提到大语言模型的“幻觉”,相信大家都不陌生。当AI医生为你提供一份“凭空杜撰”的诊断方案,或AI律师引用一条“子虚乌有”的法律条文时,这些看似合理却虚假的信息一旦进入现实场景,带来的风险绝不容小觑。
过去,应对幻觉问题往往属于“事后诸葛亮”的范畴。等模型洋洋洒洒生成完整长文后,再用另一套系统去拆解、检索、逐一验证每个“事实声明”。这种做法不仅耗时、成本高昂,更关键的缺陷在于它无法介入生成过程,几乎无法应用于需要实时交互的场景。
理想的状态是什么?想象一下,如果AI在生成长篇内容的过程中,就能实时地将那些虚构部分高亮标记出来,那该有多好。
来自苏黎世联邦理工学院(ETH Zürich)等机构的研究团队,在最新论文《Real-Time Detection of Hallucinated Entities in Long-Form Generation》中,成功实现了这一设想。他们开发了一款流式幻觉检测器,能够在模型生成文本的同时,即时标记出存在问题的实体。与以往主要针对短问答场景的检测方法不同,这项技术专门攻克长文本生成中幻觉检测的难题。
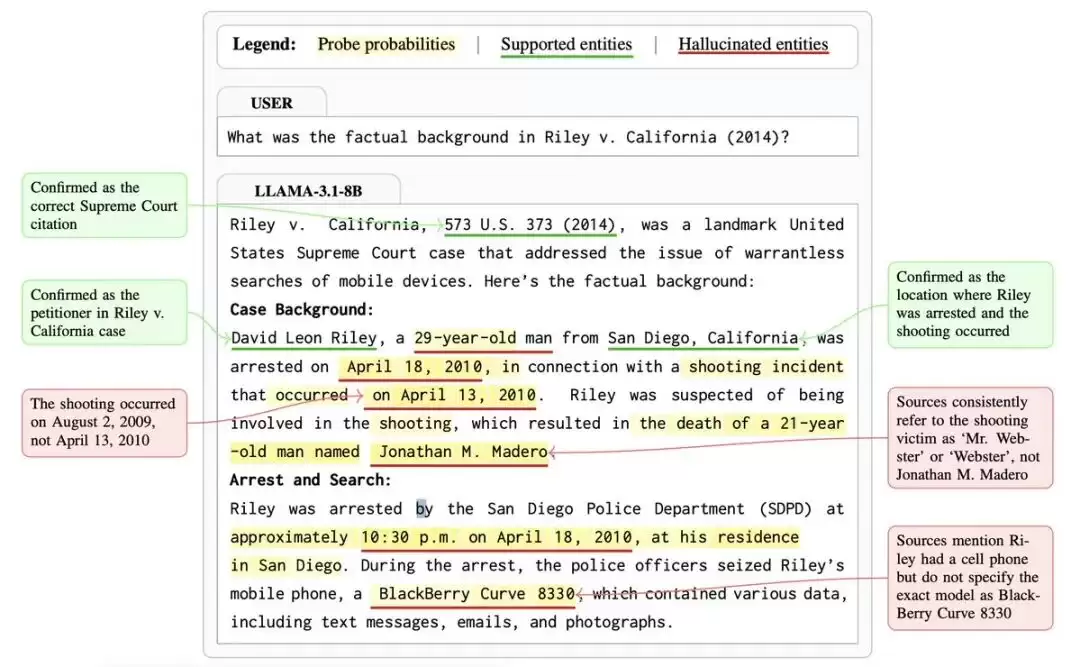
那么,它的核心理念究竟是什么?并非判断整个句子的真假,而是聚焦于具体的“实体”(如人名、地名、日期、数字等),精准识别它们是否属于虚构。
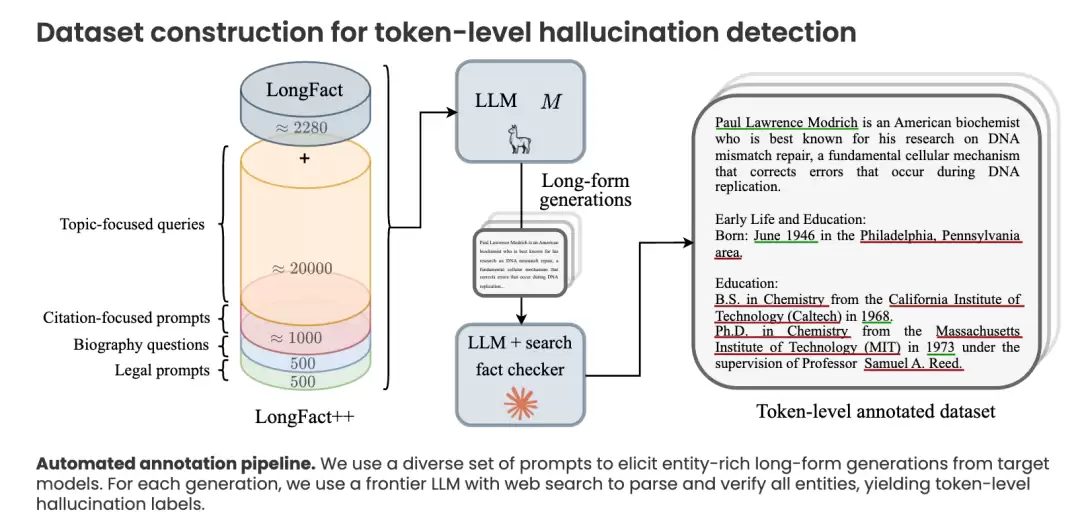
这个实现方案的巧妙之处体现为以下三步:
第一步,数据准备。 先让一个大模型(例如Llama-3.3-70B)针对各种主题生成回答,这些回答自然会同时包含真实实体和虚构实体。
