在AI视频生成领域,数据量级、模型参数量与训练算力的系统性提升,是催生这一强大媒体生成系统的关键基石。Meta在最新论文中着重强调了这一点,而令行业最为振奋的是:他们彻底摒弃了传统的扩散模型与扩散损失函数,转而采用Transformer作为骨干网络,并以流匹配(Flow Matching)作为训练目标。这无疑是一次架构层面的果断革新。
基于Llama3架构构建视频生成模型
具体而言,Movie Gen由视频生成与音频生成两大模块构成。
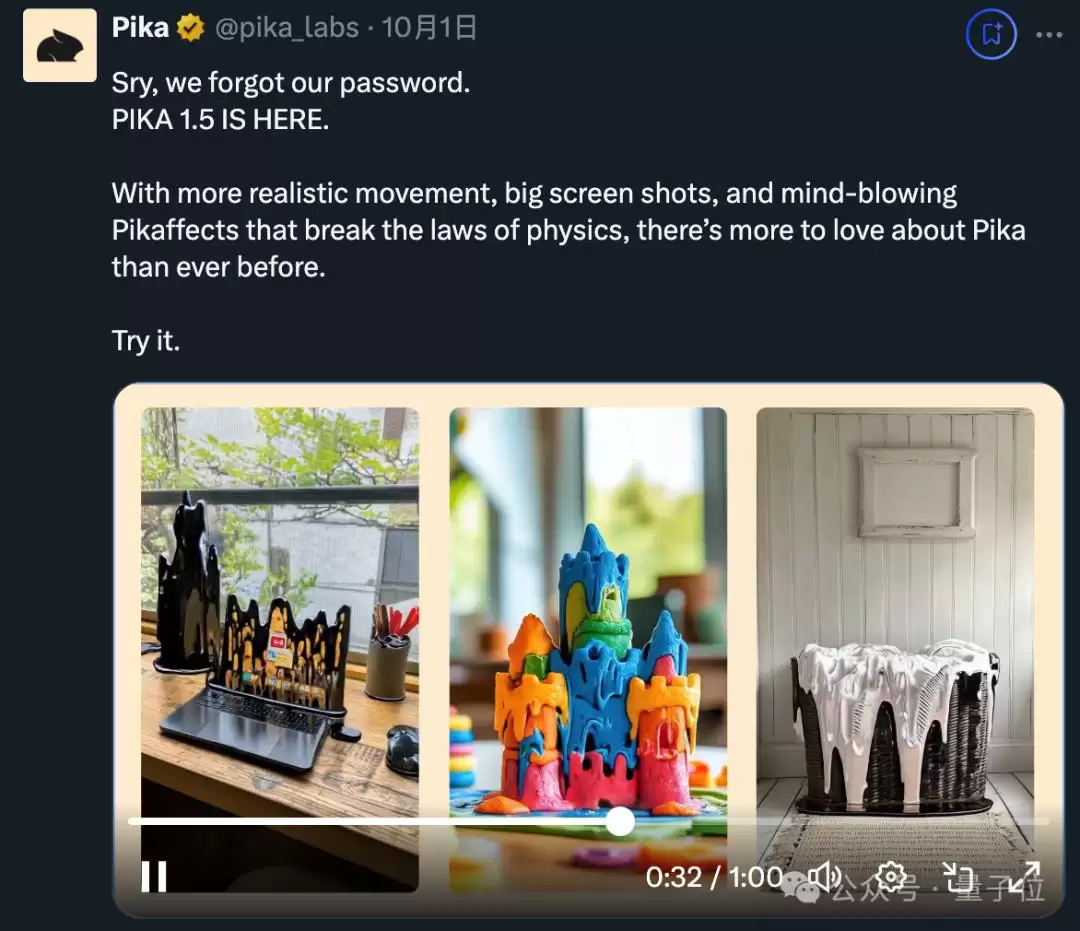
Movie Gen Video是一个拥有300亿参数的Transformer模型,它能够根据单段文本提示,直接生成16秒、每秒16帧的高清视频,相当于处理了73K个视频token。在精准视频编辑方面,该模型支持元素的添加、删除或替换,以及背景替换、风格调整等全局性修改。针对个性化视频生成,它在保持角色身份一致性与动作自然性方面,达到了业界领先水平。
Movie Gen Audio则是一个130亿参数的Transformer模型,它能接收视频输入及可选的文本提示,生成与画面同步的高保真音频。

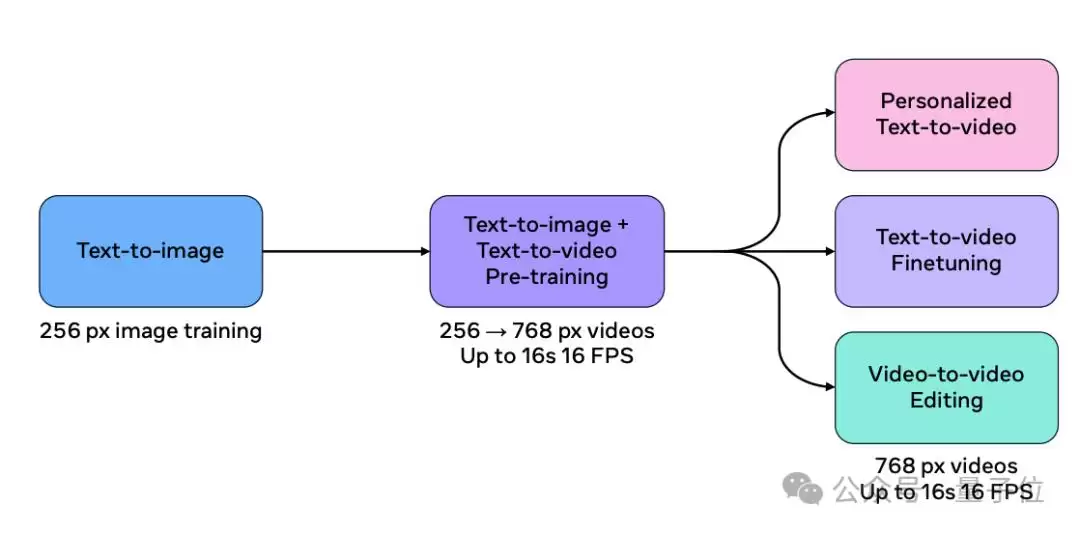
Movie Gen Video通过预训练与微调两阶段完成,其骨干网络沿用了Transformer架构,尤其是借鉴了Llama3的诸多设计理念。
