阿里通义大模型家族正式迎来新成员——Qwen3系列,一口气开源了8个不同规格的模型,引发行业广泛关注。
4月29日凌晨,阿里云正式对外开源了Qwen3系列,涵盖2个MoE模型与6个稠密模型。发布仅2小时,该系列在GitHub上的Star数便突破16.9k,市场热度可见一斑。
最引人瞩目的当属旗舰型号Qwen3-235B-A22B。在编程、数学、通用能力等多项基准测试中,其性能表现优于DeepSeek-R1、OpenAI o1,甚至超越o3-mini、Grok-3、Gemini-2.5-Pro等知名模型。具体有哪些亮点?让我们一探究竟。
此次升级的核心可归纳为五大关键点:
第一,涵盖8种参数规格的模型全面发布。从小巧的0.6B到旗舰级235B总参数、220亿激活参数的MoE模型,覆盖稠密与MoE两种技术路线。具体包括0.6B、1.7B、4B、8B、14B、32B六个稠密模型,以及Qwen3-235B-A22B和Qwen3-30B-A3B两个MoE模型。
第二,引入混合思考模式。用户可根据任务复杂度,自由切换“思考模式”与“非思考模式”,自主掌控模型的思考深度,实际使用中极为灵活。
第三,推理能力大幅提升。在思考模式下,数学、代码和常识逻辑推理能力超越前代QwQ;在非思考模式下,全面领先Qwen2.5 instruct系列。
第四,支持MCP协议(模型上下文协议),Agent能力显著跃升。无论思考还是非思考模式,模型均可与外部数据源及工具集成,完成更复杂的任务调度。
第五,语言覆盖面极大扩展,支持119种语言和方言,涵盖理解、推理、指令跟随与生成等全链路能力。
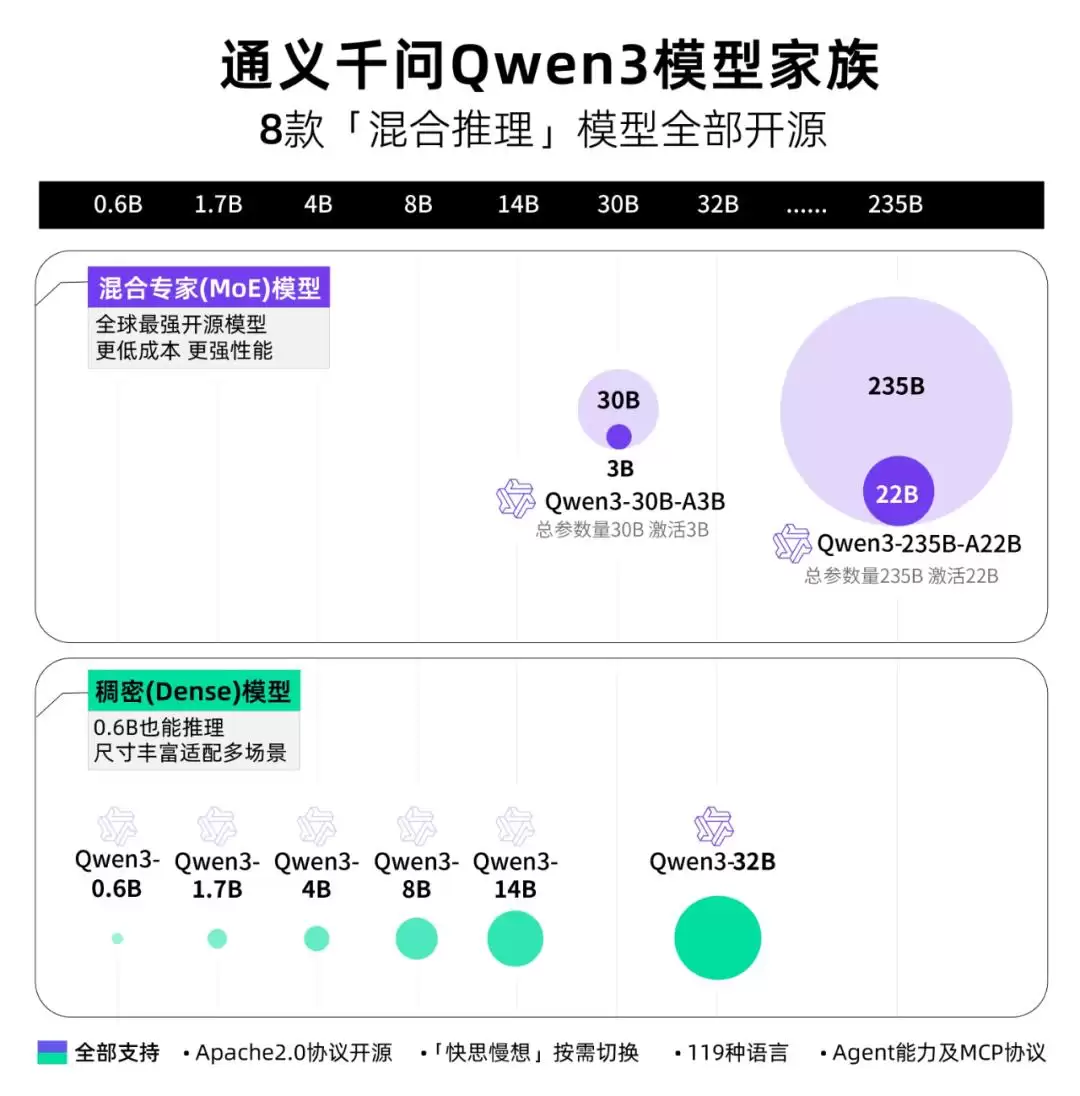
目前,Qwen3系列已在Hugging Face、ModelScope和Kaggle等主流平台开源,采用Apache 2.0许可证。部署方面,官方建议开发者优先使用SGLang和vLLM框架;若需本地部署,可选Ollama、LMStudio、MLX、llama.cpp等工具。
值得留意的是,Qwen3调整了命名方式:后训练模型不再带有“-Instruct”后缀,基础模型统一标注为“-Base”。
01. 以小搏大!激活参数仅1/10,性能反超
先看具体参数。6个稠密模型中,0.6B至4B规格的上下文长度为32K,8B至32B规格的则达到128K。
