美团正式迈出通向"世界模型"的关键第一步,并计划借助这一创新更有效地衔接"原子世界"与"比特世界"。 
▲美团发布并开源LongCat-Video视频生成模型,正式启动"世界模型"探索之路(资料图)
10月27日,美团LongCat团队正式发布并开源了LongCat-Video视频生成模型。该模型通过统一架构,在文生视频、图生视频等基础任务上达到开源领域SOTA(最先进水平)标准,并基于原生视频续写任务进行预训练,实现了分钟级长视频的连贯生成。该技术有效保障了跨帧时序一致性与物理运动合理性,在长视频生成领域展现出显著优势。
近年来,"世界模型"(World Model)因其能让人工智能真正理解、预测乃至重构现实世界,被业界视为通往下一代智能的核心引擎。作为能够建模物理规律、时空演化与场景逻辑的智能系统,"世界模型"赋予人工智能"看见"世界运行本质的能力。而视频生成模型有望成为构建世界模型的关键路径——通过视频生成任务压缩几何、语义、物理等多形式知识,人工智能得以在数字空间中模拟、推演乃至预演真实世界的运行。正因如此,美团LongCat团队认为,此次发布的视频生成模型,正是探索"世界模型"迈出的实质性第一步。未来,凭借精准重构真实世界运行状态的能力,LongCat模型还将融入公司近年来持续投入的自动驾驶、具身智能等深度交互业务场景中,成为公司更好连接"比特世界"和"原子世界"的技术基础。

▲LongCat-Video视频生成模型推理速度提升至10.1倍(资料图)
具体来看,此次开源模型的技术报告显示,作为基于Diffusion Transformer(DiT)架构的多功能统一视频生成基座,LongCat-Video创新性通过"条件帧数量"实现任务区分,原生支持三大核心任务:文生视频无需条件帧、图生视频输入1帧参考图、视频续写依托多帧前序内容,且无需额外模型适配,形成"文生/图生/视频续写"完整任务闭环。
此外,依托视频续写任务预训练,新模型可稳定输出5分钟级别的长视频,且无质量损失,达到行业顶尖水平。同时,从根源规避色彩漂移、画质降解、动作断裂等行业痛点,保障跨帧时序一致性与物理运动合理性,适配数字人、具身智能、世界模型等需要长时序动态模拟的场景需求。模型还结合块稀疏注意力(BSA)与条件token缓存机制,大幅降低长视频推理冗余——即使处理93帧及以上长序列,仍能兼顾效率与生成质量稳定,突破长视频生成"时长与质量不可兼得"的瓶颈。
针对高分辨率、高帧率视频生成的计算瓶颈,LongCat-Video通过"二阶段粗到精生成(C2F)+块稀疏注意力(BSA)+模型蒸馏"三重优化,视频推理速度提升至10.1倍,实现效率与质量的最优平衡。
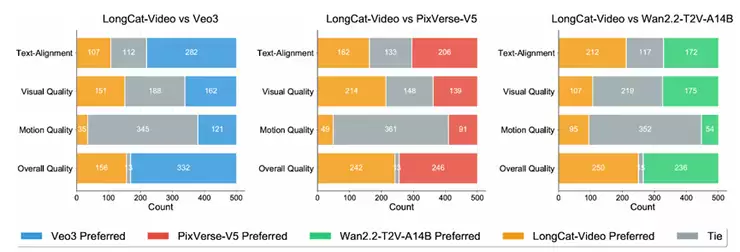
▲LongCat-Video视频生成模型在文生、图生视频基础任务上达到开源SOTA(资料图)
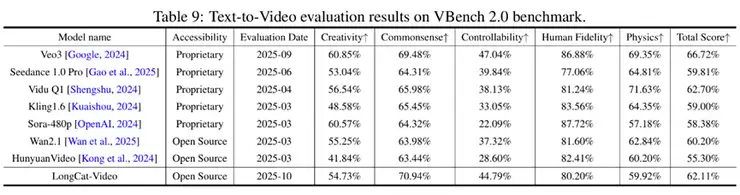
技术报告还称,LongCat-Video的模型评估围绕内部基准测试和公开基准测试展开,覆盖Text-to-Video(文本生成视频)、Image-to-Video(图像生成视频)两大核心任务,从多维度(文本对齐、图像对齐、视觉质量、运动质量、整体质量)验证模型性能:1360亿参数的视频生成基座模型,在文生视频、图生视频两大核心任务中,综合性能均达到当前开源领域SOTA级别;通过文本-视频对齐、视觉质量、运动质量、整体质量四大维度评估,其性能在文本对齐度、运动连贯性等关键指标上展现显著优势;在VBench等公开基准测试中,LongCat-Video在参评模型中整体表现优异。