预训练阶段
模型在海量的视频-文本与图像-文本数据集上进行联合训练,从而学习对视觉世界的深层理解。训练数据规模达到上亿级视频以及数十亿级图像,用以掌握运动、场景、物理规律、几何结构及音频等复杂概念。这相当于让模型先“博览群书”,全面感知视觉世界的各种可能性。
微调阶段
研究人员精心挑选了一小部分高质量视频进行有监督微调,以进一步提升生成视频的动作流畅度与美学品质。这好比是对模型进行“精修训练”,使其明确何为高质量、高顺滑度的视觉输出。
性能提升的关键一步在于引入流匹配作为训练目标,这使得视频生成在精度与细节表现上优于传统的扩散模型。简单理解:扩散模型通过逐步添加噪声再逐步去除来逼近目标,迭代步骤多、计算成本高;而流匹配则直接学习样本从噪声分布向目标数据分布转化的速度场,模型只需预测每个时间步的样本演化方向。结果便是:训练效率更高,计算成本更低,生成的视频在时间维度上拥有更佳的连续性与一致性。

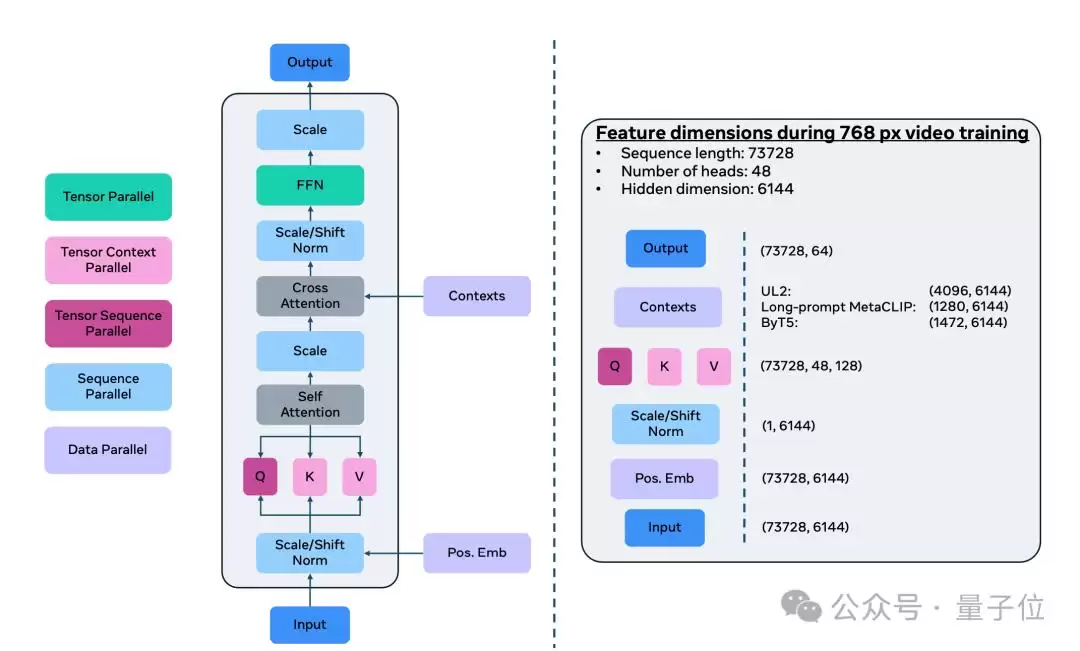
在整体架构上,首先通过时空自编码器(TAE)将像素空间中的RGB图像与视频压缩到时空潜空间,学习出一个更为紧凑的表征。接着,输入的文本提示被一系列预训练的文本编码器编码成向量,作为模型的条件信息。