在Linux系统中,查看文件内容的方法有很多,但有时我们只需要精准定位到某个特定部分——比如文件开头或结尾的若干行。此时,grep命令配合正则表达式就能发挥强大的作用。具体怎么操作呢?核心其实只有两个锚点符号:^和$。下面以常见的Ubuntu环境为例,为大家详细拆解每一步。
首先启动你的Linux系统,这里以Ubuntu为例。在左侧任务栏中找到TERMINAL图标,点击打开终端窗口。
接下来进入正题。grep后面加上^符号,可以指定匹配某一行的行首内容。举个例子,搜索以“Error”开头的行,命令是grep '^Error' 文件名。

那如果要定位到行尾呢?在grep的模式后面加上$符号,就能指定匹配某一行的行尾内容。比如搜索以“done”结尾的行,使用grep 'done$'即可。
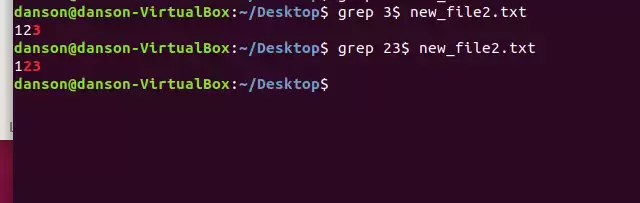
这两个符号当然也可以组合起来使用。^$同时出现时,表示指定某一行的首尾都必须包含的内容。例如grep '^start.*end$'就是查找以“start”开头、以“end”结尾的行。注意中间用.*来匹配任意字符(包括零个或多个)。

有一点必须特别留意:如果中间有一个字符缺失或不正确,哪怕只差一个空格,grep都会无法匹配到结果。正则表达式对精确度要求极高,这是使用过程中最容易踩的坑。

另外,Linux系统对大小写是敏感的。想要忽略大小写怎么办?加上-i参数即可。比如grep -i '^error',这样不管首字母是大写还是小写,都能被匹配到。

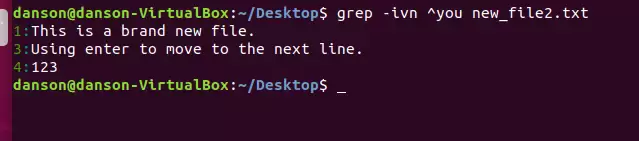
如果想更灵活一些,还可以把-v(取反)和-i组合使用。例如grep -vi '^#'可以找出所有不是以“#”开头的行——这在过滤配置文件的注释行时非常实用。

以上就是用grep查询指定首尾文件内容的核心操作。记住^和$这两个行首行尾锚点符号,再配合-i、-v等参数,几乎可以搞定日常工作中绝大部分的精准定位需求。




