Anthropic 正式发布了 Claude Sonnet 4.5。首先给出核心判断:这是当前最强的编程模型,没有之一。其在 SWE-bench Verified 上取得了 77.2% 的优异成绩,直接大幅领先其他竞争对手。更令人印象深刻的是,该模型能够连续稳定运行超过 30 个小时来处理复杂任务,且注意力不会涣散——这已经超越了传统 AI 的表现范畴。
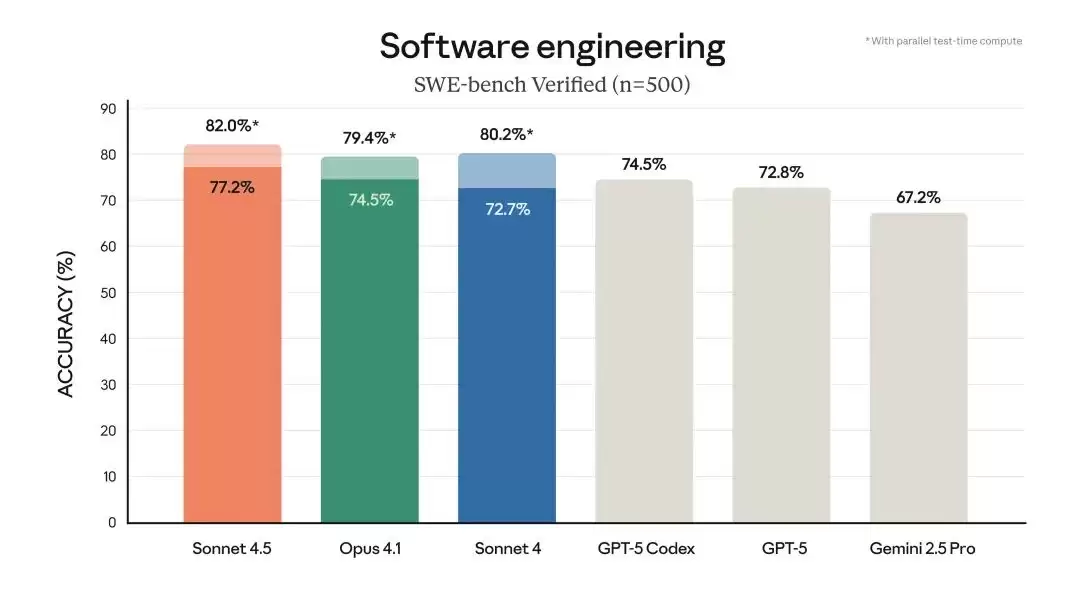 Chart showing frontier model performance on SWE-bench Verified with Claude Sonnet 4.5 leading
Chart showing frontier model performance on SWE-bench Verified with Claude Sonnet 4.5 leading
除了编程能力的显著提升,Claude Sonnet 4.5 在电脑操作方面也实现了实质性突破。在 OSWorld 测试中,其准确率达到了 61.4%——作为对比,四个月前 Sonnet 4 的成绩仅为 42.2%。结合新推出的 Chrome 扩展,Claude 现在可以直接在浏览器中导航网站、在线填写表单、执行各类任务,大大扩展了应用场景。