第二步,自动标注。 再利用一个更先进、具备联网搜索能力的模型(例如Claude),对回答中的每一个实体进行自动验证,并为每个词(Token)贴上“幻觉”或“非幻觉”的标签。
第三步,训练探针。 基于标注好的数据,训练一个极其轻量的线性探针(Linear Probe)。该探针能够直接读取模型在生成每个词时的内部状态(隐藏层激活值),瞬间判断该词是否为“幻觉”的一部分。
一个有趣的发现是,当使用LoRA探针进行微调时,模型会表现出更强的“认知谦逊”——有时在生成一个幻觉实体后,会立刻进行自我纠正。
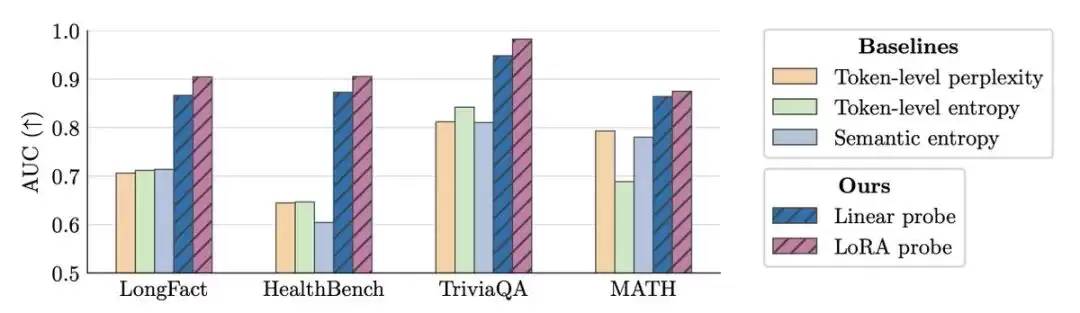
实验结果表明,在多个长文本生成场景中,该方法的AUC(一种评估模型性能的指标)显著优于传统方法。更令人意外的是,它在短问答和数学推理等领域也表现出色。这意味着,即使仅针对“实体”进行训练,该检测器也学到了识别更广泛内容真实性的能力。
当然,创建标注数据集的成本确实不低。但好消息是,研究发现,在一个模型上标注的数据可以有效地迁移用于训练其他模型的检测器。为此,研究团队已将数据集和代码完全开源。
话说回来,这项技术也有自身的局限性。例如,如果模型从头到尾都在大篇幅地胡编乱造,那么满屏的高亮标记反而可能使用户无法判断重点。
小结
这项技术的演进标志着幻觉检测已从“事后补救”转向“过程监控”。其最直接的应用场景无疑是高风险领域,比如医疗或法律咨询。想象一下,一个医生助手AI在生成诊断建议时,能够实时标记出不确定的药物名称或研究引用——这种实时预警能力远比事后发现问题再修改要珍贵得多。
论文地址:https://arxiv.org/abs/2509.03531
代码与数据:https://github.com/obalcells/hallucination_probes




