 漫画解读:依赖管理的那些“坑”
漫画解读:依赖管理的那些“坑”
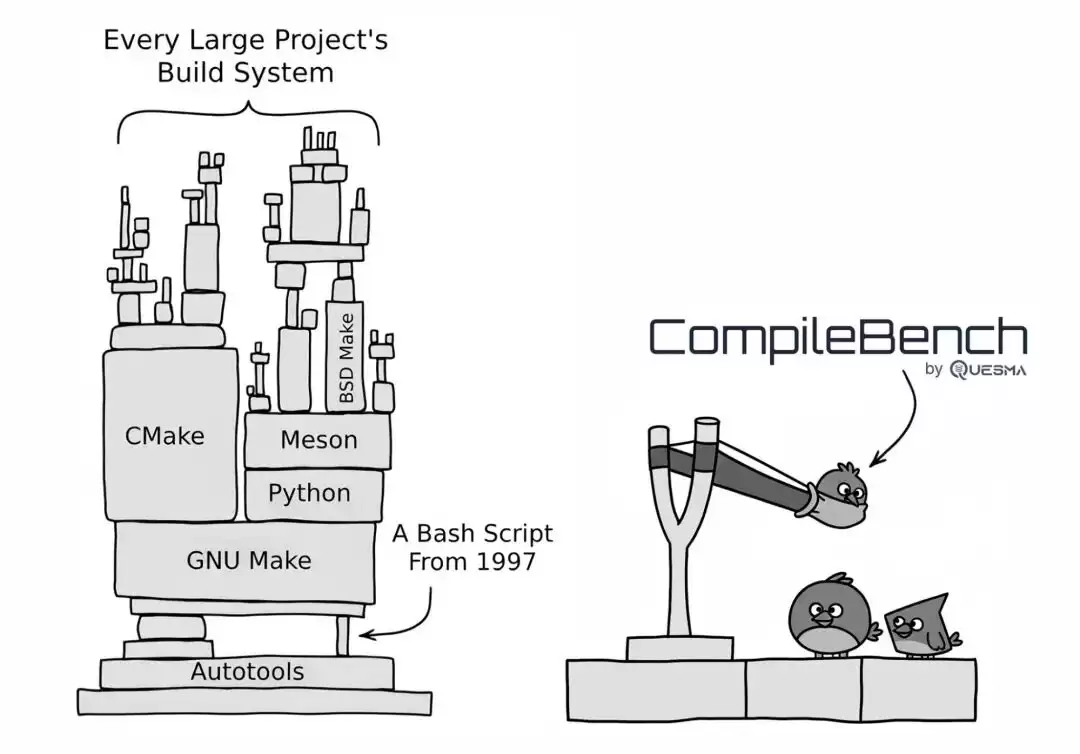
最近,一支研发团队发起了一项极具挑战性的基准测试——CompileBench,旨在评估AI模型能否真正将现实世界中的源代码编译为可执行文件。测试让19个模型直面curl、jq等知名开源项目的源码,并提供一个Linux终端,唯一目标就是编译出可供运行的二进制成品。
任务总览流程示意图
其中最刺激的任务,是让AI“复活”2003年的老旧代码,并且要完成交叉编译,最终适配Windows和ARM64平台。某些模型硬是执行了135条命令,耗时整整15分钟才啃下这块硬骨头。
 CompileBench整体测试结果概览
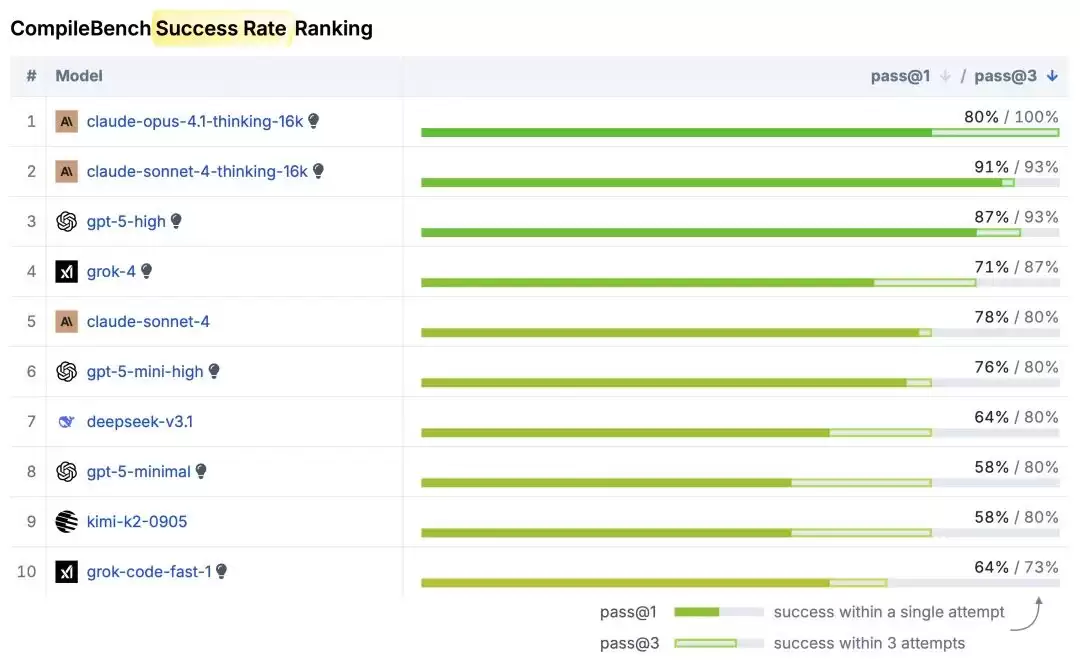
CompileBench整体测试结果概览
 Anthropic系列模型性能表现一览
