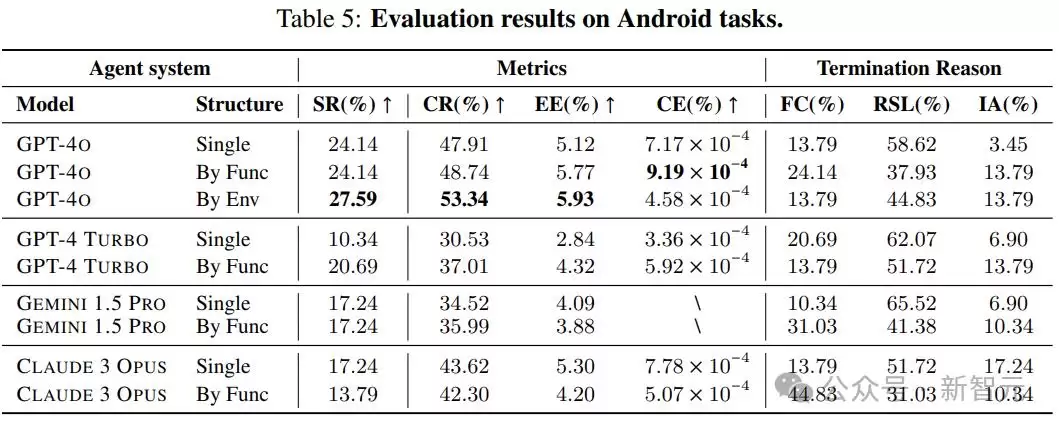
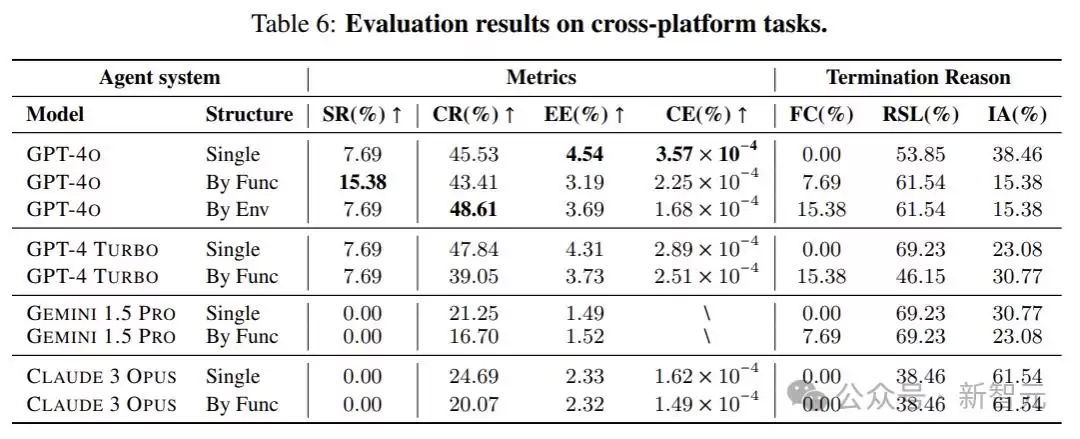
Crab框架近期发布了全新基准测试——Crab Benchmark-v0,旨在评估数字设备上执行任务的智能体(Agent)性能。该基准测试覆盖Android与Ubuntu两大主流平台,为行业提供了可靠的测试环境。测试集包含100个真实世界任务,涵盖单平台及跨平台多个难度等级。
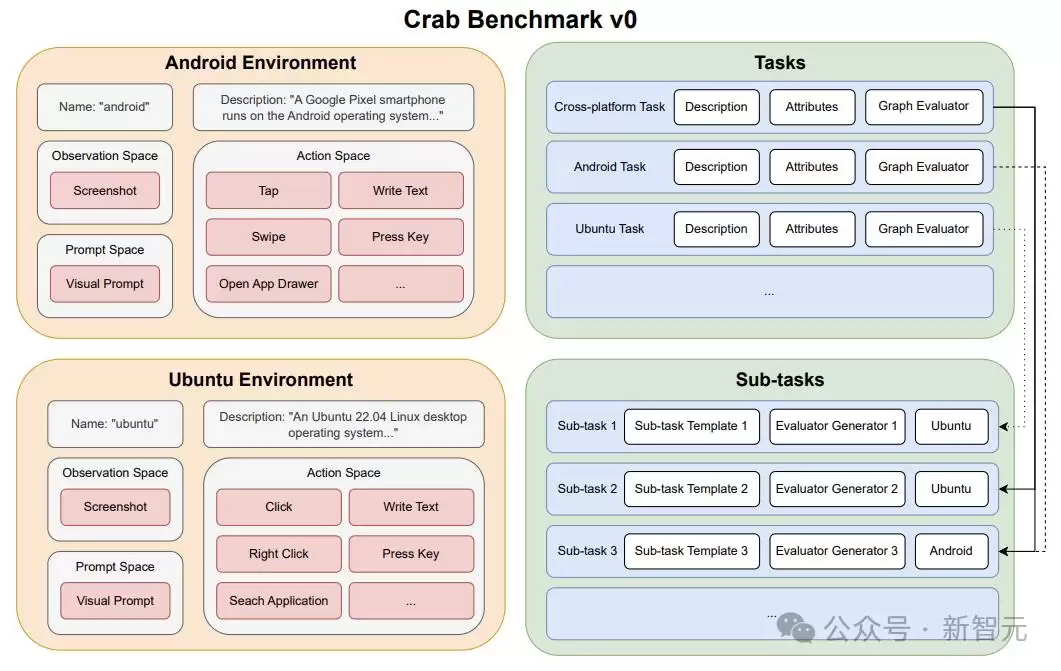
这些任务并非实验室玩具,而是聚焦于用户日常真实使用的应用与工具:日历、电子邮件、地图、网络浏览器、终端,以及智能手机与台式机之间的常见交互,具有极高的实用价值。
框架
设想一个智能体(Agent)在数字设备(如台式机)上自主执行任务:设备通过鼠标和键盘获取输入,屏幕作为输出窗口供人类观察其状态。在学术上,研究者将此类设备定义为“平台”,并形式化为无奖励的部分可观测马尔可夫决策过程(POMDP),以元组(S,A,T,O)表示——S为状态空间,A为动作空间,T为转移函数,O为观测空间。
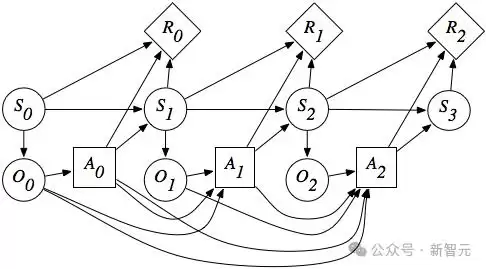
