清华大学校友团队:DeepSeek出手终结ResNet十年统治

新智元报道
编辑:桃子 好困
【新智元导读】2026年架构革命的枪声已经打响!ResNet用十年证明了「加法捷径」能救训练,但也暴露了「只加不减」的天花板。DeepSeek新年王炸之后,普林斯顿和UCLA新作DDL让网络学会忘记、重写和反转。
新年第一天,DeepSeek祭出大杀器——mHC,对「残差连接」做出了重大改进,引爆全网。
紧接着,另一篇重磅研究诞生了!
斯坦福著名教授Christopher Manning读完后直言,「2026年,将成为改进残差连接之年」。
拓展阅读:刚刚,DeepSeek扔出大杀器,梁文锋署名!暴力优化AI架构

这篇来自普林斯顿和UCLA新研究,提出了一个全新架构:Deep Delta Learning(DDL)。
它不再把「捷径」(shortcut)当作固定的恒等映射,而让它本身也能学习并随数据变化。

论文地址:https://github.com/yifanzhang-pro/deep-delta-learning/blob/master/Deep_Delta_Learning.pdf
一个是mHC流形约束超连接,一个是DDL深度增量学习,几乎在同一时间,传递出一个强烈的信号:
残差连接,正在进入一个必须被重新设计的时代。
那么,这篇论文主要解决了什么问题?
ResNet用了十年「加法」
终于被改写了
2015年,ResNet(残差网络)横空出世后,「加法捷径(shortcut)」几乎成为了深度网络的默认配置。
它解决了梯度消失的难题,撑起了现代深度学习的高楼。
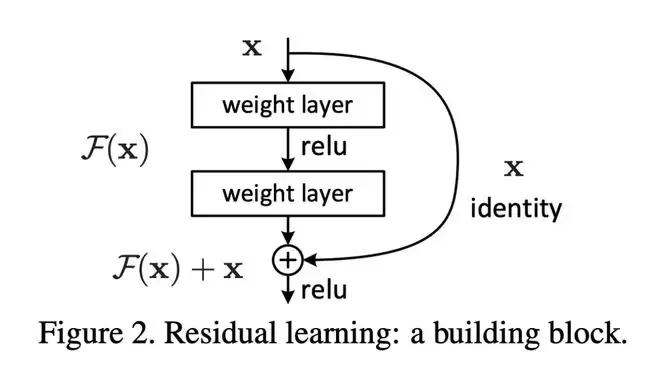
ResNet通过残差学习,解决了深度神经网络训练中的核心难题——层数加深,AI性能不升反降。
ResNet为什么能训得这么深?
因为它只做了一件极其「保守」的事,当深度网络什么都学不会的时候,至少别把输入弄坏。
如今,无论是CNN、ViT,还是各种混合架构,那条「直接把输入加回去」的残差连接,成为了标配。
这套架构设计稳定的同时,也带来了一个后果——
神经网络几乎只会累加信息,却很难修改状态。
经典ResNet核心更新公式非常简单:
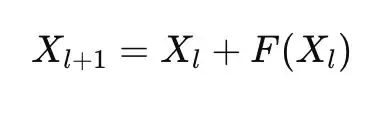
从动力系统角度看,它等价于对微分方程做一步前向欧拉离散。
这意味着,对应的线性算子所有特征方向的特征值都是+1,网络只能「平移」状态,而不能反转、选择性遗忘。
换句话说,旧特征很难被彻底清除,中间表示几乎不会被「反转」,深度网络在表达复杂动态时,显得有些笨重。
如果「捷径」永远只是恒等映射,深度神经网络不够灵活,本质上只能「加法叠加」。
来自普林斯顿和UCLA的最新论文,第一次系统性提出——
这条「捷径」,其实限制了深度神经网络的想象力。
此外,近期一些研究还指出,缺乏负特征值,是深度网络建模能力的隐形天花板。
让深度网络学会「忘记」
如果允许「捷径」本身可以被学习,可以选择性遗忘,甚至可以反转某些特征,会发生什么?
DDL给出的答案是:用一个rank-1的线性算子,替代固定的identity shortcut。
简单来说,DDL把ResNet的「固定加法捷径」,升级成了一个可控的状态更新机制。
其核心变化只有一个——
每一层不再只是加新东西,而会先决定:要不要保留旧状态。
