Meta FAIR 近期发布了一项重磅研究——Code World Model(简称 CWM),这是一个拥有 320 亿参数的大型语言模型。其核心亮点在于采用“世界模拟”机制:先在内部模拟代码执行流程,再据此给出最终结果。
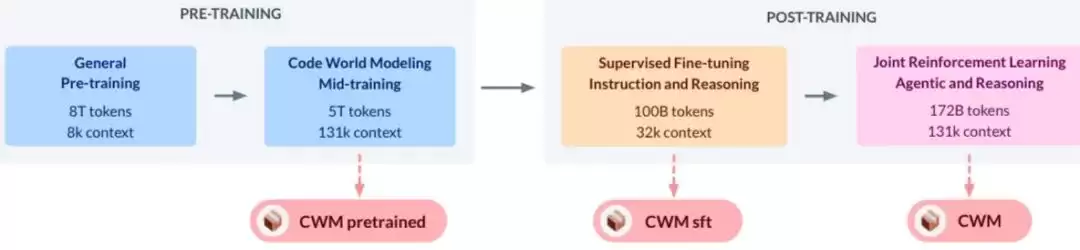
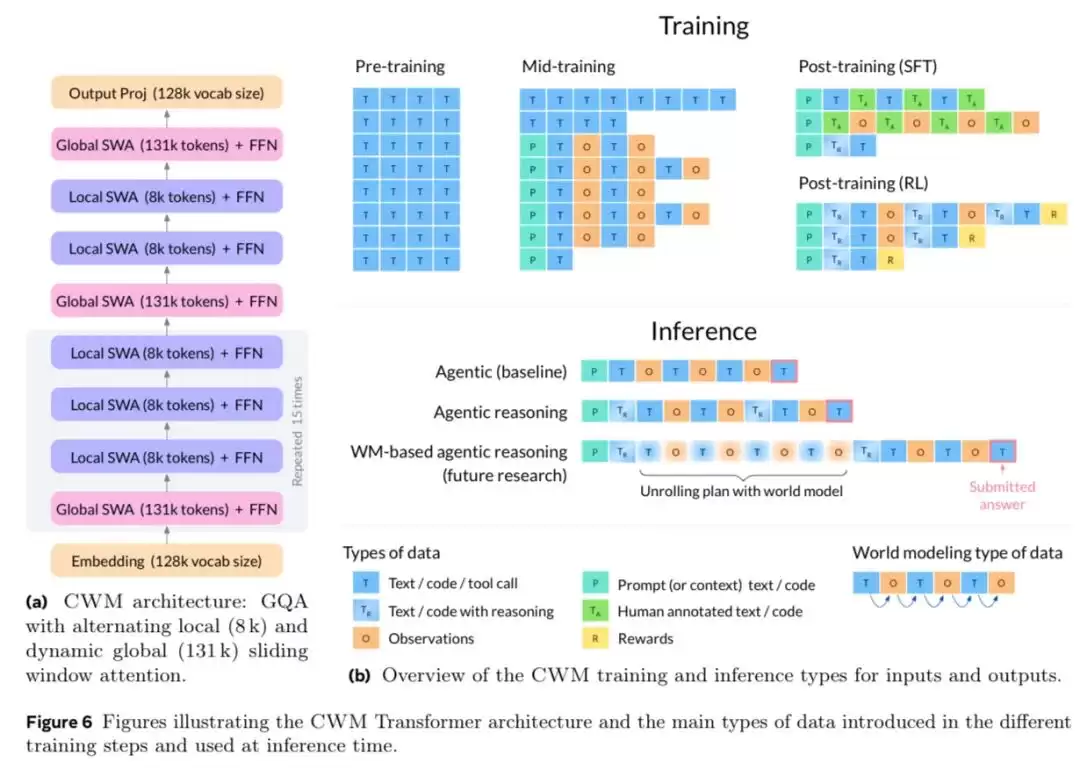
与市面上常见的代码生成模型不同,后者往往依赖训练数据中的模式匹配,类似于“抄作业”式的输出。而 CWM 则致力于真正理解代码的逻辑——它不仅生成代码,还能解释代码为何能运行以及如何运行。从这一点来看,Meta 在代码智能领域又向前迈出了重要一步。
模型在评估中表现优异:在 Math-500 数据集上取得了 96.6% 的高分。该数据集不仅测试代码生成能力,还包含数学推理任务,含金量较高。尽管并非排名第一,但对于一个新发布的模型而言,这无疑是一个出色的开局。
