咳嗽声中藏着的健康密码
根据世界卫生组织2021年发布的统计数据,全球十大主要死因累计导致3900万人死亡,占当年全球总死亡人数(6800万)的57%。这些致命威胁的背后,最突出的“元凶”主要集中于两大类疾病:心血管疾病(如缺血性心脏病、中风)和呼吸系统疾病(如肺结核、慢性阻塞性肺病、下呼吸道感染)。
值得关注的是,呼吸系统疾病引发的咳嗽声或呼吸音,实际上暗藏着大量关于我们身体健康状况的线索。临床医生早已学会利用带有“喘息”特征的咳嗽声来诊断百日咳,甚至能通过患者临终前的呼吸声音监测急性心血管事件的发生。
那么问题来了——在人工智能时代,我们能否借助技术的力量,从这些声音数据中提取健康信号,从而更早、更精准地掌握自己的身体状态?
来自谷歌、赞比亚传染病研究中心结核病科的研究团队,在这个方向上迈出了至关重要的一步。他们合作推出了一款名为HeAR(Health Acoustic Representations)的生物声学基础模型,简单来说,就是让机器学会“听懂”人类声音,并从中捕捉疾病的早期预警信号。相关研究论文已发表在预印本网站arXiv上。
为了确保HeAR的性能,研究团队从海量、多样化且经过去识别化的数据集中,精心挑选了3亿个音频数据用于模型训练,其中特别使用了大约1亿个咳嗽声音专门训练“咳嗽模型”。
最终成果相当可观:HeAR能够精准识别与健康相关声音中的模式,在广泛的测试任务中平均排名显著高于其他模型,并且具备跨麦克风泛化能力——也就是说,不会因为录音设备不同而影响识别效果。更为难得的是,利用HeAR训练的模型只需更少的数据就能达到高性能,这在医疗研究领域极其宝贵,毕竟医疗数据往往稀缺且珍贵。
StopTB Partnership 数字健康专家Zhi Zhen Qin评价道:“像HeAR这样的解决方案,将使人工智能驱动的声学分析在肺结核筛查和检测中发挥巨大作用,为最需要的人群提供一种影响更小、更易获取的工具。”
研究团队希望未来能进一步推进在肺结核、胸部、肺部及其他疾病领域的诊断工具和监测方案。
