8月26日,知名科技媒体9to5Mac发布最新研究报告,苹果科研团队创新性地提出"基于清单反馈的强化学习"(RLCF)训练方法。与传统依赖简单点赞/点踩的人类反馈机制不同,这项突破性技术通过详尽的任务清单对大语言模型(LLMs)进行精准指导,使其复杂指令处理能力获得质的飞跃。
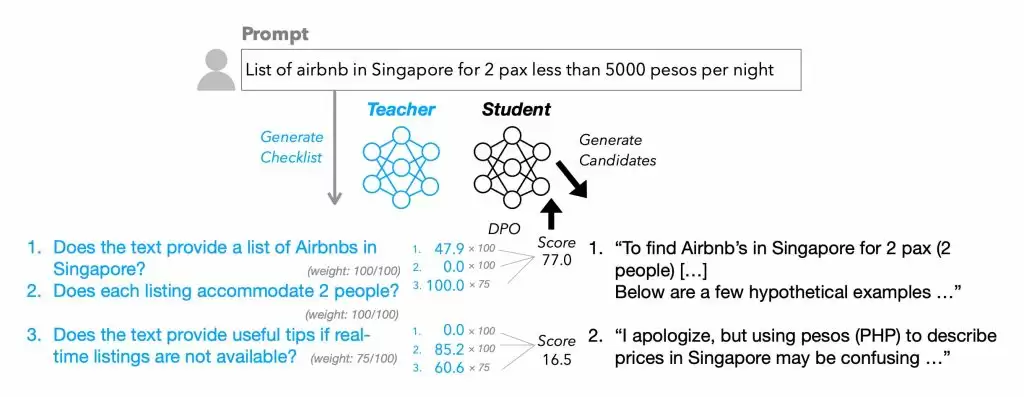
注:RLCF全称Reinforcement Learning from Checklist Feedback,摒弃了传统RLHF(人类反馈强化学习)的粗放评分模式,转而针对每条指令生成包含具体评分细则的检查清单,以0-100分的精细化评估体系驱动模型迭代优化。
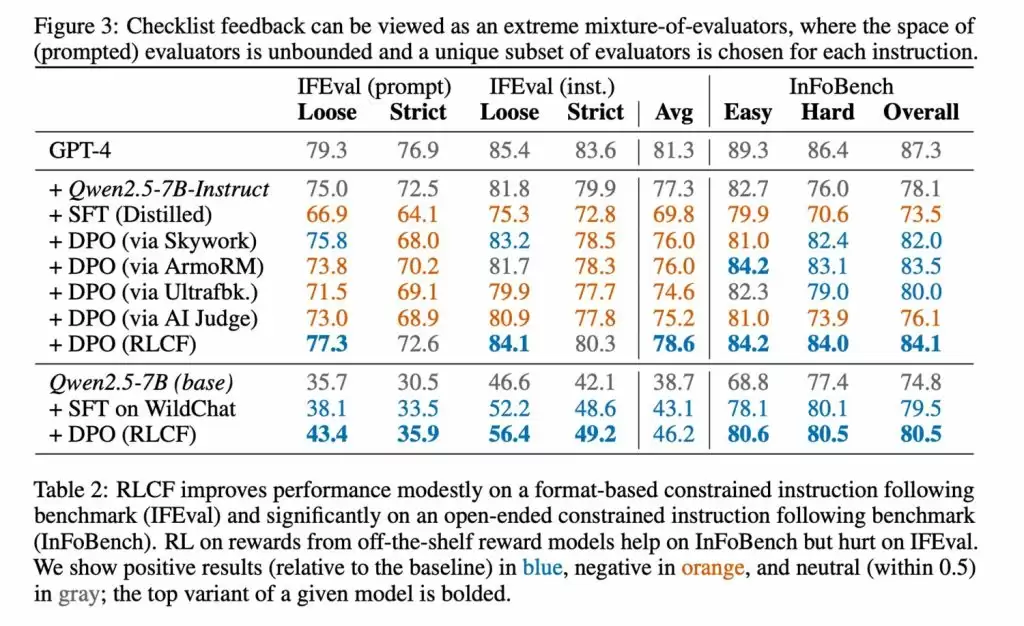
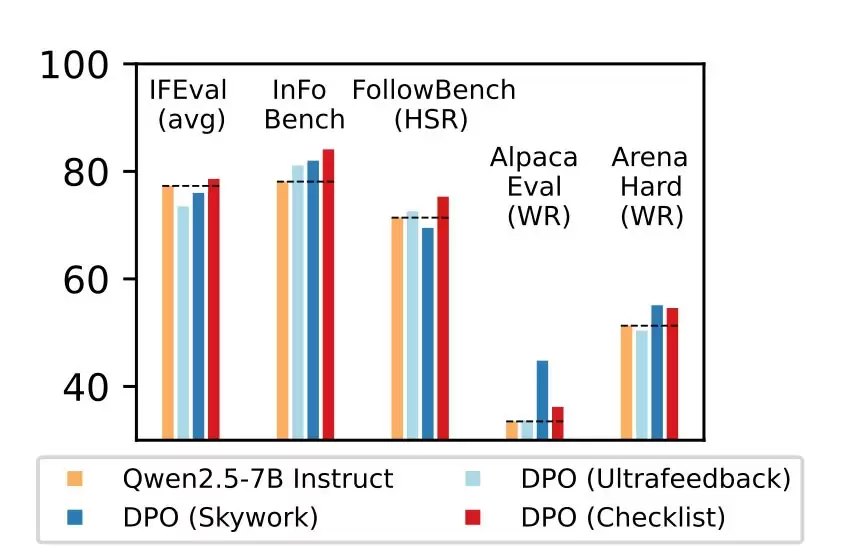
研究团队在Qwen2.5-7B-Instruct模型上进行了严谨测试,覆盖五大主流评测基准。数据显示,RLCF是唯一在所有测试环节均呈现显著效果提升的方案:
- FollowBench评估中硬性指标满意度提升4%
- InFoBench测试得分增长6个百分点
- Arena-Hard对战胜率提高3%
- 特定任务场景最大优化幅度达8.2%
这些数据充分验证了清单反馈机制在处理多步骤复杂指令时的卓越表现。
这项技术的另一大亮点是其创新的清单生成流程。研究团队借助性能更强的Qwen2.5-72B-Instruct模型,结合前沿方法论,为13万条训练指令构建了"WildChecklists"专业数据集。每份清单包含系列二元判定项(如"是否完成西班牙语翻译?"),由大模型对答复进行逐项评分并加权计算,最终转化为训练信号传递给待优化模型。
苹果研究人员也客观指出了当前方案的局限性。首先,该方法需要依赖更强大的辅助模型进行评估,在资源受限环境下可能难以实施;其次,RLCF主要聚焦指令执行能力的提升,并非为安全对齐而设计,因此不能替代专门的安全评估流程。该方法在其他任务类型中的普适性仍需后续研究验证。