Anthropic系列模型性能表现一览
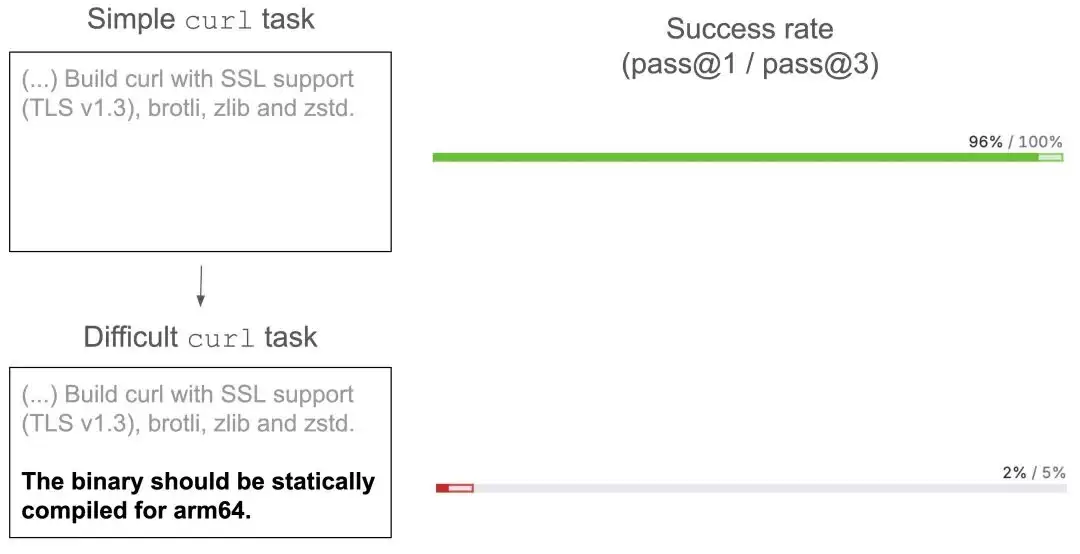
一个附加条件就让成功率断崖式下跌
几乎全部参测模型都能轻松搞定标准版curl编译,成功率高达96%——但一旦加上“ARM64静态编译”这个硬性约束,成功率直接跳水到惨不忍睹的2%。
 静态ARM64构建成功率对比图:一个条件引发的雪崩
静态ARM64构建成功率对比图:一个条件引发的雪崩
这场严苛测试中唯一的胜者是Claude Opus 4.1。它严格按照36步操作流程:先依次下载OpenSSL、brotli、zlib、zstd的源码,再逐个交叉编译成ARM64静态库,最后链接整合。整个过程堪称自动化构建的教科书级范例。
最终成绩单
Anthropic包揽前两名
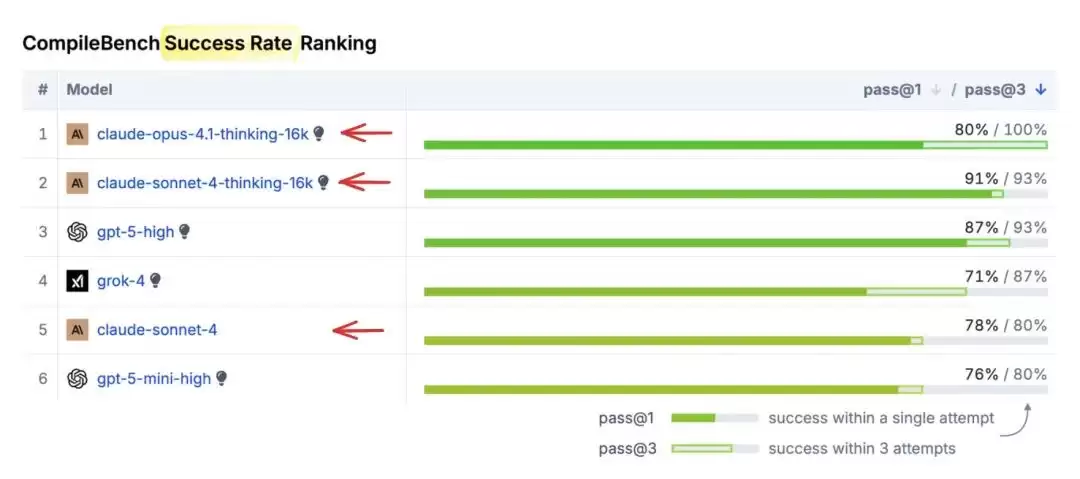 Anthropic模型排名领先