事实上,印度呼吸健康公司Salcit Technologies已经基于HeAR开发了一款名为Swaasa的产品,通过AI分析咳嗽声音来评估肺部健康状况。目前,他们正在探索如何利用HeAR进一步扩展其生物声学AI模型的能力。
一声咳嗽,即可检测疾病
HeAR系统由三个核心部分构成。通过自我监督学习,它利用大量未标注的音频数据学习通用的音频表示,并能迁移应用到各种健康声学任务中。通俗地说,就是让机器在没有标准答案的情况下,自主学会从声音中寻找规律。
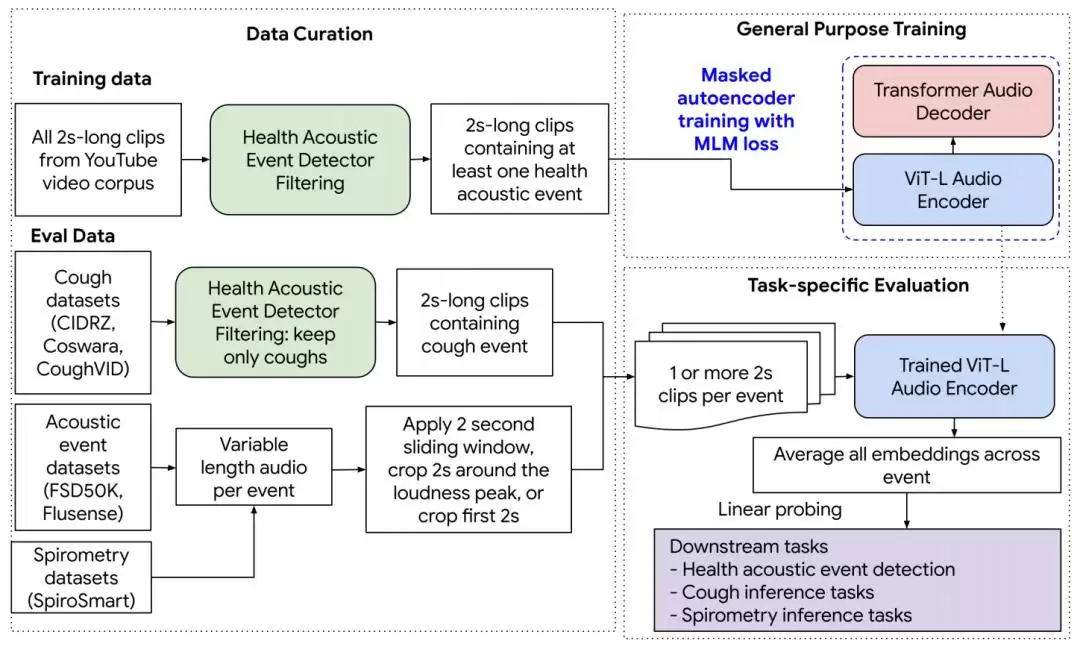
图|HeAR 系统概况
在数据采集环节,研究团队采用了一个健康声学事件检测器。该检测器本质上是一个多标签分类卷积神经网络(CNN),用于识别2秒音频片段中是否存在6种非语音健康声学事件:咳嗽、婴儿咳嗽、呼吸、清嗓子、笑声和说话。训练数据来源于FSD50K和FluSense数据集,通过音频片段中的标签(如“咳嗽”、“打喷嚏”、“呼吸”等)进行标注。
论文使用了两个数据集:第一部分是从30亿个公共非版权YouTube视频中提取的2秒音频片段,共计3.133亿个片段,相当于约174000小时的音频。这些片段均经过了健康声学事件检测器的筛选。第二部分由赞比亚传染病研究中心提供,包含来自599名疑似肺结核患者的咳嗽音频录音以及胸部X光片。
研究团队采用掩码自编码器,在包含3.13亿个两秒钟长音频片段的大型数据集上进行训练。通过线性探测,在跨越6个数据集的33个健康声学任务基准上,HeAR在所有健康音频嵌入模型中的表现达到了当前最佳(SOTA)。

图|HeAR 在33个健康音频任务中取得了最高的平均排名(MRR = 0.708),全面超越了其他基线模型。
在FSD50K和FluSense数据集上,HeAR的表现同样优于其他模型,特别是在FSD50K训练的模型中排名第二。
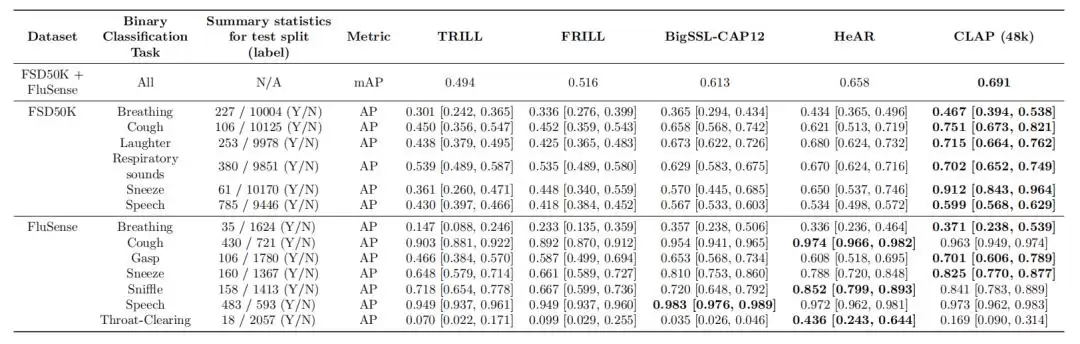
图|健康声学事件检测任务在FSD50K和FluSense数据集上的性能比较。
