今天为大家带来一份详细的ZooKeeper与Kafka集群搭建指南。虽然新版Kafka已经能够脱离ZooKeeper实现高可用,但在企业级应用中,ZooKeeper+Kafka这对黄金搭档仍然是主流选择。
Kafka作为分布式消息中间件,能够与Flink、Spark、ELK、日志采集等组件无缝集成,构建强大的实时数据处理平台。
接下来我们将通过实际操作,一步步完成ZooKeeper+Kafka集群的部署。理论学习固然重要,但动手实践更能加深理解,让我们先把集群环境搭建起来。
篇幅较长,建议先收藏!

一、基础环境准备
1. 服务器规划
建议准备3台服务器,构建高可用集群环境。
2. 环境依赖
三台服务器均需执行以下操作:
(1) 修改主机名
# 节点1hostnamectl set-hostname node1# 节点2hostnamectl set-hostname node2# 节点3 hostnamectl set-hostname node3
(2) 安装 JDK 1.8+
下载JDK安装包:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
也可以直接通过yum安装OpenJDK,速度更快
# 将下载上传三个服务器后解压到/data盘tar -xvf jdk-8u461-linux-x64.tar.gz -C /data
配置环境变量:
vi /etc/profile
在文件末尾添加以下内容:
export JAVA_HOME=/data/jdk1.8.0_461export JAVA_BIN=$JAVA_HOME/binexport CLASSPATH=:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport PATH=$PATH:$JAVA_BIN
让配置生效:
source /etc/profile

(3) 关闭防火墙
测试环境可关闭,生产需开放端口。
systemctl stop firewalldsystemctl disable firewalld
(4) 配置主机名解析
cat >> /etc/hosts << EOF10.0.0.190 node110.0.0.191 node210.0.0.192 node3EOF
(5) 关闭SELinux
# 永久关闭sed -i 's/enforcing/disabled/' /etc/selinux/config # 临时setenforce 0
二、部署 Zookeeper 集群
Kafka依赖ZooKeeper管理集群状态,因此需要先安装ZooKeeper。可以先在一个节点下载配置,完成后复制到其他节点即可。
1. 下载并解压(节点1操作)
# 下载,可以选择合适的版本下载wget https://downloads.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz# 解压tar -xvf apache-zookeeper-3.8.4-bin.tar.gz -C /data
2. 配置 zoo.cfg
# 进入配置文件目录cd /data/apache-zookeeper-3.8.4-bin/conf# 复制参考配置文件cp zoo_sample.cfg zoo.cfg# 修改配置文件,主要修改下面两项dataDir=/data/zookeeper/dataserver.1=node1:2888:3888server.2=node2:2888:3888server.3=node3:2888:3888
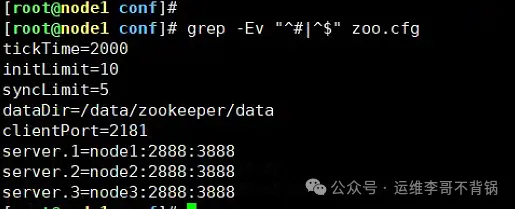
参数解析:
dataDir:存储快照和myid文件的路径。 server.X:集群成员配置,其中2888端口:内部通信端口,与Leader通信;3888端口:用于选举Leader。3. 拷贝到另外两个节点
scp -r /data/apache-zookeeper-3.8.4-bin root@10.0.0.191:/datascp -r /data/apache-zookeeper-3.8.4-bin root@10.0.0.192:/data
4. 配置节点 ID
# 每个节点新建文件夹mkdir -p /data/zookeeper/data# 节点1echo 1 > /data/zookeeper/data/myid # 节点2echo 2 > /data/zookeeper/data/myid# 节点3echo 3 > /data/zookeeper/data/myid
5. 配置环境变量
将zookeeper加入环境变量,方便后期启动。三个节点均需配置。
vi /etc/profile # 尾部添加export ZOOKEEPER_HOME=/data/apache-zookeeper-3.8.4-binexport PATH=$ZOOKEEPER_HOME/bin:$PATH# 使配置文件生效source /etc/profile
6. 启动 Zookeeper
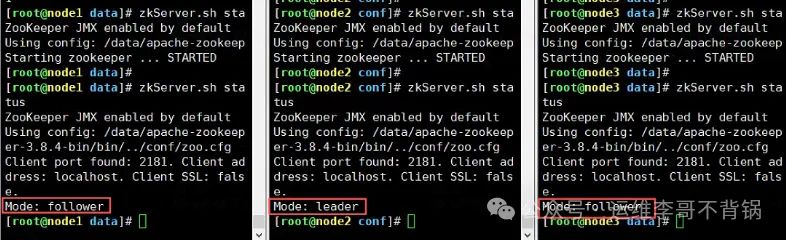
zkServer.sh startzkServer.sh status
确认3台机器都正常启动,其中两台为follower,一台为leader,则ZooKeeper集群安装成功。
三、部署 Kafka 集群
1. 下载并解压
跟ZooKeeper一样,先在节点1下载,配置完后复制到另外两个节点。
# 下载安装包wget https://downloads.apache.org/kafka/3.9.1/kafka_2.13-3.9.1.tgz# 解压到/data目录tar -xvf kafka_2.13-3.9.1.tgz -C /data
2. 修改配置文件
进入到安装目录,编辑配置文件server.properties。
cd /data/kafka_2.13-3.9.1/configvi server.properties
修改下面信息
broker.id=1 # 不得重复,整个集群中唯一listeners=PLAINTEXT://10.0.0.190:9092 # 监听端口log.dirs=/data/kafka/logszookeeper.connect=node1:2181,node2:2181,node3:2181num.partitions=3
参数解析:
broker.id:Kafka Broker唯一ID,node1=1,node2=2,node3=3。 listeners:服务监听地址和端口。需要换成真实的IP地址,每个节点填本机IP地址。 log.dirs:存储Kafka消息日志的目录。建议挂载大容量磁盘。 num.partitions:Topic默认分区数,决定并行消费能力。 zookeeper.connect:连接zookeeper。3. 配置拷贝到另外两个节点
scp -r /data/kafka_2.13-3.9.1 root@10.0.0.191:/datascp -r /data/kafka_2.13-3.9.1 root@10.0.0.192:/data
注意:节点2和节点3需要修改broker.id和listeners两个配置

