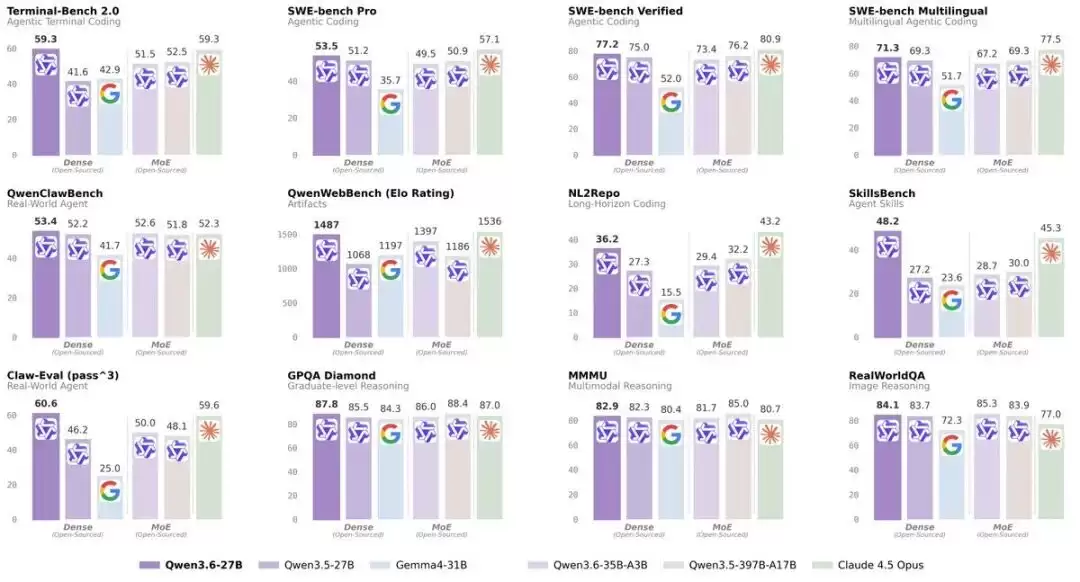
阿里巴巴最新开源的 Qwen3.6-27B 模型,正以 27B 参数的密集架构重新定义参数规模与性能的关系。这款紧凑型模型在 Terminal-Bench 2.0、SWE-bench Pro 等主流编码基准测试中,全面超越前代 397B 参数的混合专家模型(Qwen3.5-397B-A17B),实现了性能上的显著突破。
技术亮点
混合注意力架构:3:1 比例的 Gated DeltaNet 与全门控注意力层高效组合
原生多模态:统一处理文本、图像和视频,RealWorldQA 视觉理解得分高达 84.1
超长上下文:原生支持 262K tokens,并可扩展至 1M
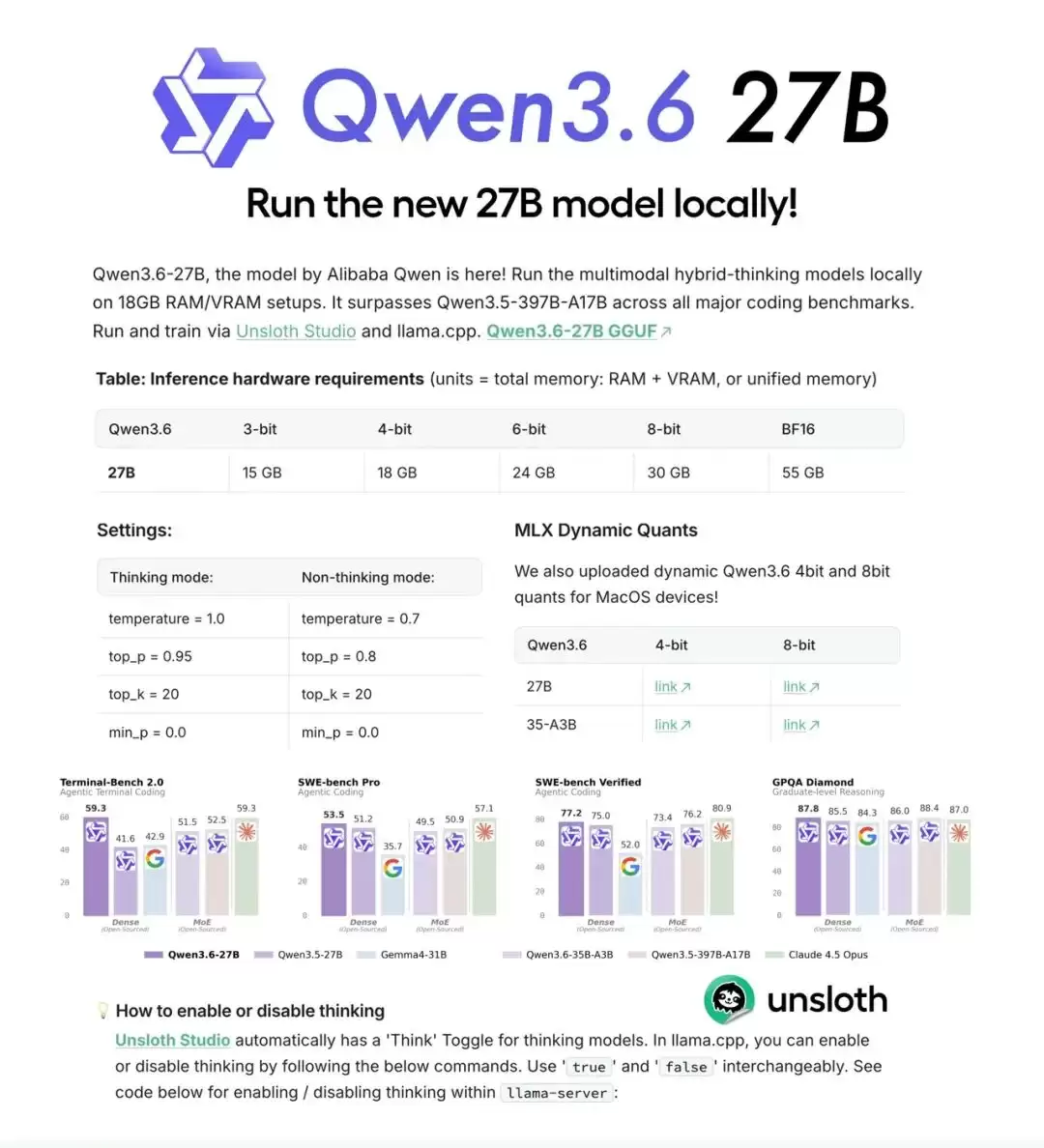
高效推理:4-bit 量化版本仅需 18GB 内存即可运行
架构优势解析
Qwen3.6-27B 作为密集模型之所以能超越规模更大的 MoE 模型,关键在于其注意力机制的精心设计。与 MoE 模型每次只激活部分专家不同,该模型的每个 token 都能调用全部参数,从而保证推理过程的一致性。在相同参数规模下,这种设计让模型比 MoE 更“智能”,但计算速度相对较慢。