在14个咳嗽推理任务中,HeAR在其中的10个任务上表现优于基线模型,涵盖人口统计和生活方式判断。在TB和CXR任务中,它的表现与最佳模型旗鼓相当。
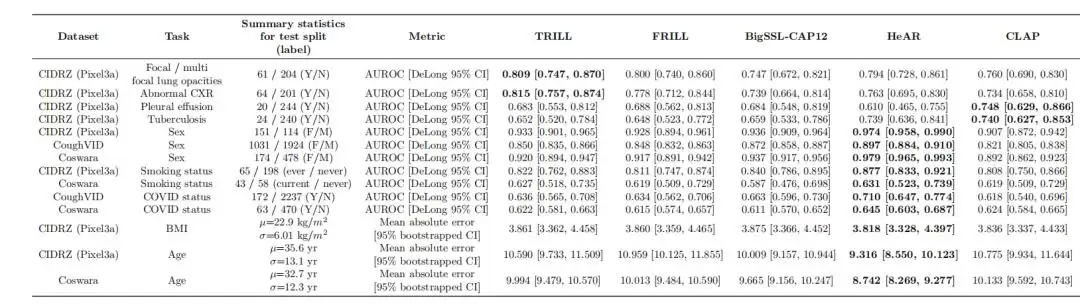
图|咳嗽推理任务的性能比较。
在SpiroSmart数据集上,HeAR在5个肺功能测试任务中的4个以及性别分类任务中表现优于基线模型。
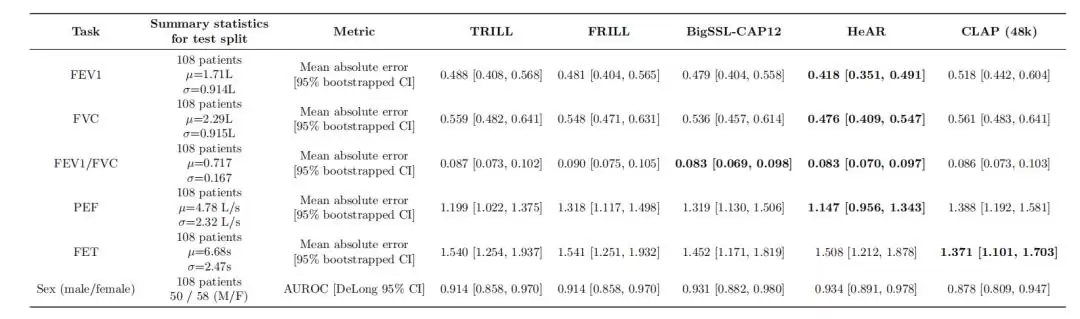
图|肺功能测试任务的性能比较。
值得一提的是,HeAR在CIDRZ数据集上的表现不受不同录音设备的影响,对不同设备具有鲁棒性。此外,即使训练数据较少,它同样能取得良好性能——在标注数据稀缺的医疗研究中,这一点极具优势。
当然,HeAR也存在一定局限性。例如,线性探测方式难以完全发挥模型的潜在性能;部分数据集规模较小且存在类别不平衡问题;另外,HeAR这类模型体量较大,在手机等移动设备上运行仍有难度。
研究团队表示,未来可以考虑通过微调模型或加入更多特征来提升性能,收集更多数据并改进数据预处理方法,也可以研究模型压缩和量化技术,使模型能够在本地设备上运行。
AI辅助诊断疾病,大有可为
从辅助医生到独立诊断疾病,人工智能在医疗领域的应用日益广泛,潜力也在不断被挖掘。
今年6月,伦敦帝国理工学院和剑桥大学的研究团队训练了AI模型EMethylNET,通过观察DNA甲基化模式,从非癌组织中识别出13种不同类型的癌症(包括乳腺癌、肝癌、肺癌和前列腺癌等),准确率高达98.2%。
7月,波士顿大学研究团队及其合作者开发的AI工具,有望同时诊断10种不同类型的痴呆症,将神经科医生的诊断准确率提升了26%以上。
最近,针对儿童的“隐形杀手”自闭症,AI也取得了突破。卡罗林斯卡学院研究团队开发的多模态数据分析AI模型,不仅能在患儿12个月左右时发现早期迹象,对两岁以下儿童识别的准确率达到80.5%,而且整个过程只需要相对有限的信息。
可以预见,在不久的将来,AI将帮助人类诊断更多疾病,为医疗健康领域带来更多可能性。




