在LMSYS Chatbot Arena的排行榜上,GPT-4o mini的评分居然超过了Claude 3.5 Sonnet,这事儿乍看有点反直觉。但仔细琢磨一下用户们的反馈,背后的逻辑其实相当直白——在多数日常场景下,“多干点事儿”和“好好说话”确实比“思维更深入”更能赢得人心。
举个例子,有网友就发现,如果在竞技场里遇到某个模型直接拒绝回答,那在他的评判标准里,这基本等于弃权,另一个模型自然就赢了。再加上,谁的回复格式更清晰、信息更容易找到,谁就更容易拿到高分。
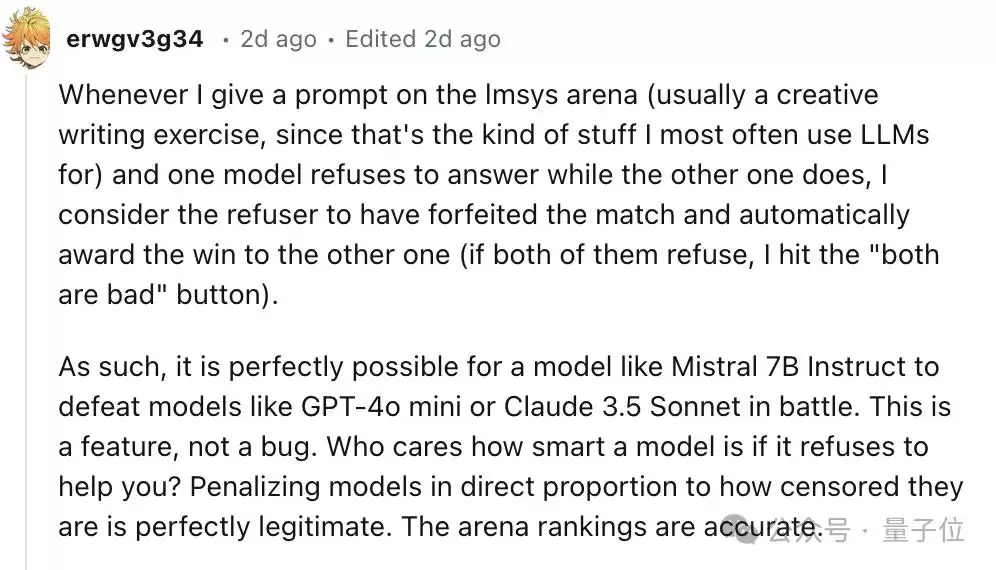
这不就跟老师阅卷一个道理么?书写工整、格式清晰,或者“多写点总没错”的卷子,总是能多捞点印象分。看来OpenAI是深谙人类的评分心理啊。事实上,在GPT-4o mini刚发布那会儿,奥特曼就已经暗示过这方面的特意优化了。
GPT-4o mini愿意接更多需求
具体来看,GPT-4o mini取胜的场景非常典型,而且往往集中在日常问题上。
情况一:Claude 3.5 Sonnet拒绝回答
先看一个提示词:
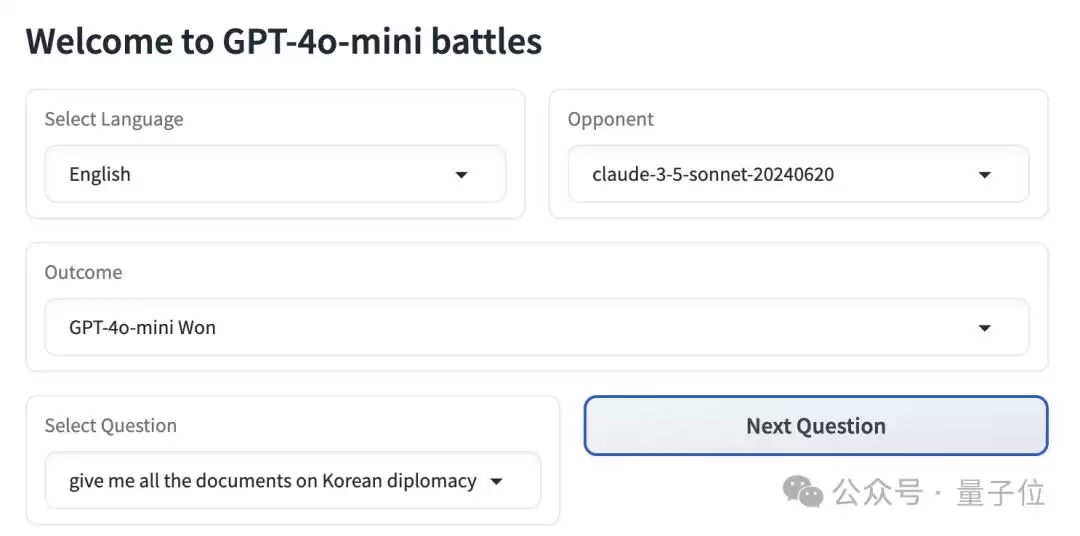
直观对比一下。Claude 3.5 Sonnet的回答非常简短,也没有使用加粗等格式。GPT-4o mini的答案长度则是它的2倍。