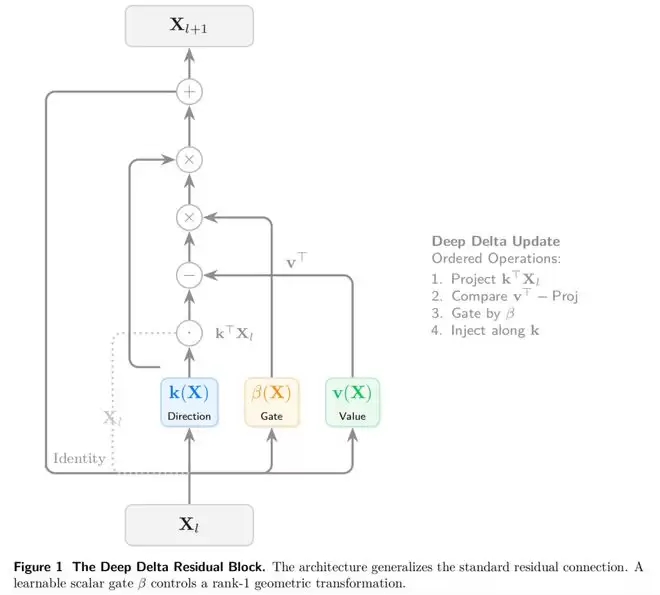
在这个全新架构中,引入了一个非常关键的标量β,这个数值决定了当前层如何对待已有特征。
增量残差块
DDL不再把隐藏状态,看成一个向量,而是一个矩阵
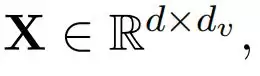
这个设计,让网络状态具备了「记忆矩阵」的含义,也为后续的Delta Rule的对齐埋下了伏笔。
其核心更新公式如下所示:
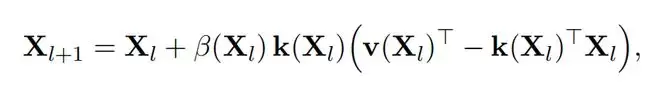
而DDL真正的关键所在,是Delta Operator,让「捷径」不再是I,而是
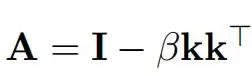
这是一个rank-1 的对称线性算子,其谱结构异常简单。即d−1个特征值恒为1,只有一个特征值是1−β。
换句话说,一个标量β,就能精确控制某个特征方向的命运。
DDL将三种几何行为,统一在一个模块中,以下当β ∈ [0, 2]时,不同情况——
当β接近0时,DDL什么都不做
这一层几乎被跳过,DDL的行为和ResNet完全一致,非常适合深层网络的稳定训练。
当β接近1时,DDL会先忘掉,再写入
这时,网络会主动「清空」某个特征方向,再写入新的内容,类似一次精准的状态重置。
这也恰恰是,传统ResNet很难做到的事。
当β接近2时,DDL就会实现特征反转
某些特征会被直接「翻转符号」,深度网络第一次具备了「反向表达」的能力,这对建模振荡、对立关系非常关键。
值得注意的是,它还出现了负特征值,这是普通残差网络几乎不可能产生的行为。
目前,论文主要提出了DDL核心方法,作者透露实验部分即将更新。
残差网络,2.0时代
为什么这一方法的提出,非常重要?
过去十年,传统残差网络的一个隐患是:信息只加不减,噪声会一路累积。
DDL明确引入了忘记、重写、反转,让网络可以主动清理无用特征,重构中间表示,让建模成为非单调动态过程。
神经网络可以自己决定,如何处理输入的信息。
DDL不会推翻ResNet,当门控(gate)关闭时,它就是普通残差网络,当它完全打开时,便进入了全新的表达空间。
ResNet让深度学习进入了「可规模化时代」,而DDL提出的是下一步——
让深度神经网络不仅稳定,而且具备真正的状态操控能力。
也许多年后回头看,残差网络真正的进化,不仅仅是更深,还会改自己。
最后的最后,我们让ChatGPT分别总结下DDL和mHC的核心贡献:
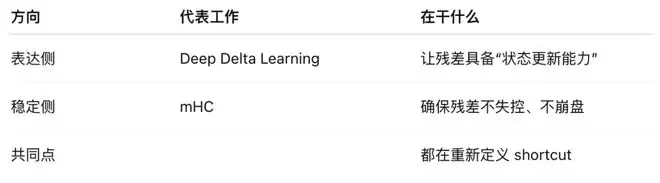
一位网友对这两种革命性架构的亮点总结:

这一切,只说明了一件事:残差连接,真正被当成「可设计对象」来认真对待。
这就像是一个「时代切换」的信号,过去模型变强=更大+更深+更多参数,现在「模型变强=更合理的结构约束」。
作者介绍
Yifan Zhang
Yifan Zhang是普林斯顿大学的博士生,也是普林斯顿AI实验室的Fellow,师从Mengdi Wang教授、姚期智教授和Quanquan Gu教授。
此前,他获得了清华大学交叉信息研究院计算机科学硕士学位并成为博士候选人;本科毕业于北京大学元培学院,获数学与计算机科学理学学士学位。
个人研究重点是:构建兼具高扩展性和高性能的LLM及多模态基础模型。
Yifeng Liu

