6月30日,美团正式发布了新一代基础大模型——LongCat-2.0。值得强调的是,这并非一款普通模型:它是业界首个完全基于国产算力完成训练与推理全流程的万亿参数大模型。一句话概括,含金量极高。
具体来看,LongCat-2.0采用MoE架构设计,参数总量高达1.6万亿,每个Token实际激活约480亿参数。它原生支持1M超长上下文,意味着能够一次性处理百万字级别的输入内容。在与Claude Code、OpenClaw、Hermes等主流Harness的适配测试中,该模型在编码任务上的表现相当出色。
更值得关注的是,今年4月底,美团曾放出LongCat-2.0的Preview版本,并以匿名方式接入了全球最大的大模型API路由平台——OpenRouter。截至6月底,这个Preview版本的总调用量已攀升至全球前三。
从OpenRouter的数据来看,在Hermes、Claude Code、OpenClaw等Agent场景下,LongCat-2.0-Preview的月调用量分别位列全球第一、第二和第三。其中在Claude Code上的月调用量仅次于Claude Opus 4.8,成为全球开发者最欢迎的免费模型之一。
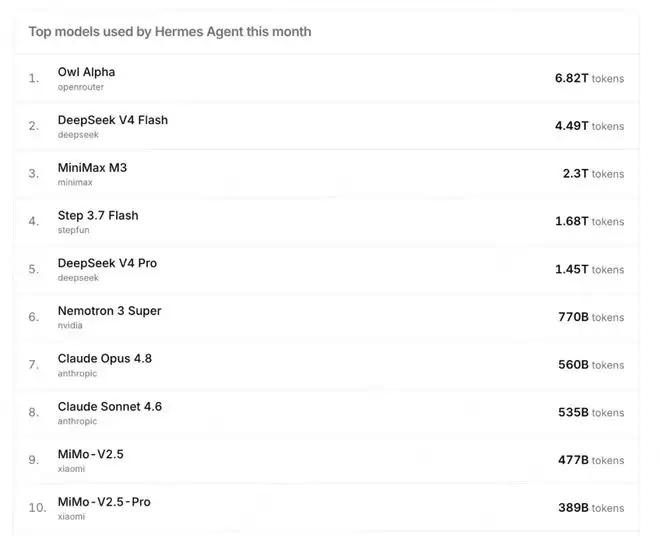
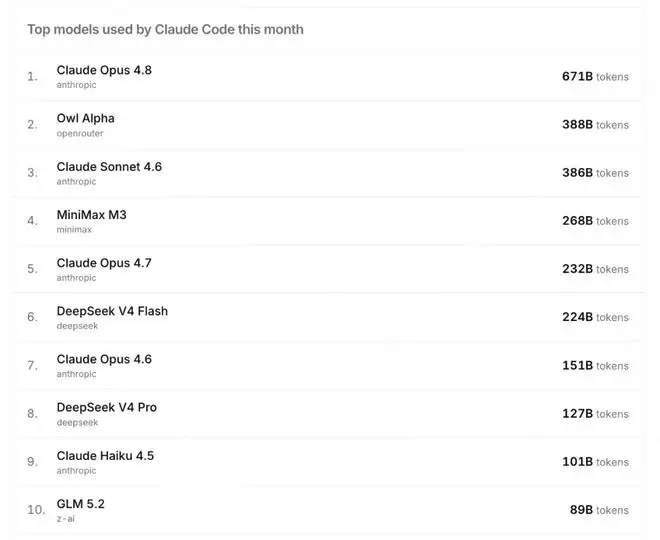
社区反馈显示,在工具调用、复杂指令执行等Agent核心能力上,LongCat-2.0-Preview接近Claude Opus 4.6,略逊于最新的Claude Opus 4.8。不过在国产大模型中,它已经稳居顶尖梯队。
技术层面同样带来不少惊喜。相关报告指出,LongCat-2.0引入了ScMoE跨层快捷连接架构、零计算专家机制、Ngram Embedding增强等多项原创设计。其中零计算专家机制堪称行业首创——它能够实现Token级的动态计算预算,让复杂Token激活更多专家,简单Token则节约算力,相当于为模型安装了一个“智能节能开关”。
再来聊聊国产算力这个硬核话题。作为首个“全国产”万亿参数大模型,LongCat-2.0全程在国产算力上完成训练,峰值规模超过5万张国产算力卡,创下了国产算力上完成的最大训练任务纪录。
据悉,从2024年开始,美团就与国产算力厂商携手推进“模芯协同”研发,从早期的小规模验证到超大规模稳定训练,逐步攻克了万卡级容错恢复、NPU确定性计算、算力利用率提升等核心难题。整个实践表明,尽管国产算力卡目前仍落后于全球顶尖水平,但计算正确性和精度已经足以满足需求,甚至在局部略优——这意味着大规模国产训练这条路已经走通。
更值得一提的是,得益于算力优化与技术突破的综合作用,LongCat-2.0的训练与推理成本消耗低于全球其他万亿参数级别的大模型。作为回馈,LongCat团队近日宣布,将在多个平台同步开源Infra框架、推理引擎、模型参数等核心技术,让全球开发者社区共享这一成果。