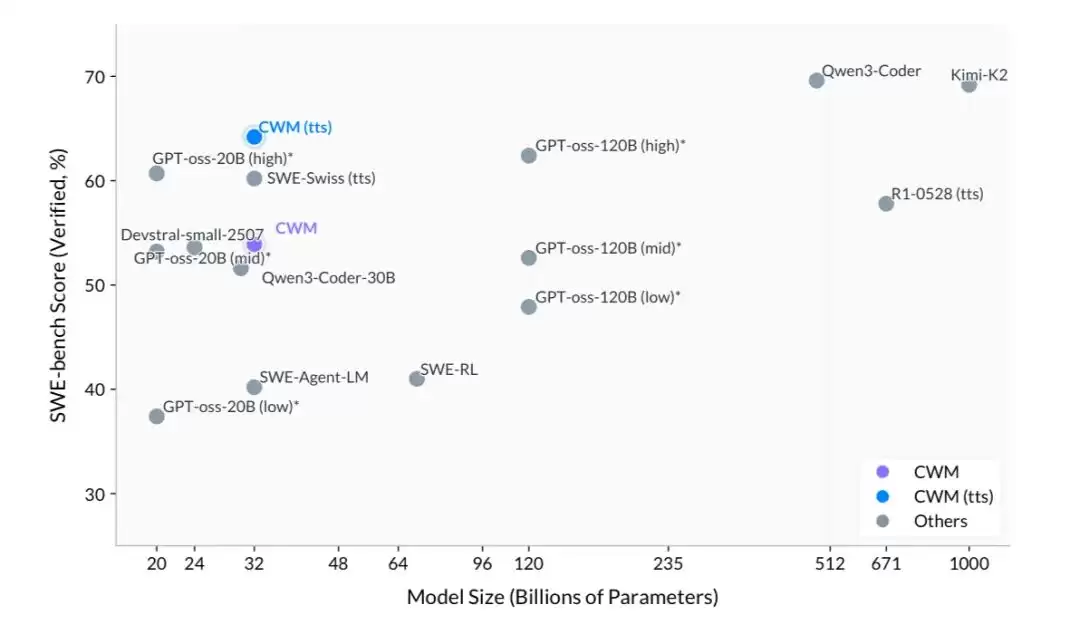
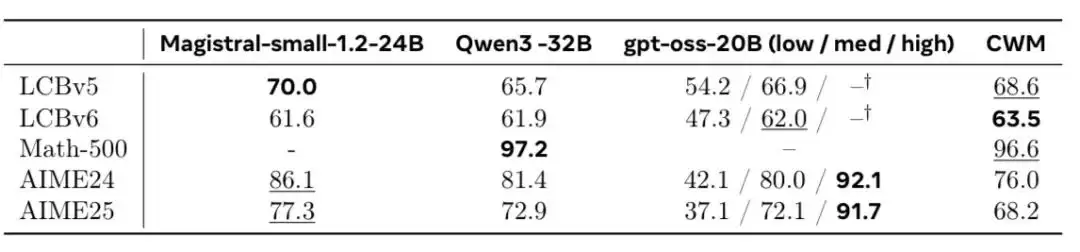
更值得称赞的是,Meta 将模型权重完全开源,并采用研究许可协议供自由使用。技术报告已在官网公开,模型文件上传至 HuggingFace,源代码托管在 GitHub——实现了全链路开放。目前社区中已有开发者在探索如何将模型“上链”,以便更多人参与迭代优化。
官方技术报告:https://ai.meta.com/research/publications/cwm/
权重下载:https://huggingface.co/facebook/cwm
代码仓库:https://github.com/facebookresearch/cwm