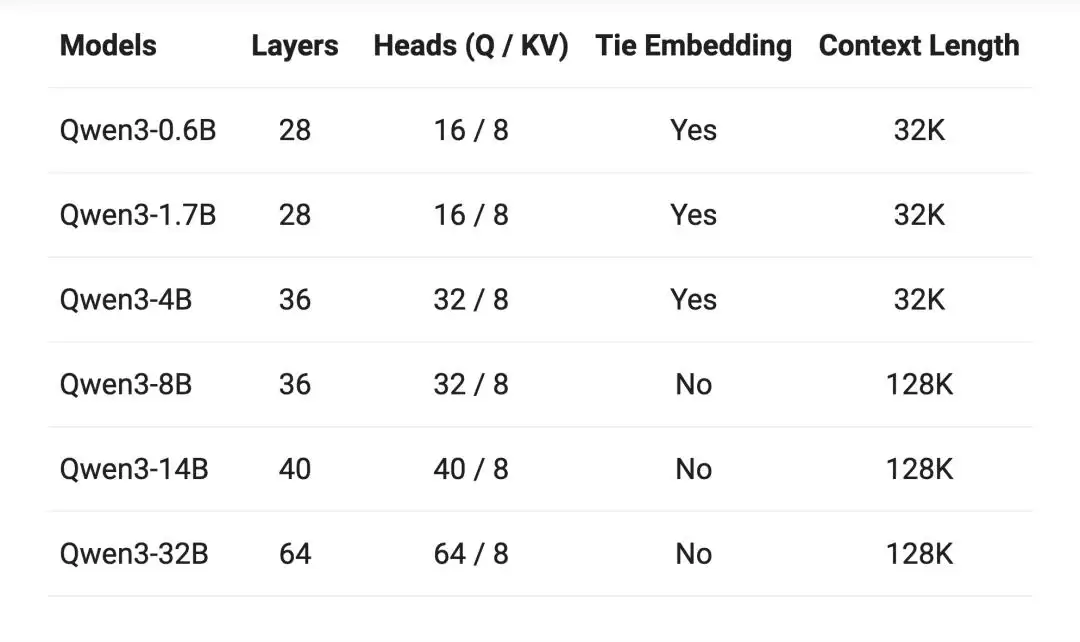
两个MoE模型的上下文长度均为128K。
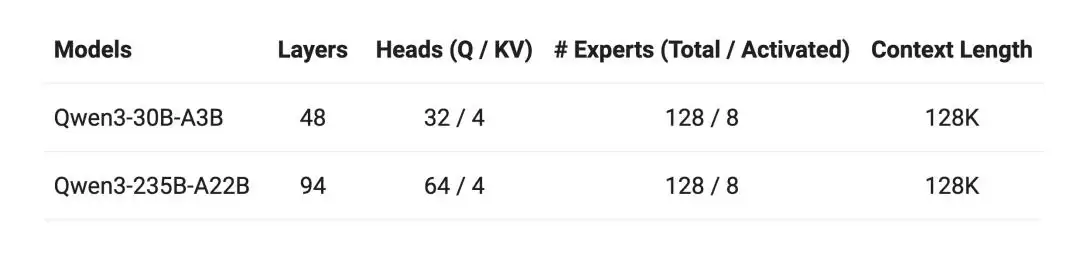
真正的亮点在于效率。小型MoE模型Qwen3-30B-A3B,激活参数仅为QwQ-32B的十分之一,却实现了性能反超。更令人惊讶的是,Qwen3-4B这个小模型,性能直接与Qwen2.5-72B-Instructor持平。
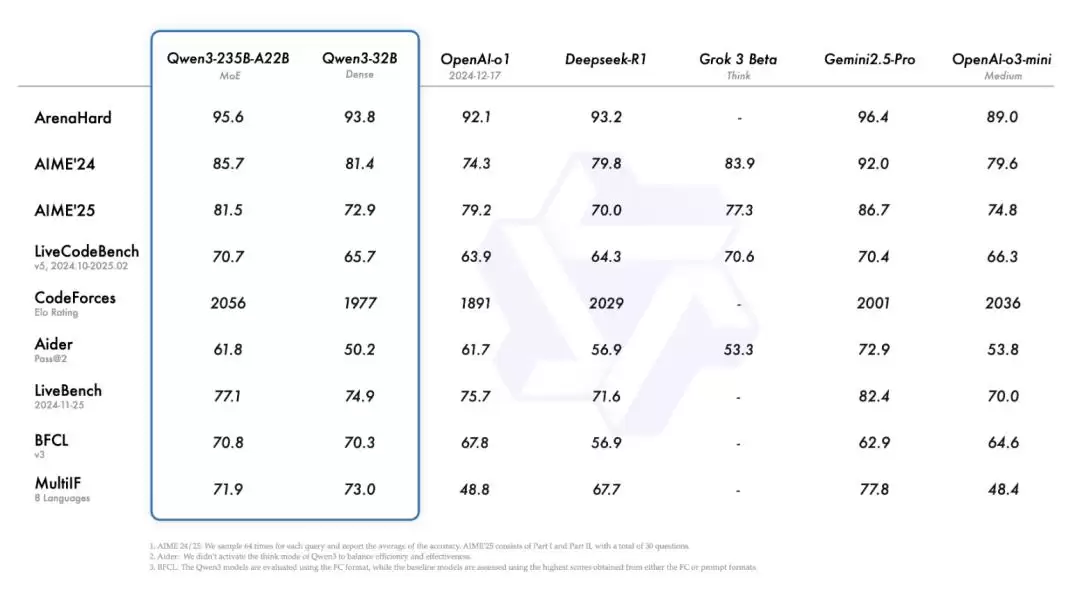
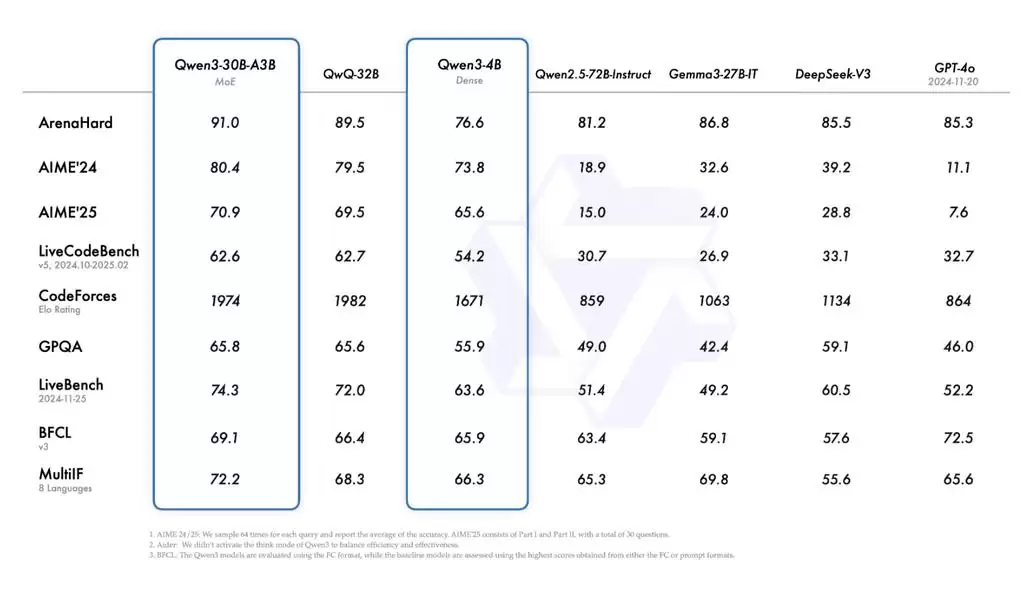
从基准测试数据来看,Qwen3-1.7B/4B/8B/14B/32B-Base的性能分别与Qwen2.5-3B/7B/14B/32B/72B-Base相当。换言之,更小的参数规模足以媲美甚至超越更大参数量的前代模型。
尤其在STEM(科学、技术、工程、数学)、编程和推理领域,Qwen3稠密模型的性能甚至优于参数规模更大的Qwen2.5系列。