在实际场景中,多设备协同工作更为常见。因此,可将多个平台组合为集合,每个平台拥有各自的形式化表达。跨平台操作的任务可定义为(M,I,R):M代表平台集合,I为自然语言指令形式的任务目标,R为奖励函数。
Agent系统的内部运作机制清晰:可由单个Agent负责全流程的规划、推理与执行,也可由多个Agent协作完成。系统保留对话历史记录,并依赖预设的系统提示指令运行。
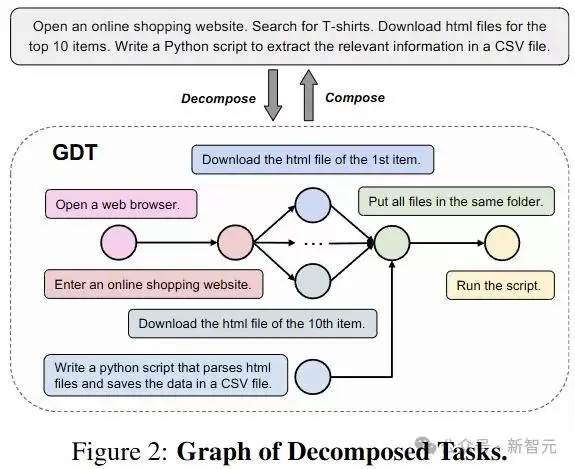
将复杂任务分解为更简单的子任务,是提升Agent系统完成高难度任务效率的关键策略。研究者将此思路引入基准测试,提出“分解任务图”(GDT)概念:利用有向无环图(DAG)结构分解复杂任务。图中每个节点代表一个子任务,形式化为(m,i,r),其中m指定执行平台,i为自然语言指令,r为奖励函数——该函数评估平台状态并输出布尔值以判断子任务是否完成。图中的边定义了子任务之间的执行顺序。
跨平台
与仅运行于单一平台的任务相比,跨平台任务具有三大显著优势。
第一,真实模拟人类日常工作场景——人们经常同时使用手机和电脑。第二,跨平台任务要求Agent在设备间完成复杂的消息处理与传递,包括规划行动、为每个平台生成输出,并记住需在不同设备间流转的信息。这考验了Agent对现实世界的高层次理解能力与复杂任务解决能力。
第三,多Agent系统在应对复杂任务方面已展现出有效性,而跨平台任务天然适配此类架构——不同Agent可基于各自平台的观测空间、动作空间及专业知识进行分工协作。
