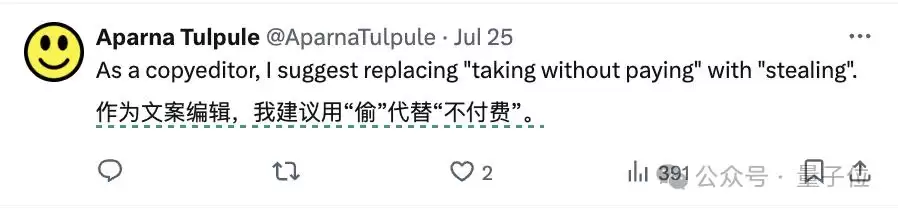
不少网友对此表达了强烈不满。一位从事文案工作的朋友在留言中直言不讳:
“我认为用‘窃取’来描述Anthropic的这种行为,远比‘未付费’要贴切得多。”
一时间,舆论场炸开了锅。
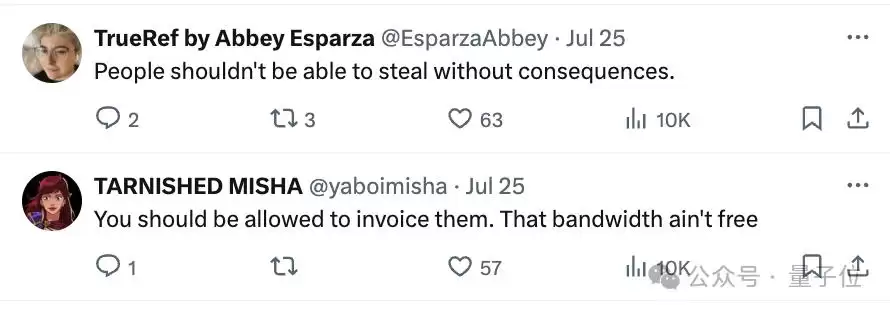
声讨之声此起彼伏,要求Claude付费的呼声不断涌现,评论区瞬间陷入沸腾。
事件原委
这次引发众怒的主角,是一家名为iFixit的美国公司。它主营电子商务与操作指南业务,其中最具特色的一块是为消费电子产品及小型工具提供类似维基百科模式的免费在线维修指南。
网站内容极为丰富,涵盖数百万个页面,包括维修指南、指南修订历史、博客文章、新闻资讯与研究报告、社区论坛、用户贡献的修理教程以及问答板块等。
然而,iFixit最近发现,自家的网站正被Claude的爬虫程序ClaudeBot以每分钟数千次的频率疯狂扫描,且连续持续了数小时之久。
据统计,短短一天内,该爬虫几乎访问了iFixit将近一百万次。
更直观的数据是:它在一天内抓取了10 TB的文件,整个5月份的累计抓取量更是高达惊人的73 TB。

对此,iFixit的CEO老K(Kyle Wiens)只掷下一句话:
请注意——「未经许可」。
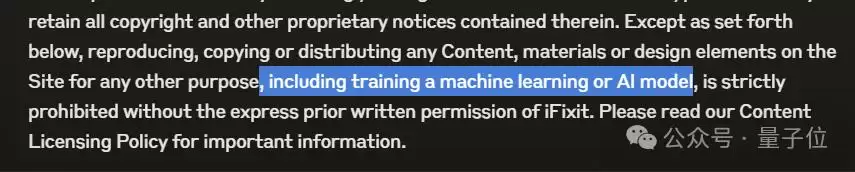
事实上,iFixit早有明确声明:
未经iFixit事先书面许可,严禁以任何目的(包括训练机器学习或人工智能模型)复制、复制或分发本站的任何内容、材料或设计元素。
然而,这纸声明似乎形同虚设。
Claude不仅置若罔闻,继续疯狂访问和抓取,还成功绕过了iFixit的防御措施。
iFixit曾成功屏蔽了两个Anthropic的AI抓取机器人——分别名为“ANTHROPIC-AI”和“CLAUDE-WEB”。
但很快发现,这两个老型号似乎已经“退役”,当前的主力爬虫正是那个未被拦截的“ClaudeBot”。
走投无路之下,老K表示,iFixit本周修改了robots.txt文件,专门用于阻止Anthropic的爬虫。

那么,Anthropic方面有何回应?