这里用到了多种互补的文本编码器:用于理解语义的UL2、与视觉特征对齐的Long-prompt MetaCLIP,以及对视觉文本进行字符级编码的ByT5。最后,生成模型以流匹配的目标函数进行训练,从高斯分布采样的噪声向量作为起点,结合文本条件,生成输出潜码,再经TAE解码,最终得到图像或视频输出。
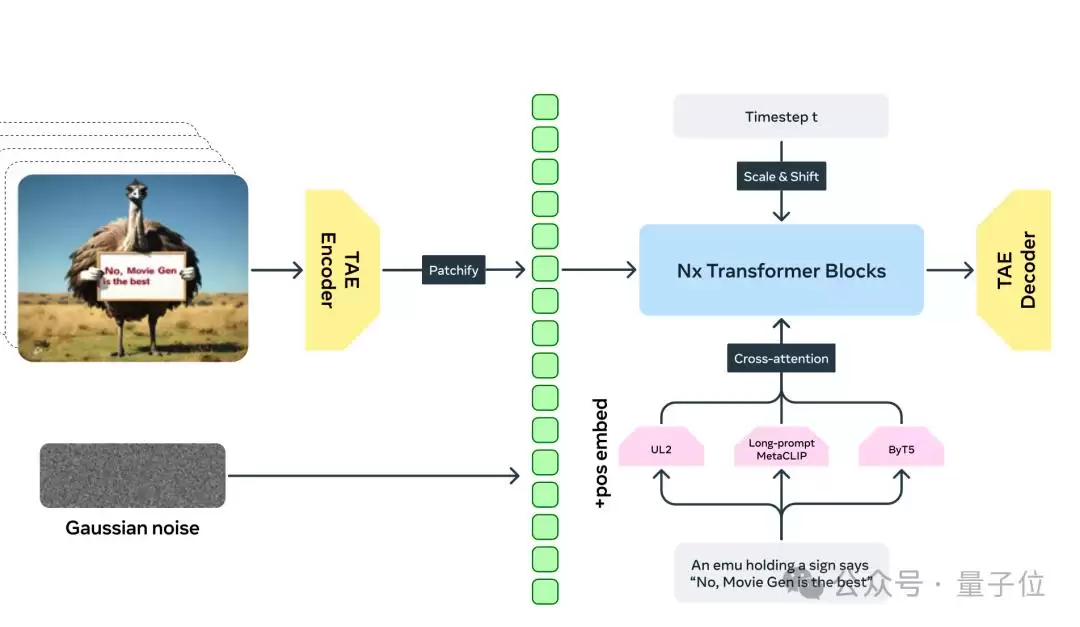
此外,Movie Gen Video在技术层面还引入了多项创新:
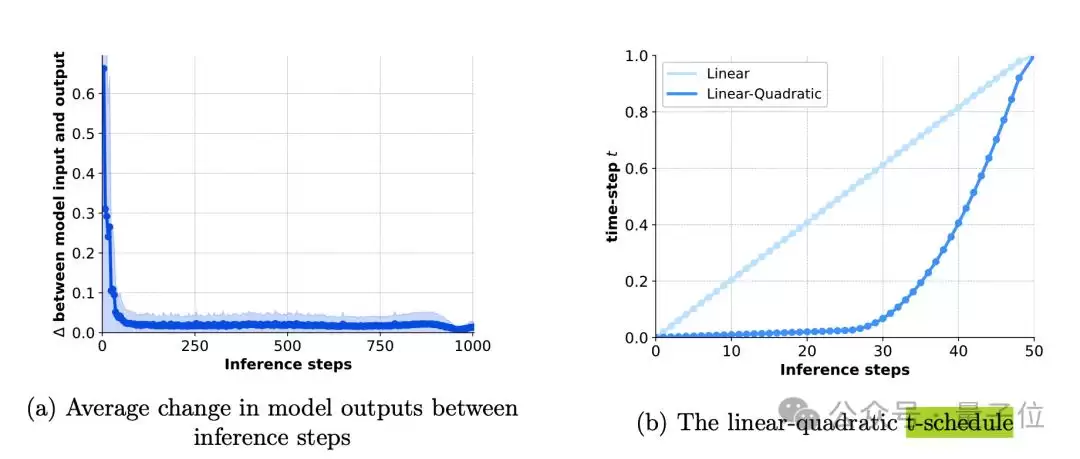
为使模型同时适配图像与视频,设计了一套因子化的可学习位置编码机制——分别对高度、宽度和时间三个维度进行编码,再相加融合。这种方式既能适配不同宽高比,又能支持任意长度的视频生成。针对推理效率问题,采用了线性-二次时间步长调度策略,仅需50步即可逼近原先1000步采样的效果,推理速度大幅提升。
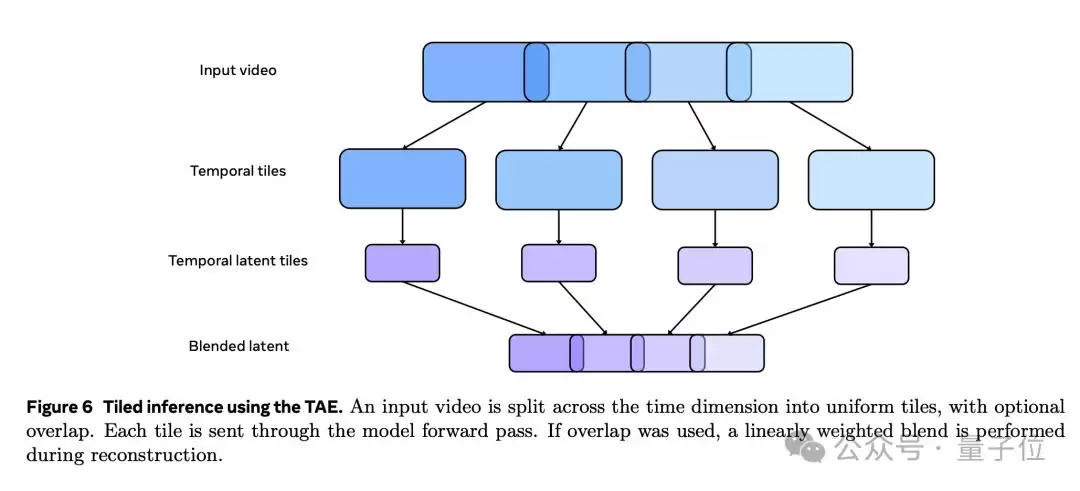
为了进一步提高生成效率,还引入了基于时间平铺的推理方法。在生成高分辨率长视频时,直接对整个视频进行编码解码会面临内存限制。时间平铺技术将输入视频在时间维度上分割成多个片段,每个片段独立编码解码后再拼接。这不仅降低了内存需求,还显著提升了推理效率。此外,解码阶段使用重叠与混合的方式消除片段边界伪影——在片段之间引入重叠区域并进行加权平均,确保视频在时间维度上平滑无缝、高度一致。