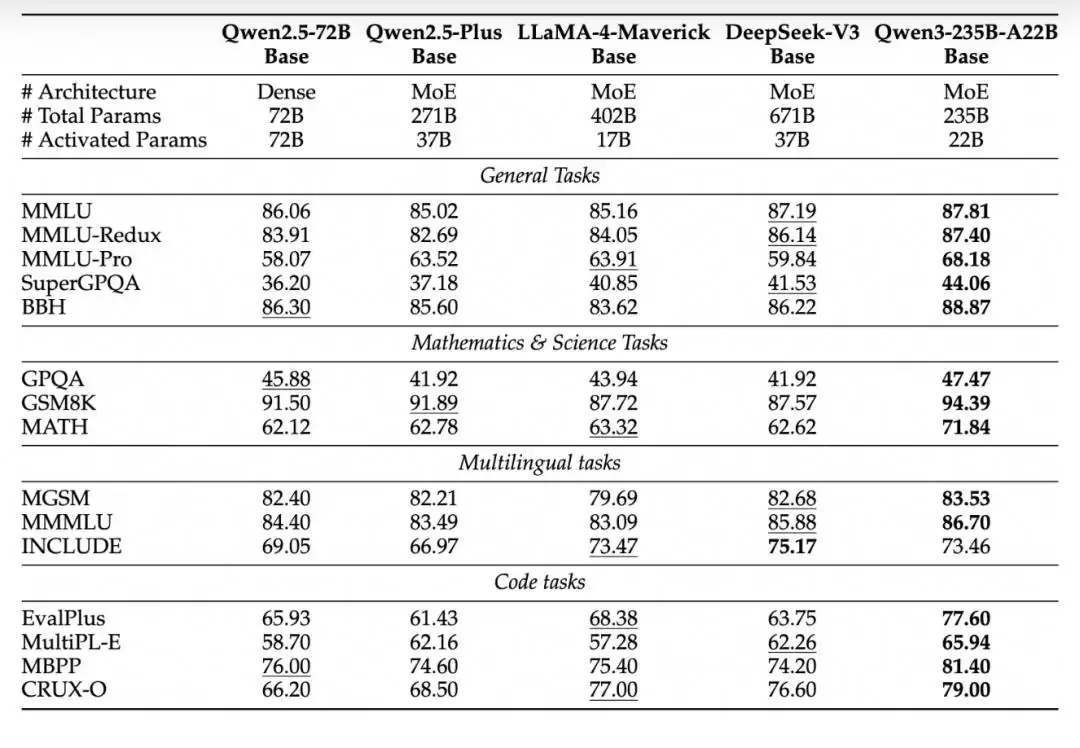
▲Qwen3系列与Qwen2.5系列基准测试对比
02. 混合思考模式 + 119种语言 + MCP协议
Qwen3的三大技术亮点值得深入探讨。
首先是混合思考模式。简单来说,模型支持“思考”和“非思考”两种工作状态。思考模式下,模型会逐步推理、花费更多时间给出最终答案,适合处理需要深度思考的复杂问题;非思考模式下,响应几乎瞬间完成,适合对速度要求高的轻量任务。
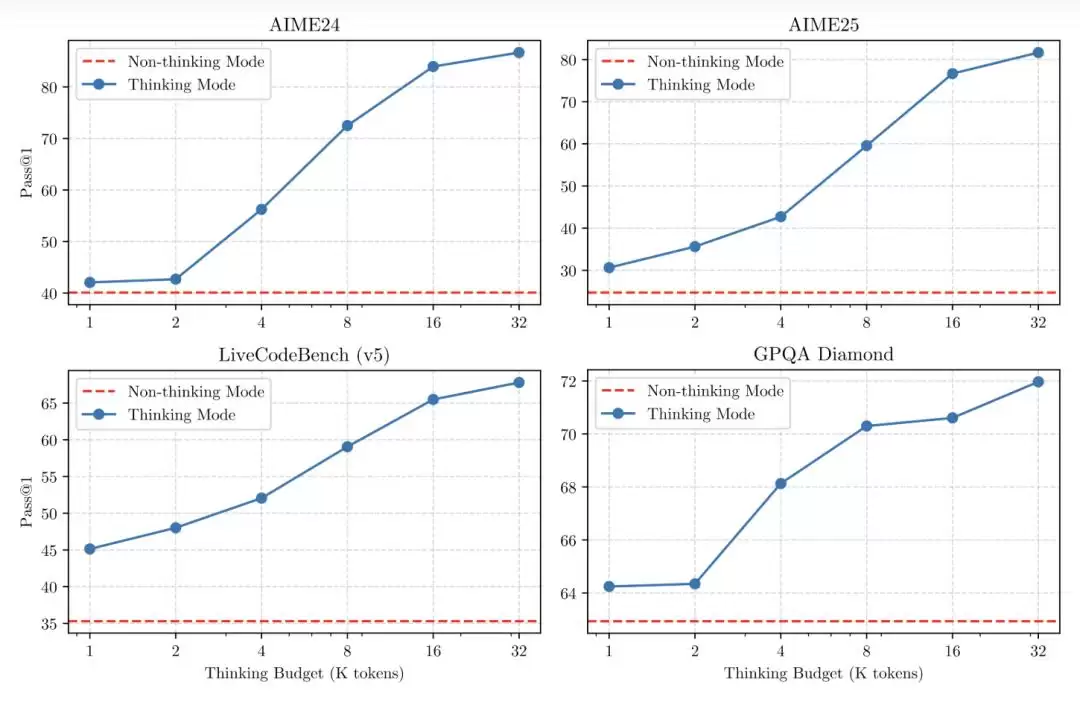
▲思考和非思考模式对比
这种设计意味着用户可根据任务难度自由控制模型的“思考预算”:难题可用扩展推理慢慢解决,简单问题则秒回响应,延迟几乎为零。更重要的是,两种模式的融合强化了模型对思考预算的稳定控制能力,开发者可针对特定任务配置预算,在成本效率与推理质量之间找到最佳平衡点。
在多语言能力方面,Qwen3支持多达119种语言和方言,这对全球化应用场景具有重要价值。

此外,Qwen3在编程和Agent能力上的提升同样显著,核心支撑在于集成了MCP协议,使模型与外部工具及数据源的协作更加流畅高效。