它们并未保持沉默,而是通过媒体表态:
不过,对于目前活跃的ClaudeBot是否遵守robots.txt协议、是否会自动避开被禁止抓取的内容,Anthropic巧妙避开了正面答复。
AI公司并非初犯
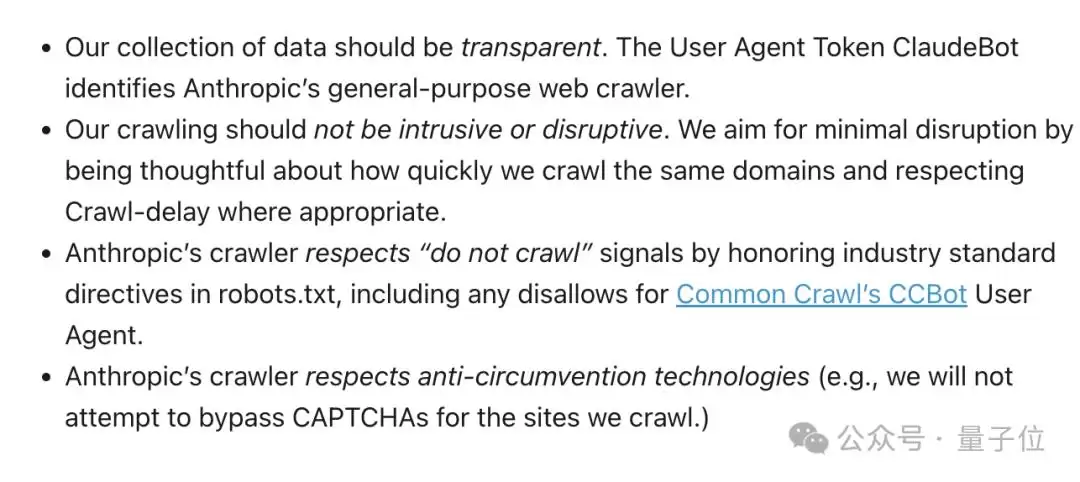
翻阅Anthropic的官网,可以发现一篇早已发布的文章,标题为《Anthropic是否从网络上抓取数据?网站所有者如何阻止抓取工具?》。
文中写得明确:
但从舆论反馈来看,Anthropic的实际行动显然与自身声明相悖。
未经允许爬取他人数据,这已是它的惯用伎俩。
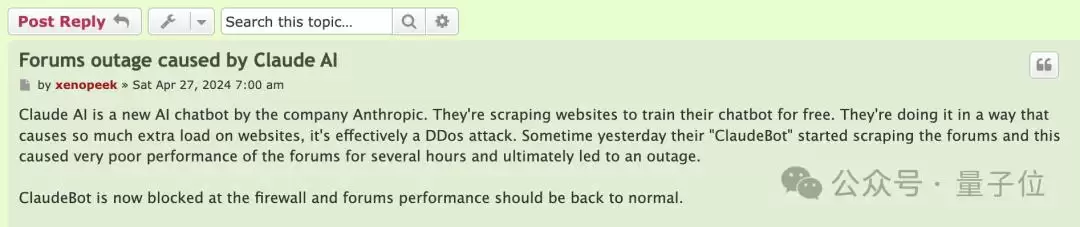
就拿今年4月来说,Linux Mint论坛就曾遭受重创。
短短数小时内,ClaudeBot多次访问论坛抓取数据,直接导致论坛长时间处于超低速甚至崩溃状态,最终彻底宕机。
有统计显示,在同一时间段内,ClaudeBot占用的流量是第二名爬虫的20倍,第三名的40倍。
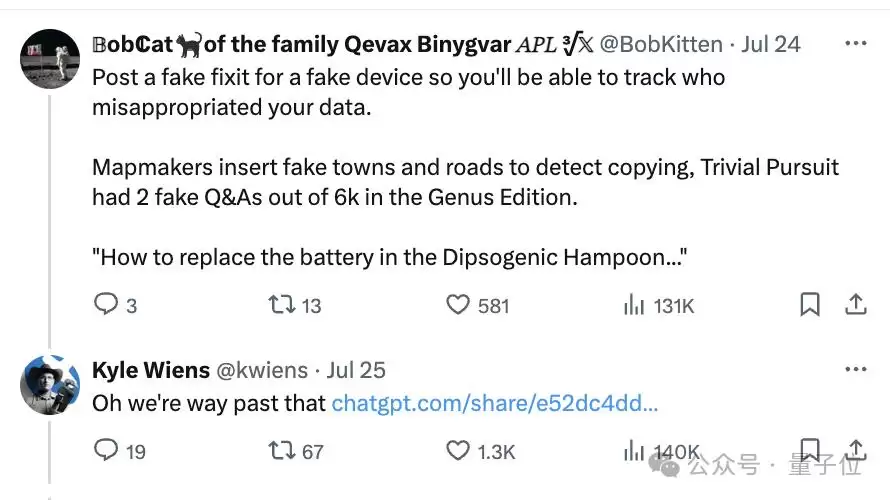
在4月事件和本次事件的讨论帖中,有人反复建议:
iFixit确实也采取了这一做法。
而且效果立竿见影——不仅发现自家信息被Claude爬了个底朝天,回头一看,连OpenAI也跑来分了一杯羹。
说实话,还有什么别的办法呢?似乎真的无计可施了。
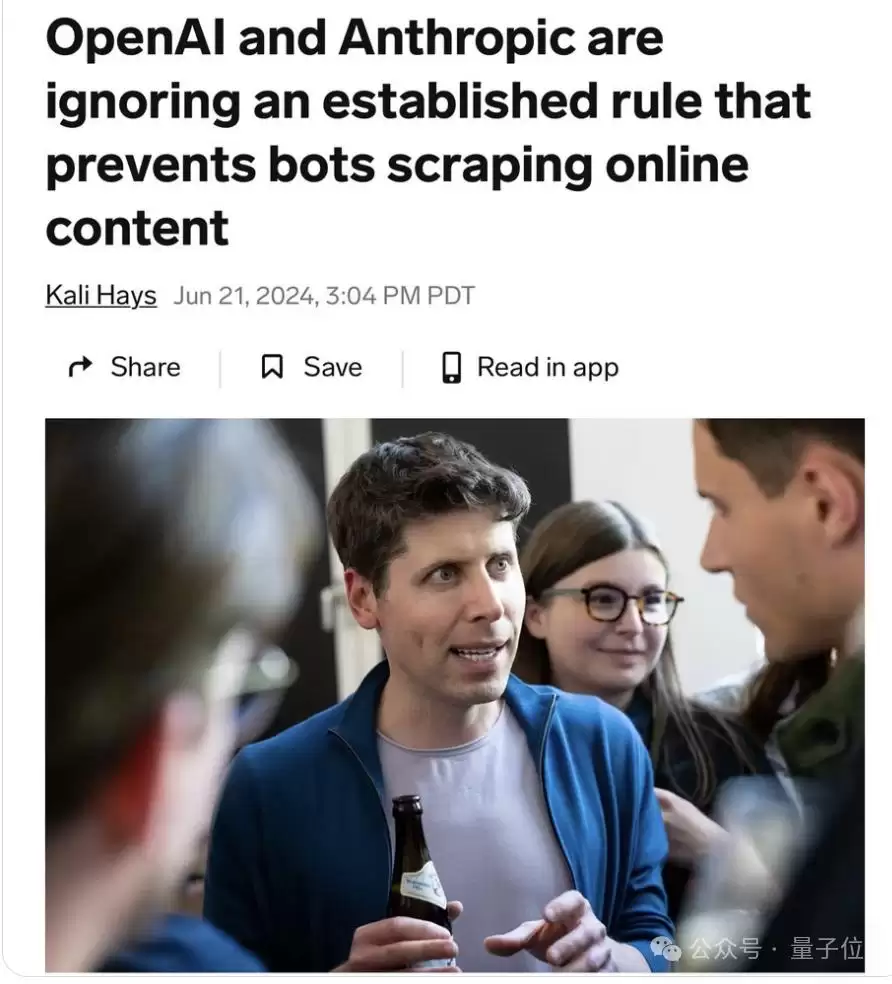
因为除了Claude和GPT,类似的“强行窃取”事件在AI圈内屡见不鲜。
前几天,一家名为Tollbit的机器人检测初创公司声称,Perplexity、Claude、OpenAI会无视网站上的robots.txt设置——当时有人向OpenAI求证,对方直接不予回应。
再往前推,上个月也曾闹出一出。
《福布斯》公开谴责AI搜索产品Perplexity涉嫌抄袭其新闻文章;一石激起千层浪,更多媒体站了出来,指责Perplexity的爬虫机器人PerplexityBot非法抓取自家网站内容。
而Perplexity一直以来的态度是:
理论上,无论是ClaudeBot还是PerplexityBot,遇到标明“禁止抓取”或“禁止robot.txt”的文件时,都应遵守协议,规避爬取声明方的内容。
既然声明无效,有人开始建议创作者将内容尽可能转移到付费区域,以此防止无限制的抓取。
你认为,这一招真的会管用吗?
参考链接:
[1]https://www.404media.co/websites-are-blocking-the-wrong-ai-scrapers-because-ai-companies-keep-making-new-ones/
[2]https://www.404media.co/anthropic-ai-scraper-hits-ifixits-website-a-million-times-in-a-day/
[3]https://twitter.com/kwiens/status/1816128302542905620
[4]https://x.com/Carnage4Life/status/1804316030665396356
[5]https://support.anthropic.com/en/articles/8896518-does-anthropic-crawl-data-from-the-web-and-how-can-site-owners-block-the-crawler?ref=404media.co