Yifeng Liu是加州大学洛杉矶分校的计算机博士,本科毕业于清华信息科学与技术学院,姚班出身。
Mengdi Wang

Mengdi Wang是普林斯顿大学电气与计算机工程系以及统计与机器学习中心的副教授。
她曾获得了MIT电气工程与计算机科学博士学位,在此之前,她获得了清华大学自动化系学士学位。
个人研究方向包括机器学习、强化学习、生成式AI、AI for science以及智能系统应用。
Quanquan Gu

Quanquan Gu是UCLA计算机科学系的副教授,同时领导UCLA通用人工智能实验室。
他曾获得伊利诺伊大学厄巴纳-香槟分校计算机科学博士学位,分别于2007年和2010年获得了清华大学学士和硕士学位。
个人研究方向是人工智能与机器学习,重点包括非凸优化、深度学习、强化学习、LLM以及深度生成模型。
参考资料:
https://x.com/chrmanning/status/2006786935059263906
https://x.com/yifan_zhang_/status/2006674032549310782?s=20
https://github.com/yifanzhang-pro/deep-delta-learning/blob/master/Deep_Delta_Learning.pdf
秒追ASI
⭐点赞、转发、在看一键三连⭐
点亮星标,锁定新智元极速推送!

相关攻略

在大模型时代,资源瓶颈不只是硬件问题,更是数学问题。作者|王艺3月25日美股开盘,存储芯片板块集体遭遇“黑色时刻”。美光科技收跌4%,西部数据下跌4 4%,SK海力士跌去5 6%,闪迪更是重挫6 5

破解算力问题,降低模型所需的存算空间,有很多种途径,是减少训练时算力,还是减少推理时算力?稀疏化、量化、压缩、蒸馏等手段,都是方法之一。只是当前鉴于不同方法的优势特征,各家模型企业及研究机构都会选择

马斯克亲自点赞,Kimi动了十一年没人敢碰的东西导语: AI界最“理所当然”的设计之一,终于被质疑了科技博主Avi Chawla在X上发了一条长帖,详细拆解了月之暗面Kimi团队刚刚发布的一篇技术报

机器之心编辑部新年第一天,DeepSeek 发布了一篇新论文,提出了一种名为mHC(流形约束超连接)的新架构。该研究旨在解决传统超连接在大规模模型训练中的不稳定性问题,同时保持其显著的性能增益 。简

新智元报道编辑:桃子 好困【新智元导读】2026年架构革命的枪声已经打响!ResNet用十年证明了「加法捷径」能救训练,但也暴露了「只加不减」的天花板。DeepSeek新年王炸之后,普林斯顿和UCL
热门专题







热门推荐

在《燕云十六声》中领悟“菩提苦海”,需沉浸探索游戏世界。主线剧情构建认知框架,战斗观察、场景细节与NPC对话皆暗藏线索。通过多元视角拼凑因果,方能深入理解游戏蕴含的宏大叙事与深邃魅力。

2026年618大促的序幕刚刚拉开,初期战报已经透露出一些耐人寻味的信号。截至5月21日,海信电视在京东平板电视累计销售竞速榜上拔得头筹,其RGB-Mini LED爆款王——海信小墨E5S Pro,更是同时拿下了天猫平板电视和抖音大家电的5 20单品销冠。 这并非偶然。奥维云网的全渠道监测数据给出了

充电桩领域的“军备竞赛”再次迎来重磅升级。5月22日,极氪汽车正式发布了其全新一代液冷超级充电桩,将单枪峰值功率一举提升至行业领先的800kW,标志着超充技术迈入新阶段。 根据官方披露的核心信息,这款超充桩主要具备四大优势:极速补能、高效节能、广泛适配与多重安全。具体而言,其单枪峰值电流高达800A

获取电弧机剑主要有五种途径:推进主线任务以解锁线索;探索遗迹、工厂等特定区域;挑战特定副本与Boss;完成提及传说武器或遗物的支线任务;参与限时活动并达成要求。玩家可根据偏好选择或组合多种方式获取该武器。

小米汽车再次为潜在车主带来惊喜福利!即日起至5月31日,用户只需提前完成预约,并到店参与任意车型的试驾体验,即可免费获赠一款1:64精致合金车模。车模款式与颜色随机发放,为试驾过程增添一份专属的收藏乐趣,诚意十足。 参与本次活动需注意以下细则:试驾必须通过官方渠道提前预约;各授权门店的车模备货数量不