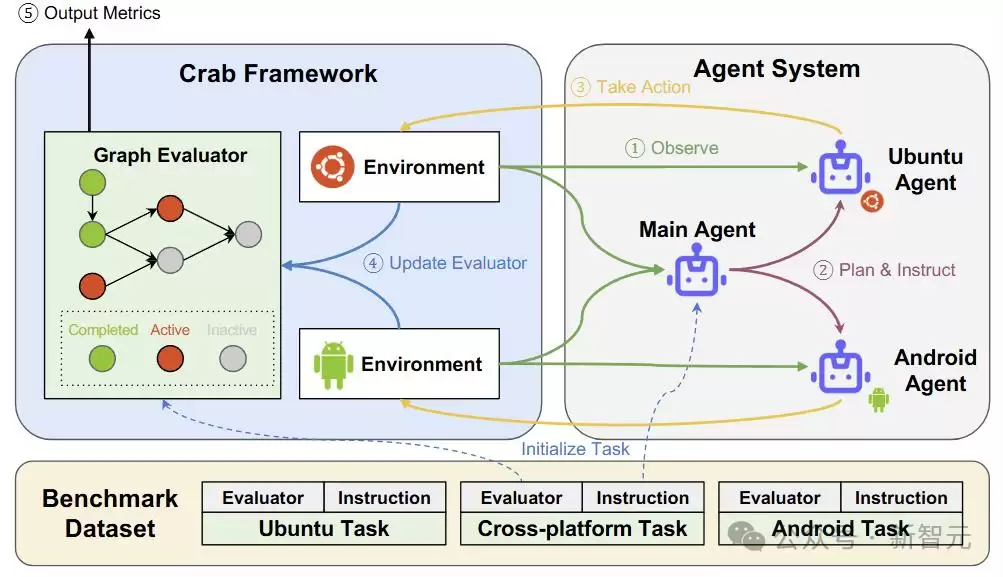
Crab通过统一接口使Agent能在所有平台上执行操作。每个动作由名称、所属平台、功能描述及参数定义。Agent每回合需提供动作名称、参数和目标平台,Crab负责将动作转换为实际功能,并通过网络路由至物理设备或虚拟设备执行。
图评估器
评估大语言模型作为Agent的能力时,多数基准测试仅关注操作结束后平台的最终状态——只要最终结果正确即视为成功。然而,仅判定最终目标成功与否显然不够公平,正如考试中虽然大题不会,但写出“解”字也应酌情给分。
另一种方法是轨迹匹配,即将Agent的操作序列与预设标准操作序列进行对比。该方法同样存在缺陷:现实世界中同一任务常有多条正确执行路径,例如复制文件既可通过文件管理器完成,也可通过命令行实现,两者均为正确。
于是,研究者提出了一种更智能的方案:采用与平台状态同步的图评估器。该评估器基于子任务完成的当前状态,实时追踪Agent的进展。除传统成功率(SR,要求所有子任务全部完成才算成功)外,还引入三个新指标用于衡量Agent的绩效与效率。
实验选取了四种满足条件的多模态模型:GPT-4o、GPT-4 Turbo、Gemini 1.5 Pro和Claude 3 Opus。部分结果如下: