为什么主流的大模型公司纷纷转向闭源?答案其实并不复杂——因为强大。OpenAI的故事就是个典型:2019年的GPT-2还是开源的,到了GPT-3.5、GPT-4o阶段就彻底闭源了。原因很简单,当自家大模型达到“一览众山小”的状态时,闭源显然是利益最大化的选择——否则ChatGPT Plus哪能卖得那么好?同样的道理也适用于Anthropic的Claude-3,它的产品力已经强到让用户觉得不可替代。
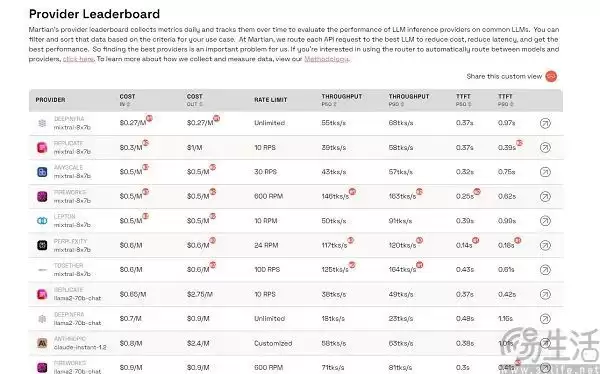
至于说开源大模型推理成本更高,这个论点其实站不住脚。决定推理成本的关键因素从来不是模型本身,而是云服务提供商。看看之前国产大模型的价格战,背后实际上是腾讯、阿里、华&为等云厂商新一轮价格战的投影。更关键的是,在Martian的Provider Leaderboard(推理成本排行榜)上,开源模型和闭源模型的表现伯仲之间,统计学层面根本拉不开差距。
开源与闭源的路线之争,还集中体现在对开发者的争夺上。国产大模型“不服跑个分”的时代已经翻篇了,现在大家追求的是AI应用场景落地。这时候就需要第三方开发者群策群力,就像当年Android和iOS的竞争一样。彼时苹果iOS率先起步,谷歌Android作为追赶者;如今国内的百度、海外的OpenAI作为AI先行者都选择了闭源,而拥抱开源的阿里、Meta则在后面奋起直追。
众所周知,iOS和Android在移动操作系统市场的份额是2:8,但苹果App Store每年贡献的收入却比Google Play更高。有了苹果的珠玉在前,只要这轮AIGC能复刻移动互联网的成功,坚持闭源路线的厂商就有资格复刻苹果的辉煌。同理,选择开源路线的厂商则在效仿Android的路径。

最后放一个小彩蛋。关于开源模型是不是智商税这个问题,有人曾咨询文心一言的意见。它的回答很有智慧:“它(智商税)过于简化了开源模型和闭源模型之间的复杂关系。”