数学与推理能力同样有肉眼可见的提升。在金融、法律、医学、STEM 等专业领域,经过专家测试发现,该模型的知识储备和推理能力相比前几代有了质的飞跃。
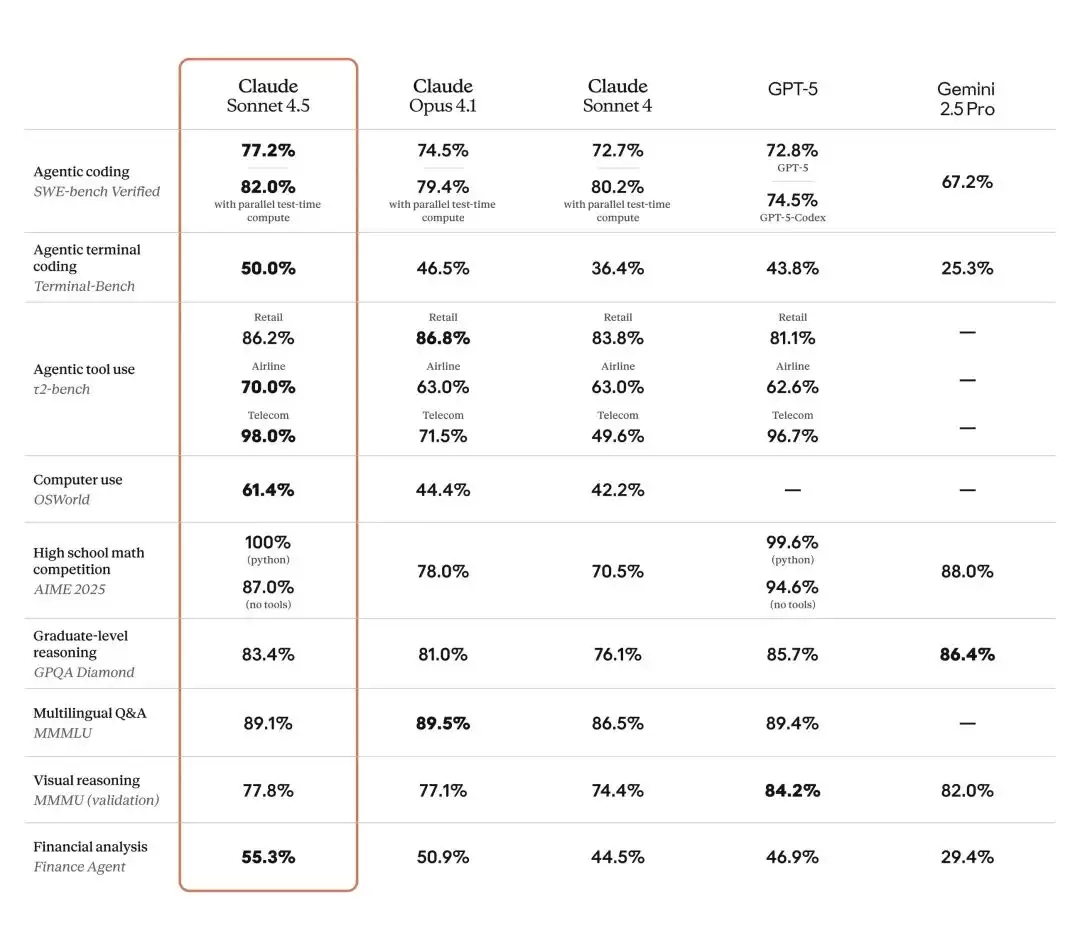 Benchmark table comparing frontier models across popular public evals
Benchmark table comparing frontier models across popular public evals
产品更新与开发者生态
在产品层面,Claude Code 新增了 checkpoint 功能,允许随时保存进度并回滚到之前版本——这对于需要长时间执行的任务来说极为实用。同时发布的还有原生 VS Code 扩展。API 层面引入了上下文编辑与记忆工具,使 AI Agent 能够处理更复杂的多步骤任务。Claude 应用现在支持代码执行和文件创建,涵盖表格、幻灯片和文档等类型。
本次更新中最值得关注的当属 Claude Agent SDK。Anthropic 将自己构建 Claude Code 所用的基础设施直接开放出来。这意味着开发者现在可以利用同样的工具来构建自己的 AI Agent,想象空间非常广阔。