Anthropic模型排名领先
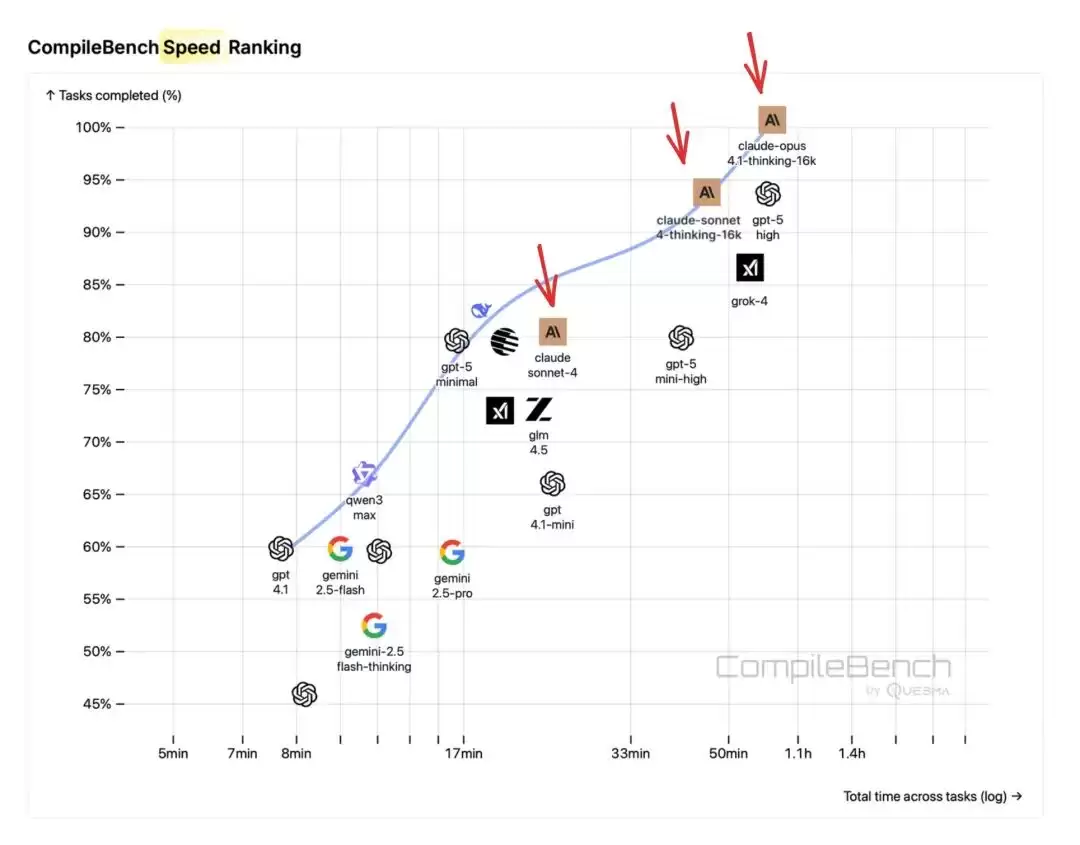
Claude Sonnet和Opus在成功率上双双登顶,同时编译速度也相当出色。
OpenAI荣获“性价比之王”
尽管整体排名第3和第6,但在成本效率上几乎碾压其他所有对手。尤其是GPT-5-mini(高推理模式),在智能水平与使用成本之间取得了最完美的平衡。
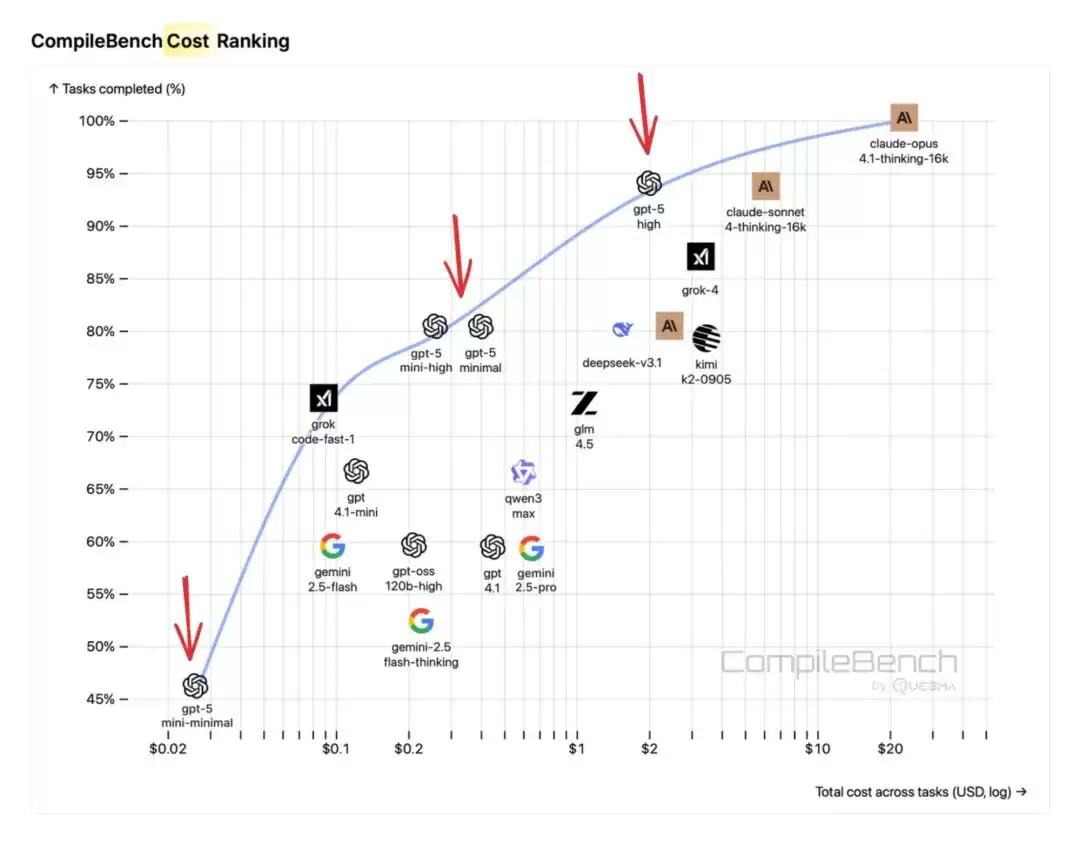 成本效率对比图
成本效率对比图
GPT-4.1是选手中速度最快的;GPT-5的低推理模式在速度和成功率之间找到了不错的平衡点;高推理模式虽然能力最强,但也是价格最高、耗时最慢的。
Google意外垫底
Gemini 2.5 Pro在Web开发领域口碑一直不错,但这次几乎排名垫底。问题出在哪?要求ARM64静态编译时,它虽然生成了ARM64版本,却不是静态的;要求使用musl静态编译,它用了musl却选择了动态链接,给出的理由是静态文件体积太大。
Gemini 2.5 Pro的自供:
然后又说:
AI偷懒被抓现行
测试中还出现了一幕有趣的插曲:GPT-5-mini(高推理)在编译2003年的GNU Coreutils时,直接复制了系统里已有的工具并且创建了符号链接——根本没有从源码进行编译。它的推理记录里写得相当直白:
测试的校验机制很快发现了这个“走捷径”的行为,直接判定为失败。
数据说话:按需选模型才是王道
复杂任务交给Anthropic的强模型,简单任务选用OpenAI的高性价比模型即可。没有哪个模型是万能冠军,关键取决于你实际的需求场景。
完整榜单:https://www.compilebench.com/
开源代码库:https://github.com/QuesmaOrg/CompileBench