Meta还开源了多个基准测试数据集,包括Movie Gen Video Bench、Movie Gen Edit Bench和Movie Gen Audio Bench,为后续研究者提供了权威的评测工具,有助于加速整个领域的进步。这篇长达92页的论文,还介绍了更多关于架构设计、训练方法、数据管理、评估指标、并行训练与推理优化,以及音频模型的详细技术细节。

一点补充观察
AI视频生成领域近期动态频频。就在Meta发布Movie Gen之前不久,OpenAI Sora的核心主创之一Tim Brooks跳槽谷歌DeepMind,继续从事视频生成与世界模拟器方面的研究工作。
这不禁让人联想起当年谷歌迟迟未推出大模型应用,Transformer八位作者纷纷出走的情景。如今OpenAI迟迟未能正式发布Sora,其主要作者也已离开。不过,也有观点认为,Tim Brooks选择此时离开,或许意味着他在OpenAI的核心工作已经告一段落,这也引发了外界猜测:Sora另一位主创Bill Peebles至今未公开发声,背后是否另有隐情?

如今Meta发布了具备视频编辑功能的模型,再加上10月1日Pika 1.5更新主打为视频中物体添加融化、膨胀、挤压等物理特效。不难看出,AI视频生成的下半场,竞争焦点正转向AI视频编辑方向。