家团队;陌生的问题,回退到当前路由器,保持探索能力;介于两者之间的问题,则在记忆与实时判断之间进行动态权衡。
强化反馈式更新:让记忆持续进化
为了避免协同激活记忆库退化成静态缓存,RMS-MoE还设计了强化引导的记忆更新机制。在训练过程中,模型会根据任务反馈(如负的训练损失)来更新记忆条目的效用分数,并使用指数滑动平均来平滑历史奖励。
同时,记忆库还会记录条目的“新鲜度”,并在容量受限时,基于“效用-新近度”综合评分进行淘汰。也就是说,一个专家组合如果在历史上多次带来良好的任务表现,它就更容易被保留和再次检索;如果一个组合长期无效或已过时,则会逐渐被削弱甚至移除。
此外,记忆库的更新被设计为异步机制。模型不会在每次前向传播中同步修改索引,而是将更新操作缓冲后批量执行。这种设计避免了对检索索引梯度计算的干扰,也降低了在线更新带来的系统开销,提升了大规模部署的可行性。
实验验证:在 WebQA 和 MultiWOZ 上同步提升准确率、降低延迟并增强稳定性
论文主要在WebQA数据集上进行评估。WebQA包含120万个问答样本,且具有约30%的查询冗余,非常适合测试记忆增强路由在高重复Web场景中的效果。同时,研究团队还在MultiWOZ数据集上验证了该方法在多轮任务型对话中的泛化能力。
实验对比了多种强大的MoE基线模型,包括Switch Transformer、Expert-Choice MoE、Hash-MoE、Soft-MoE和DeepSeekMoE。所有模型使用相同的MoE基础架构:32个专家,隐藏层维度为1024,每个token激活top-4专家。RMS-MoE额外设置协同激活记忆库容量为10^5,检索top-5个记忆条目。实验在8张NVIDIA A100 GPU上运行,并报告了10次运行的均值和标准差。
在WebQA上,RMS-MoE取得了最优结果。相较于DeepSeekMoE,RMS-MoE的F1分数提升了2.7个点,归一化延迟从0.72×降至0.53×,降低了约26%。相较于Switch Transformer,RMS-MoE的端到端延迟几乎减半。在MultiWOZ上,RMS-MoE也保持了类似的趋势,实现了2.5个BLEU分数的提升和34%的延迟降低。这说明该方法具有良好的任务泛化性,能够有效迁移到多轮对话等复杂场景。
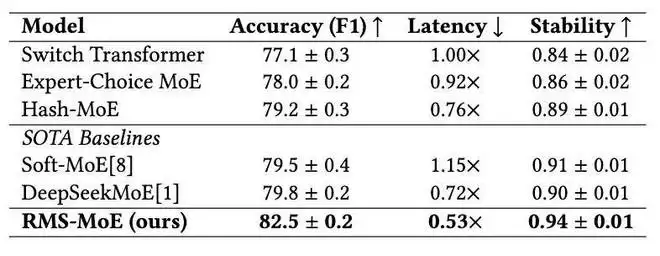
WebQA 主实验结果(Latency 归一化至 Switch Transformer)
消融实验分析:协同激活记忆库是性能提升的关键
为了深入分析各模块的贡献,论文进一步进行了消融实验。结果显示,移除协同激活记忆库后,模型的F1分数从82.5显著降至77.3,稳定性从0.94降至0.85,性能退化最为明显。这证实了检索与复用历史专家协作模式,是RMS-MoE核心收益的来源。
移除自适应融合模块后,F1分数降至78.2,说明简单地使用记忆并不足够,模型必须根据输入情况动态决定“相信记忆”还是“相信当前路由器”。移除强化引导的更新机制后,F1分数降至79.8,稳定性也有所下降,说明记忆质量的持续维护同样至关重要。
敏感性分析进一步表明,RMS-MoE对关键超参数较为稳健。协同激活记忆库容量在10^5附近达到较好效果,top-K检索数量在K=5时形成了较优的准确率-延迟平衡,而融合门控系数β最终稳定收敛到约0.6,这意味着模型会在相当一部分决策中主动利用记忆先验。
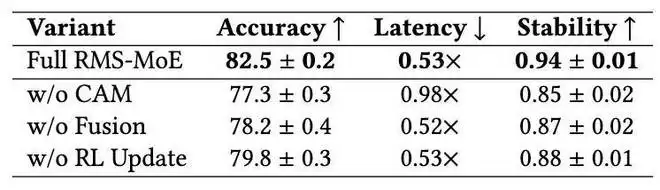
WebQA 消融实验结果
这项研究为何重要?
RMS-MoE的意义,并不仅仅在于提出了一个新的MoE变体。更重要的是,它重新思考了MoE路由的本质。过去,MoE路由通常被看作一个即时决策问题:给定当前token,选择若干专家。RMS-MoE则将其扩展为一个具有历史经验的动态过程:当前输入的路由决策,不仅由当前路由器决定,也可以参考过去相似输入中已被验证有效的专家协作模式。
这带来了三个层面的范式转变。第一,路由从“无状态”变成了“有记忆”。模型能够复用历史上成功的专家组合,减少重复探索。第二,专家选择从“单专家打分”走向了“专家团队复用”。RMS-MoE显式地建模了共同激活模式,让专家间的协作关系成为可检索、可强化、可淘汰的结构化知识。第三,检索增强不再只发生在内容层。传统RAG检索的是外部知识或文本片段,而RMS-MoE检索的是模型内部的架构行为,为提升大模型推理效率提供了新思路。
对于Web级推理系统而言,这一点尤为关键。搜索、问答、对话、推荐和智能客服等场景,都充斥着高频、重复、相似的用户请求。如何在保证模型效果的同时,降低推理成本、提升响应稳定性,是大模型落地过程中非常现实的问题。RMS-MoE提供了一种轻量但有效的思路:让模型记住自己过去做过的有效计算,并在相似场景中复用这些经验,从而实现更智能的资源调度。
结语
随着大模型规模持续扩大,MoE已成为提升模型容量与推理效率的重要技术路线。但真正高效的MoE,不应只是“稀疏激活更多专家”,还应当能够学习和复用专家之间的协作规律。
RMS-MoE创新性地将检索、记忆与专家路由结合起来,为MoE架构引入了一种新的“架构记忆”。实验结果表明,这种设计能够在Web级问答和多轮对话任务中,同步改善准确率、推理延迟和路由稳定性。
展望未来,随着大模型在搜索引擎、智能对话、客户服务系统和复杂任务处理中的进一步部署,如何让模型的内部计算路径更加稳定、可复用、可解释,将成为提升大模型系统整体效率的关键方向。RMS-MoE的工作揭示了一个深刻的视角:大模型不仅需要记住外部知识,也需要记住自己“如何思考”以及“如何高效调度计算资源”。