在编码任务中,这种一致性尤为关键——DeltaNet 层专注于处理局部上下文(如当前语法结构、变量定义),而全注意力层则能够捕捉跨文件的函数签名等远距离依赖关系,大幅提升代码理解的准确性。
本地运行方案
借助 Unsloth 提供的 Dynamic GGUFs 量化方案,开发者现在可以在消费级硬件上部署这一前沿模型:
# 下载4-bit量化模型
hf download unsloth/Qwen3.6-27B-GGUF --local-dir unsloth/Qwen3.6-27B-GGUF --include "*UD-Q4_K_XL*"
硬件需求参考
| 量化精度 | 内存需求 |
|---|---|
| 3-bit | 15GB |
| 4-bit | 18GB |
| 8-bit | 30GB |
| BF16 | 55GB |
开发者实测
社区热议的焦点集中在模型大小的权衡上。有观点认为,27B 参数刚好卡在 16GB 显存的边缘,需使用 Q3 量化才能流畅运行,而 Q3 量化对 27B–32B 模型的性能影响相对较大。
另有开发者反馈,在 Nuxt Go-zero 技术栈的实际项目中,Qwen3.6-27B 的表现比基准测试更为突出。其 262K 原生上下文窗口(可扩展至 1M)在处理大型代码库时优势明显,而 MoE 模型在长上下文多轮交互中容易出现性能断崖式下降。