03. 预训练数据翻番,兼顾逐步推理与快速响应
性能提升的背后,是数据规模与技术路线的双重进化。
与Qwen2.5相比,Qwen3的预训练数据集直接翻倍——从1800亿token增加至约3600亿token。为凑齐如此庞大的数据集,研发团队收集了网络数据、PDF文档数据,并利用Qwen2.5-VL从文档中提取文本,再用Qwen2.5提升内容质量。数学和代码方面,则通过Qwen2.5-Math和Qwen2.5-Coder生成教科书、问答对及代码片段等合成数据。
预训练分为三个阶段:
第一阶段,模型在超过3000亿token上预训练,上下文长度为4K,主要打好语言和知识基础;第二阶段,提升STEM、编程、推理等知识密集型数据比例,再预训练500亿token;第三阶段,使用高质量长上下文数据将长度扩展至32K,使模型能处理更长的输入。
后训练阶段尤为关键。为打造一个既能逐步推理又能快速响应的混合模型,团队设计了四阶段训练流程:思维链(CoT)冷启动 → 基于推理的强化学习 → 思维模式融合 → 通用强化学习。
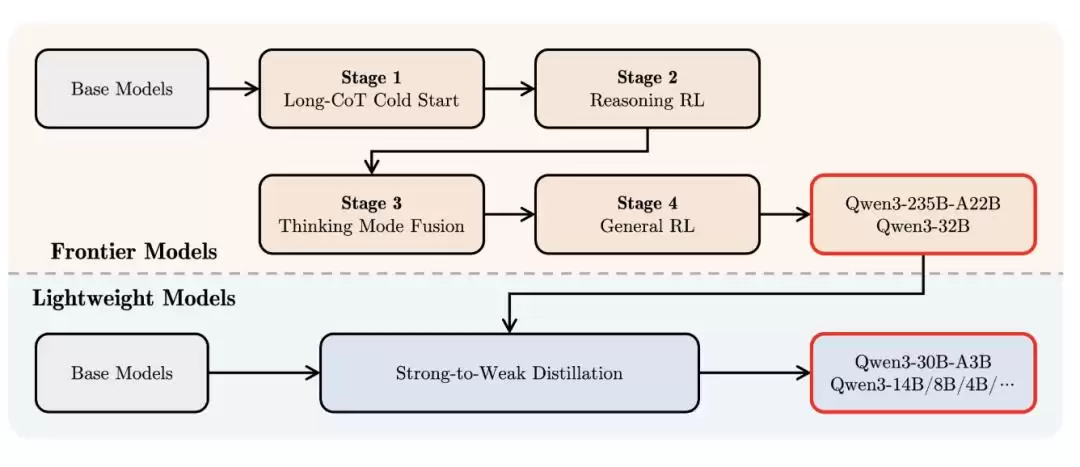
具体而言:第一阶段,用多样化的长思维链数据微调模型,覆盖数学、编程、逻辑推理和STEM问题,使模型具备基本推理能力;第二阶段,通过基于规则的奖励机制扩大强化学习计算资源,增强模型的探索与利用能力;第三阶段,在长思维链数据和指令微调数据上联合微调,将非思考能力无缝融入思考模型;第四阶段,在超过20个通用任务上应用强化学习,涵盖指令遵循、格式遵循和Agent能力,进一步将模型调教得更全面。
04. 结语:Agent生态爆发前夜,模型架构与训练方法双轮驱动
从Qwen3的表现可以看出,通过扩大预训练和强化学习的规模,以更小的参数规模实现更高的智能水平,这条路完全可行。混合思考模式的引入,也让开发者对模型预算的控制变得更加灵活。
展望未来,研发团队计划在几个方向上持续发力:优化模型架构和训练方法,进一步扩展数据规模、增加模型大小、延长上下文长度、拓宽模态,并通过环境反馈推进长期推理的强化学习。
一个不可忽视的趋势是,AI产业正从“训练模型”转向“训练Agent”。大模型能力的实际应用价值正在被一步步放大。通义大模型系列的目标,也正是围绕这一方向持续推进升级。




