现代数据管理正经历一场悄然变革——元数据从幕后走向台前。当文件不再仅是字节集合,而是自带身份标识与上下文信息时,数据便不再是静态的存储负担,而成为驱动决策、加速创新的战略性资产。这并非未来幻想,而是当下即可实现的能力。
核心要点:智能元数据使文件存储具备对象存储般的“智慧”。通过Dell PowerScale与Diskover Data的协同,企业可实现数据的自动发现、智能分类与精细化管理。该整合本质上将非结构化数据从“沉睡资产”激活为“流动智能”,不仅降低成本、提升效率,更为生命科学等关键领域的研究提供直接支撑。
在数据驱动时代,理解数据早已是必选项。元数据——即附着于文件之上的上下文信息,如内容摘要、来源、用途——正是开启数据理解之门的钥匙。对象存储之所以备受青睐,很大程度上在于其允许将任意键/值元数据直接绑定到对象上。这一能力的价值无可估量:掌握数据内容,是企业实现现代化数据管理的根基。
当元数据与数据紧密绑定时,数据发现、编目及自动化业务流程变得极为便捷。数据自带“身份证”,无论被迁移到哪个存储层级或由谁访问,都能被即时识别与轻松管理。这背后的核心理念是:元数据不仅是描述信息,更是驱动业务逻辑的引擎。
Dell PowerScale:文件存储的“元数据基因”
提到智能元数据,许多人首先想到对象存储。没错,对象存储因其嵌入式元数据功能而广受赞誉。但一个常被忽视的事实是:这种强大的元数据能力并非对象存储的专属。借助Dell PowerScale,传统文件存储同样能拥有同等的智能。
Dell PowerScale在文件存储领域的领先地位,不仅源于其卓越的安全性、性能、弹性和可扩展性,更关键的是,PowerScale早已从底层支持将任意键/值元数据与文件信息绑定并持久化存储。这为其行业优势再添重要砝码。
以下是一个直观示例。下面的命令行演示了如何为名为“test.docx”的文件设置自定义键“status”,并将其值设为“in-progress”。注意,这里的键/值对是完全自定义的字段,企业可按业务需求灵活设定,不受固定模板约束。

图 1:在PowerScale上读取与文件关联的任意元数据
该功能的意义远不止“便捷”。它使文件存储真正拥有了与对象存储同等的“智能”。更重要的是,利用PowerScale,企业可借助这些自定义元数据驱动具体业务逻辑。典型应用之一是与SmartPools分层存储功能结合。通过配置策略,系统可根据文件独特属性——如项目阶段、合规状态、数据重要性——而非单纯依赖最后访问时间,自动将文件移至最合适的存储层(高性能层或归档层)。这意味着存储资源能与数据价值精准对齐。
Dell PowerScale 与 Diskover Data:数据发现的双引擎
PowerScale自身已提供强大的元数据基础。但当它与戴尔科技合作伙伴Diskover Data结合时,数据潜能得到进一步释放。Diskover Data作为一款功能强大的元数据管理工具,与PowerScale元数据系统深度集成,可快速索引PowerScale中已有的自定义元数据,从而大幅提升用户的数据发现与分析效率。
更关键的是,Diskover Data不仅限于“读取”,还能将新的元数据直接写入PowerScale文件系统。这相当于为文件增加了一层永久关联的外部上下文信息,使数据的身份说明更加丰富精准。这种写入能力,是数据从“被描述”迈向“被驱动”的关键一步。