具体回答内容上,Claude上来先道歉,表示自己作为一个AI大模型,无法获取相关文件,所以提供了一些获取资料的渠道,最后还提醒用户这些文件可能是机密,建议跟相关机构联系。

而GPT-4o mini完全没有说“不知道”,而是从公开资料中搜集了从古至今相关的韩国外交文件,并告诉用户从学术期刊、书籍专著等渠道可以搜集资料。

最后它还表示,想要彻底了解韩国外交文件必须查阅多种资料,并且欢迎用户继续提问。

情况二:细节差异
再看另一个提示词:

在这个问题上,两个模型都答对了。但GPT-4o mini给出了更多细节,还举了具体例子,而Claude的回答在可读性和信息量上就显得有些单薄。
情况三:格式呈现差异
再来一个例子:
这次,两个模型回答的内容基本一样,都解释了这段话的讽刺意味。但GPT-4o mini的呈现方式一目了然——它把整个回答分成了“初步结论”、“分析回答”、“幽默原因”和“总结”四个部分,还加上了小标题和加粗格式。

这几个例子其实也揭示了Chatbot Arena的评分规则:大部分用户问的问题都很日常,不是什么复杂的数学、推理或编程难题。这些问题基本都在大模型的“射程”之内,大家都能回答。在这种情况下,“不拒绝”和“格式漂亮”就成了影响用户判断的关键因素。
有人打了个比方:Claude 3.5 Sonnet像一个聪明但严谨的人,严格按规则办事;而GPT-4o mini则像一个讨人喜欢、愿意多干点活、总能接受不同需求的人。

比如有用户举例,Claude拒绝为他扮演角色,而ChatGPT很乐意。
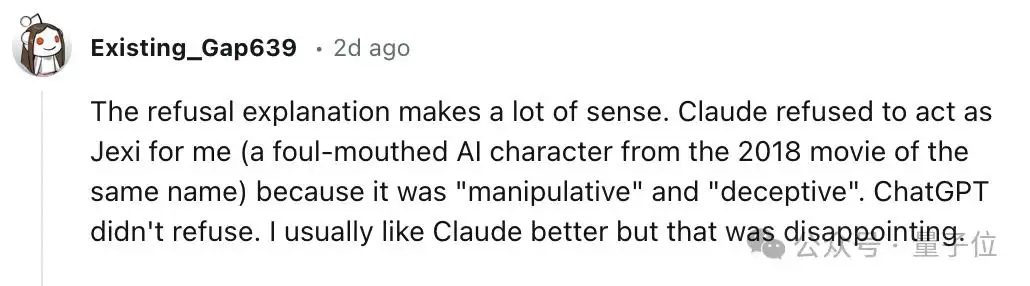
当然,这个现象也引发了一些反思。有人直言:看到大模型因为“道德感太强”而分数不高,反而挺高兴的。之前为了用那些道德边界高的模型(比如Claude、Gemini),每次都要精心设计提示词,非常心累。
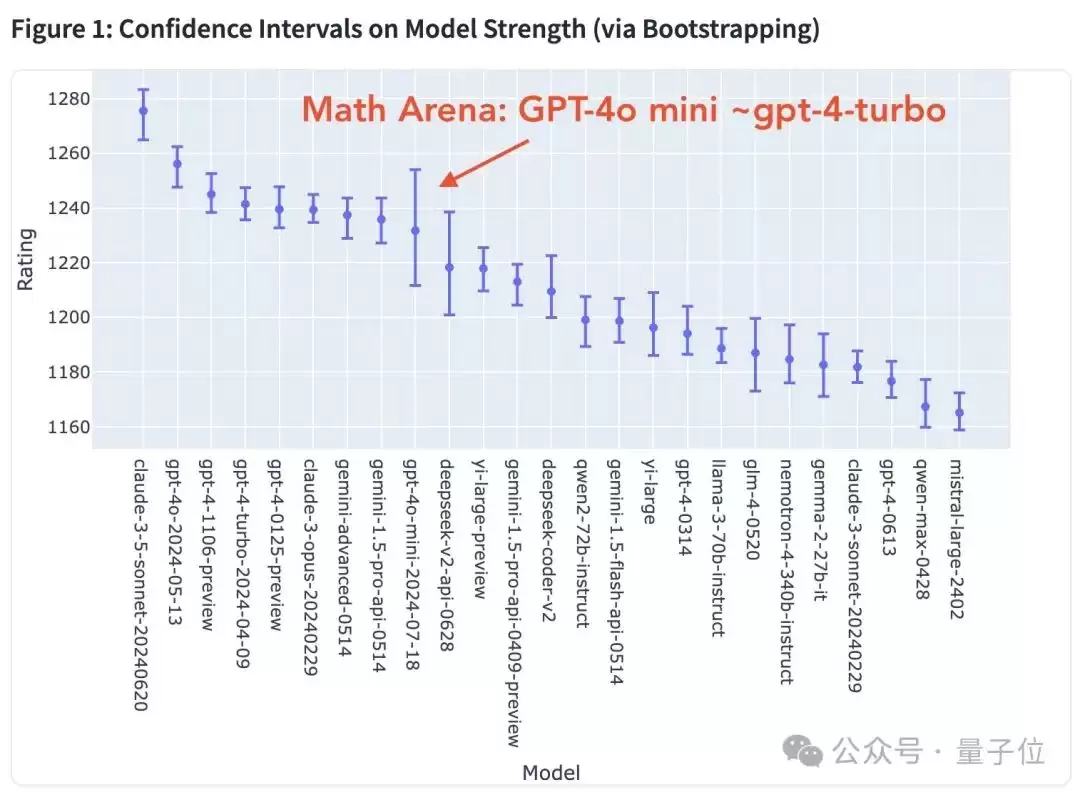
不过,GPT-4o mini也并非没有短板。在数学任务上,它的表现明显差了一截。记忆力也不如Claude,过一会儿就会忘记上下文。还有用户指出,Claude一下就能修好的bug,GPT-4o可能要反复沟通20次、耗时1小时。