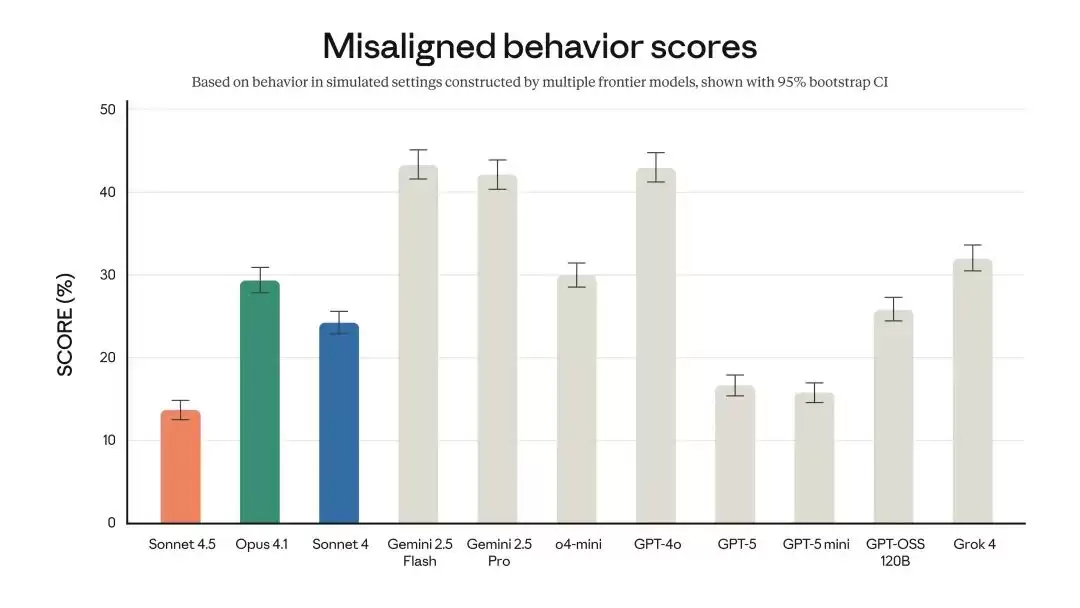
在安全性方面,这是 Anthropic 迄今为止发布的最“对齐”的前沿模型。模型在谄媚、欺骗、权力追求等行为问题上有了明显改善,同时针对提示注入攻击的防御能力也得到了增强。
价格方面保持不变,每百万 token 仍为 3/15 美元。开发者直接调用 claude-sonnet-4-5 即可使用。
来自合作方的实际反馈
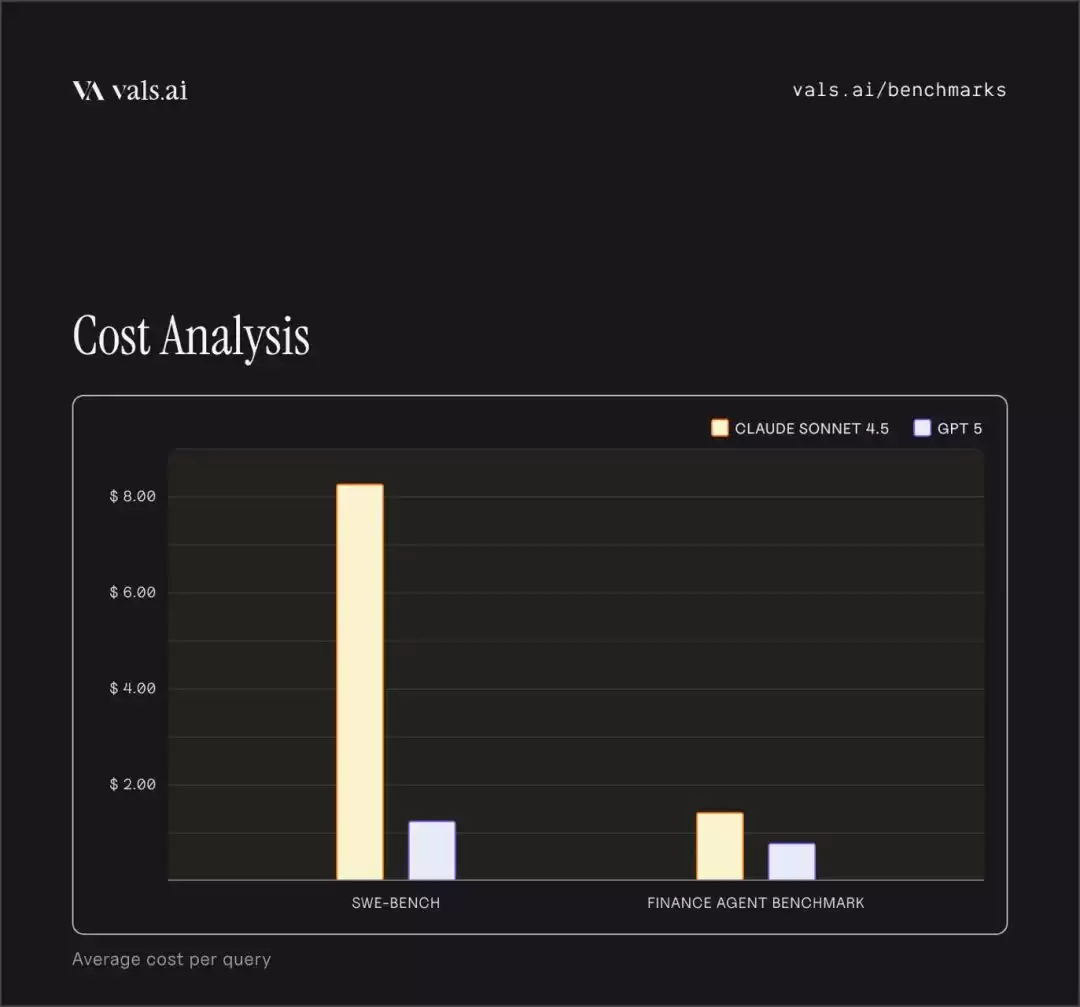
多个深度合作方的反馈具有很强说服力。Cursor 的 CEO 直言这是他们见过的最强编程模型。GitHub 的产品负责人表示,Sonnet 4.5 显著提升了 Copilot 处理复杂任务的表现。Replit 的实际使用数据显示错误率从 9% 降至 0——这个数字本身就说明问题。Canva 的评价是模型“明显更智能了”。特别是在金融领域,Sonnet 4.5 的优势极为突出:在金融 Agent 基准测试中大幅领先其他基础模型,堪称目前最适合实际金融分析工作的模型。
Anthropic 还放出了一个临时研究预览,名为 "Imagine with Claude",展示了模型实时生成软件的能力。Max 订阅用户可以体验五天。
昨天 DeepSeek 刚更新,今天 Claude 就来了。下一个会是谁?




