12月18日消息,据“龙猫LongCat”公众号今晚发布的消息,美团LongCat团队正式推出并开源了SOTA级别虚拟人视频生成模型——LongCat-Video-Avatar。
该模型基于LongCat-Video底座打造,延续了“一个模型支持多任务”的核心设计理念,原生支持Audio-Text-to-Video、Audio-Text-Image-to-Video及视频续写等核心功能。同时,其底层架构实现了全面升级,在动作拟真度、长视频稳定性与身份一致性这三大维度上取得了显著突破。

根据最新介绍,该模型具备以下技术亮点。
“告别僵硬,迎接鲜活”:不仅能够精准驱动口型,还能同步指挥眼神、表情与肢体动作,实现更加丰富饱满的情感表达。
连“不说话”的时候,都很像人:美团通过Disentangled Unconditional Guidance(解耦无条件引导)训练方法,让模型理解了“静音”不等于“死机”。在说话的间隙,虚拟人也能像人类一样自然地眨眼、调整坐姿或是放松肩颈。
据介绍,LongCat-Video-Avatar因此成为首个同时支持文字、图片、视频三种生成模式的“全能选手”,虚拟人从此拥有了“真正的生命力”。
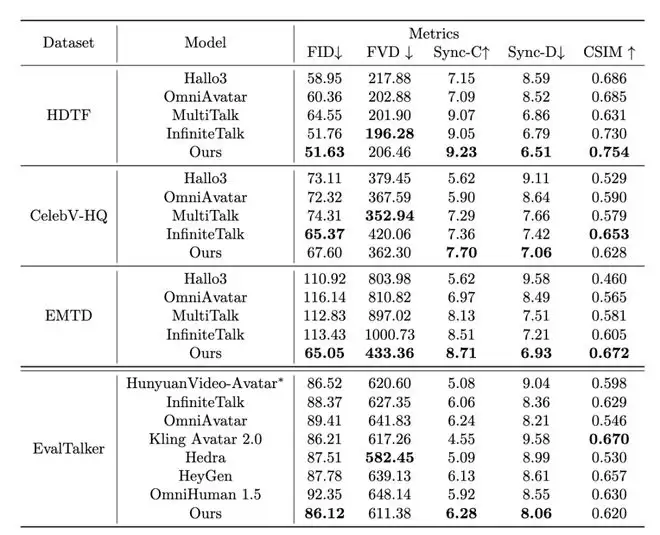
在HDTF、CelebV-HQ、EMTD和EvalTalker等权威公开数据集上的定量评测表明,LongCat-Video-Avatar在多项核心指标上均达到了SOTA领先水平。
IT之家附项目地址:
GitHub: https://github.com/meituan-longcat/LongCat-VideoHugging Face: https://huggingface.co/meituan-longcat/LongCat-Video-AvatarProject: https://meigen-ai.github.io/LongCat-Video-Avatar/