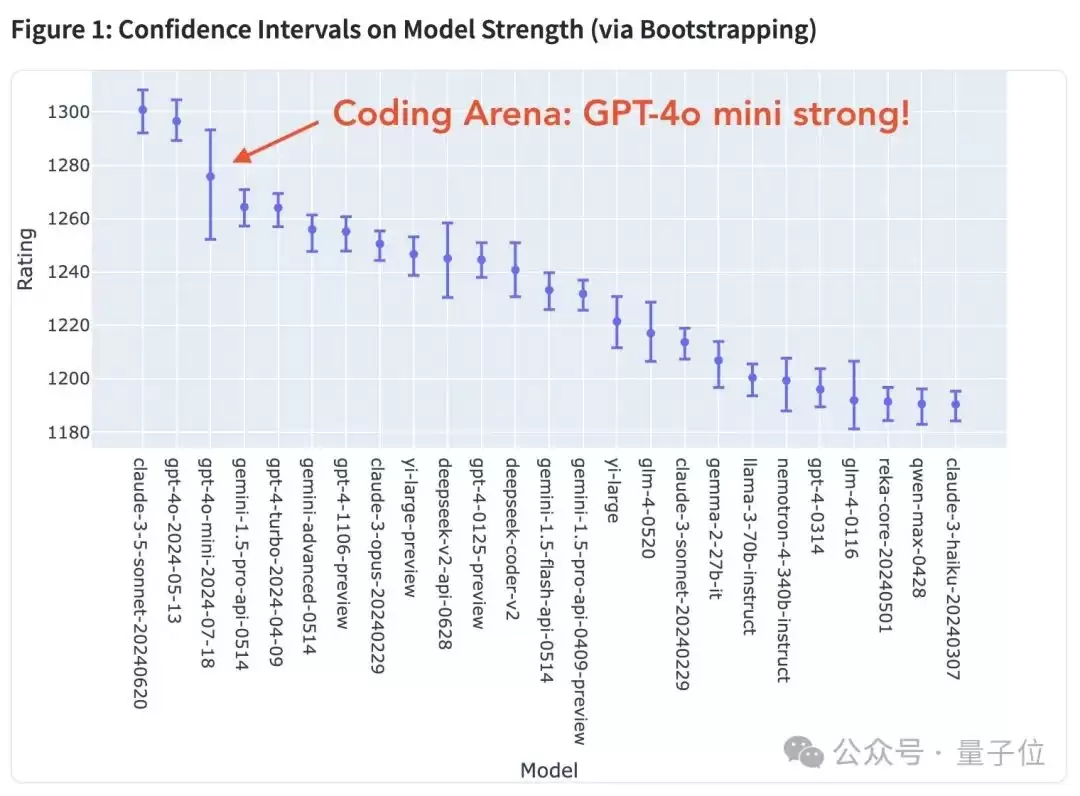
即便如此,在Arena的评分榜单上,GPT-4o mini依然稳居前列。
用过这两个模型的朋友,你们在实际体验中感觉各自的差距在哪?欢迎在评论区聊聊。