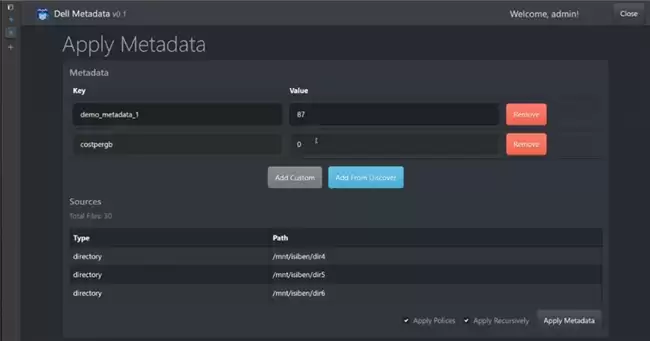
图2:Diskover Data在PowerScale上将键/值元数据应用于文件
这种整合的效能已在生命科学领域得到验证。一些研究机构利用PowerScale的高性能与高安全性,存储至关重要的患者影像数据。在这个高敏感、高价值的环境中,Diskover Data的价值被充分释放:它能捕获患者记录中的关键元数据(如患者ID、就诊日期、接诊医生、诊断记录等),并将这些信息作为自定义元数据直接写入PowerScale,确保患者信息与其影像文件之间形成不可分割的关联。
这种强大关联意味着:数据关键上下文始终可访问且易于识别。原本非结构化的影像数据与结构化患者信息无缝链接,形成单一、可搜索的“真实数据源”。对生命科学研究而言,研究人员可快速精准地找到所需数据;对患者护理而言,则意味着更精准的诊断和更高效的流程。企业通过整合PowerScale的原生元数据能力与Diskover Data的现代化索引及写入能力,可确保自身数据真正成为智能且具备自我描述特性的资源。
更关键的是,Diskover Data中已建立索引的元数据还可作为输入源,供戴尔科技数据分析引擎(Dell Data Analytics Engine, 简称DDAE)的联邦查询引擎调用。这两款产品间的协同方式非常灵活,为数据科学家与工程师提供了丰富的创新方案。例如,DDAE可直接查询Diskover Data中的索引,或由Diskover Data将Parquet文件推送至DDAE进行规模化处理。
戴尔科技数据分析引擎与Diskover Data:从非结构化数据中提炼数据集
如何高效整理与利用海量非结构化数据,是许多企业迈向现代化应用时面临的共同挑战。针对此问题,戴尔科技提供了一套高效解决方案,助力企业快速管理数据并最大化其价值。
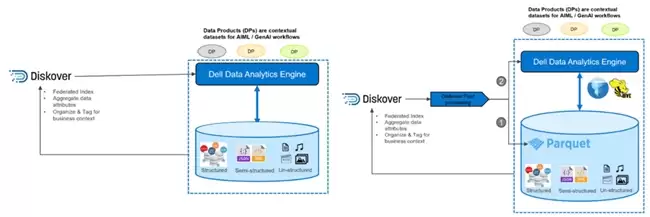
图 3:Diskover既可作为DDAE的数据源,也可推送Parquet文件供DDAE处理
依托Dell PowerScale,开启数据管理新局面
将关键的键/值元数据直接嵌入文件,绝非对象存储的独有功能,而是现代数据智能的核心根基。Dell PowerScale早已拥有这一能力。当这种原生智能与Diskover Data的强大编目及写入能力相结合时,一个卓越的数据管理解决方案便应运而生。
这一组合能够帮助企业实现以下目标:
- 发现:检索庞大存储库中的每一条数据,确保无信息被忽略;
- 自动化:根据业务上下文(而非简单技术指标)放置数据,使存储策略与业务价值对齐;
- 赋能:精心整理海量非结构化数据集,为戴尔科技数据分析引擎等高价值数据管道提供优质输入。
PowerScale对文件元数据的原生支持,与Diskover Data的全球编目功能无缝集成,最终将企业数据从混乱的成本中心彻底转变为智能化的战略资源。从节约存储成本,到推动生命科学领域的创新突破,这一组合正帮助企业在数据管理上实现全面的价值释放。
PowerScale在元数据功能上的先进性与高效性令人印象深刻,但它的真正价值在于成为戴尔科技模块化智能数据平台策略的核心支柱。它已超越传统存储解决方案的角色,成为驱动模块化戴尔科技智能数据平台的强大引擎,正重新定义现代化基础架构的未来演进方向。