新建日志目录(每个节点操作)
mkdir -p /data/kafka/logs
4. 配置环境变量
将kafka加入环境变量,方便后期启动。三个节点均需配置。
vi /etc/profile # 尾部添加export KAFKA_HOME=/data/kafka_2.13-3.9.1export PATH=$KAFKA_HOME/bin:$PATH# 使配置文件生效source /etc/profile
5. 启动 Kafka
kafka-server-start.sh -daemon /data/kafka_2.13-3.9.1/config/server.properties
三台机器依次启动Kafka。可以看到kafka进程已正常启动。

四、测试验证
1. 创建 Topic
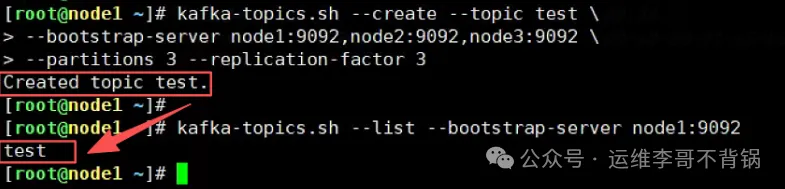
kafka-topics.sh --create --topic test \--bootstrap-server node1:9092,node2:9092,node3:9092 \--partitions 3 --replication-factor 3
参数解析:
--partitions 3:分区数,决定并发度。 --replication-factor 3:副本数,保证容错能力。2. 查看 Topic
kafka-topics.sh --list --bootstrap-server node1:9092
3. 生产消息
kafka-console-producer.sh --broker-list node1:9092 --topic test> hello lige> hello kafka
4. 消费消息
kafka-console-consumer.sh --bootstrap-server node2:9092 --topic test --from-beginning

至此,集群搭建完成。




