Unsloth 近日发布了一轮重要更新,重点强化了对视觉/多模态模型的强化学习训练支持——目前已正式集成 Gemma 3 与 Qwen2.5-VL 两大系列。
核心亮点
本次升级的关键在于 Unsloth 独有的权重共享机制与自定义内核,使得视觉语言模型(VLM)在进行 RL(强化学习)训练时,相比常规 FA2 配置,速度提升了 1.5 至 2 倍,显存占用下降了 90%,上下文长度扩展了 15 倍,且精度完全无损。同时,Unsloth 还引入了阿里巴巴 Qwen 团队研发的 GSPO 算法,为技术社区带来了意外之喜。
更令人振奋的是,现在你可以在免费的 Colab T4 GPU 上直接训练 Qwen2.5-VL-7B 模型。其他视觉语言模型同样可以运行,但可能需要更强大的 GPU 支持。至于 Gemma,由于 vLLM 限制只能使用 Bfloat16 精度,因此需要比 T4 更新的 GPU 硬件,例如 Colab 上的 NVIDIA L4 就是理想选择。
官方提供了一份 notebook 示例,展示了如何通过图像和图表解决数学问题:
 数学推理示例图
数学推理示例图
vLLM 集成
在此版本中,Unsloth 原生集成了 vLLM VLM。如需启用 vLLM 进行快速推理,只需在初始化模型时设置 fast_inference=True 即可:
os.environ['UNSLOTH_VLLM_STANDBY']='1' # 启用内存高效的 GRPO 模式
model, tokenizer = FastVisionModel.from_pretrained(
model_name="Qwen/Qwen2.5-VL-7B-Instruct",
max_seq_length=16384, # 需足够大以完整容纳图像 token
load_in_4bit=True,
fast_inference=True, # 开启 vLLM 快速推理
gpu_memory_utilization=0.8,
)
需要注意,vLLM 目前尚不支持视觉/编码器层的 LoRA 微调。因此在加载 LoRA 适配器时,务必将 finetune_vision_layers 设置为 False。但若使用 transformers 或 Unsloth 原生推理,视觉层仍可正常训练。
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers=False, # vLLM 暂不支持视觉层 LoRA
finetune_language_layers=True,
finetune_attention_modules=True,
finetune_mlp_modules=True,
r=lora_rank, # 建议取值:8、16、32、64、128
lora_alpha=lora_rank*2,
use_gradient_checkpointing="unsloth",
random_state=3407,
)
GSPO 算法介绍
GSPO 是 Qwen 团队开发的一种 GRPO 变体。研究团队发现,GRPO 会隐式地为每个 token 分配重要性权重,但优势(advantages)并不随 token 变化——这显然不合理。GSPO 应运而生,它将重要性分配从单个 token 的似然转移到整个序列的似然上。
 标准 GRPO 算法流程
标准 GRPO 算法流程
标准 GRPO 算法流程
 改进的 GSPO 算法流程
改进的 GSPO 算法流程
改进的 GSPO 算法流程
用通俗的语言解释:在 GRPO 中,每个 token 获得相同的缩放权重,即使这个缩放是针对整个序列进行的。而 GSPO 则不同——它在计算完 logprob 比率后,先对每个序列求和并取指数,最终只有序列级别的比率才会与优势进行逐行相乘。这相当于把注意力从单个词转移到了整个句子上。
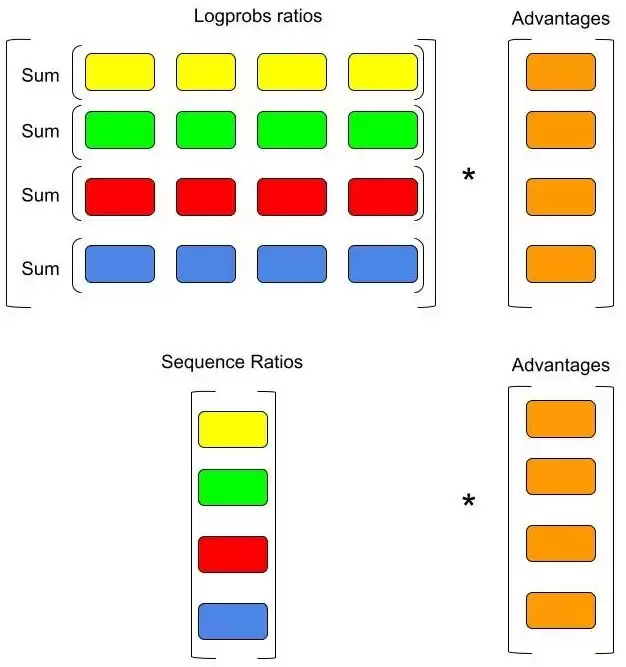
启用 GSPO 非常简便,只需在 GRPO 配置中设置 importance_sampling_level = "sequence":
training_args = GRPOConfig(
output_dir="vlm-grpo-unsloth",
per_device_train_batch_size=8,
gradient_accumulation_steps=4,
learning_rate=5e-6,
adam_beta1=0.9,
adam_beta2=0.99,
weight_decay=0.1,
warmup_ratio=0.1,
lr_scheduler_type="cosine",
optim="adamw_8bit",
importance_sampling_level="sequence", # 启用 GSPO 序列级重要性采样
loss_type="dr_grpo",
epsilon=3e-4,
epsilon_high=4e-4,
num_generations=8,
max_prompt_length=1024,
max_completion_length=1024,
log_completions=True,
max_grad_norm=0.1,
temperature=0.9,
num_train_epochs=2,
report_to="none"
)
总体来看,Unsloth 此次对 VLM vLLM 快速推理的改进非常扎实——内存使用减少了 90%,GRPO 与 GSPO 的训练速度提升了 1.5 到 2 倍。再加上新集成的内存高效且更快的强化学习功能(包括独特的 Standby 特性),相比其他实现能有效抑制速度降级。这套组合拳,确实值得开发者们认真关注。




