最近,AI深度研究领域出现了两项值得深入探讨的新进展。一是智源研究院开源的InfoSeek数据集,二是通义实验室发布的Tongyi DeepResearch智能体。两者都聚焦于同一个核心问题:如何让AI真正实现“深度”研究,而不仅仅是表面化的信息检索。
先来了解InfoSeek。这个数据集专为深度研究任务设计,是目前首个完全开源的大规模多步推理数据集。通过它训练30亿参数模型,在深度研究任务中的表现据说可以与Gemini、Sonnet 4.0一较高下。下面是一张架构图,供参考:

InfoSeek的三个显著特征如下:第一,它是首个专门针对深度研究任务打造的开源数据集;第二,数据集本身及其数据合成框架全部开源,没有任何使用限制;第三,包含超过5万个高质量的多步推理样本,并非随意抓取的断章取义内容。
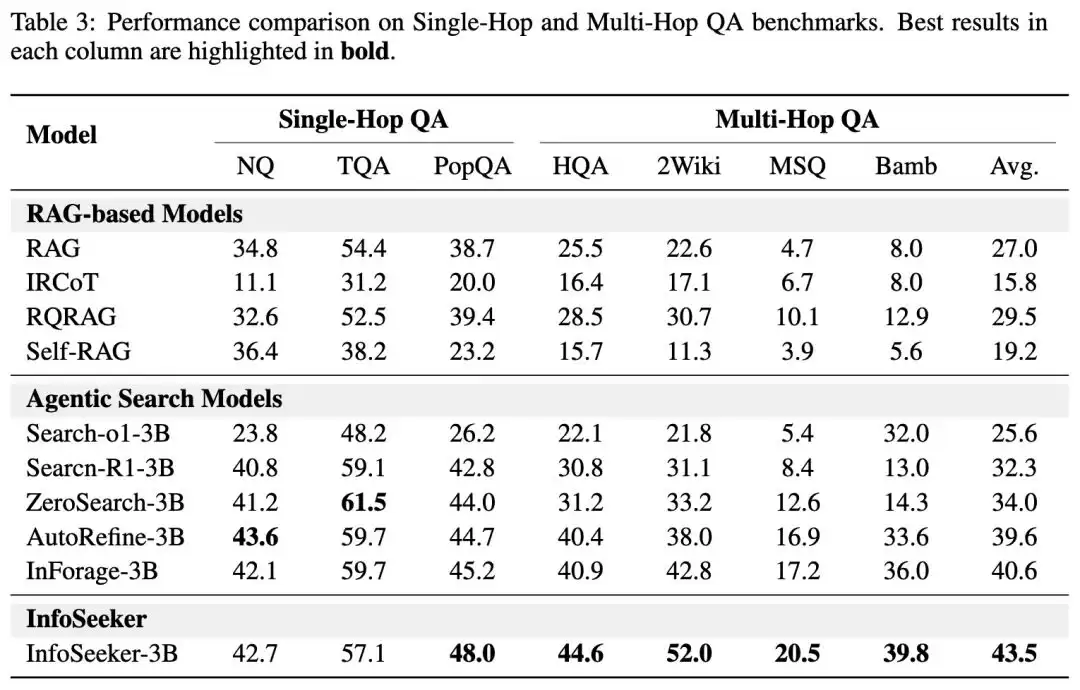
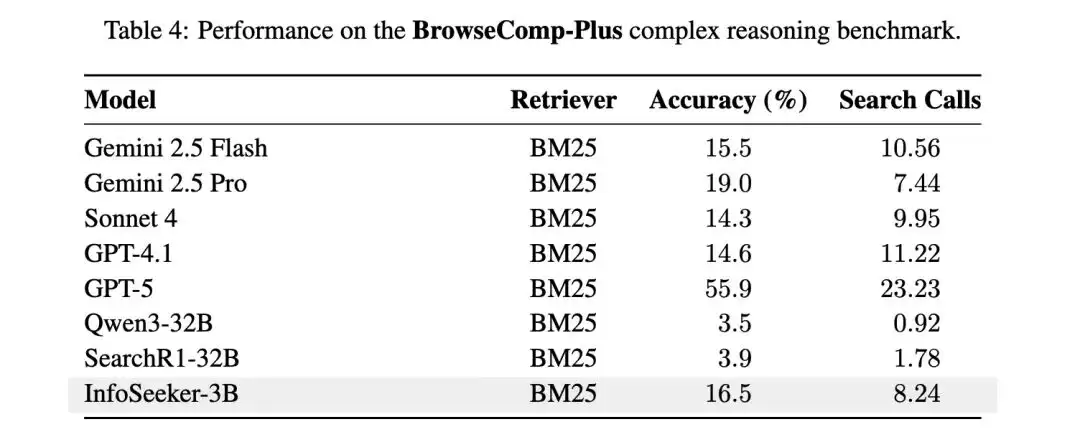
开源社区对这类专业数据集的需求一直非常迫切。目前大多数现有数据集要么规模太小——几百个样本根本无法支撑复杂任务,要么质量参差不齐——自动合成而来的数据噪声过大。InfoSeek的推出,恰好填补了这一空白。
值得关注的是,该数据集在海外获得了积极评价。研究员Tobe Duru表示“这看起来像是研究的游戏规则改变者”。事实上,在AI研究领域,高质量数据往往比模型架构本身更能决定最终效果的上限。看看那些依赖海量数据训练出的大模型,便不难理解这一点。
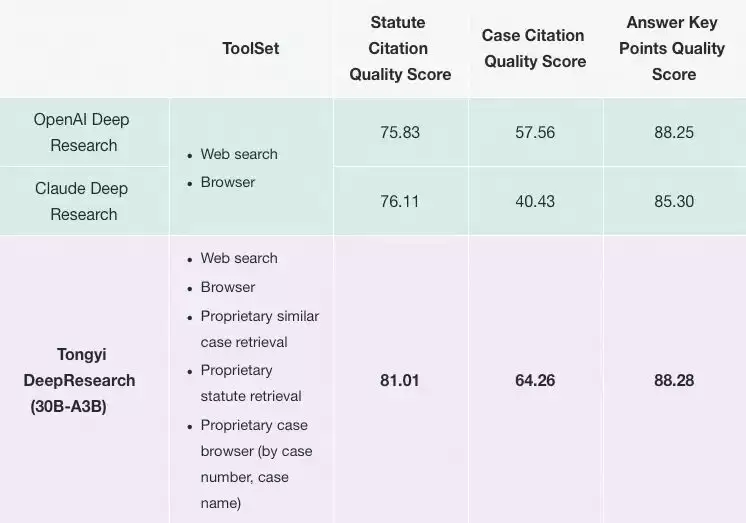
与此同时,通义实验室发布的Tongyi DeepResearch同样引人注目。这是一个开源智能体,直接对标OpenAI的Deep Research。
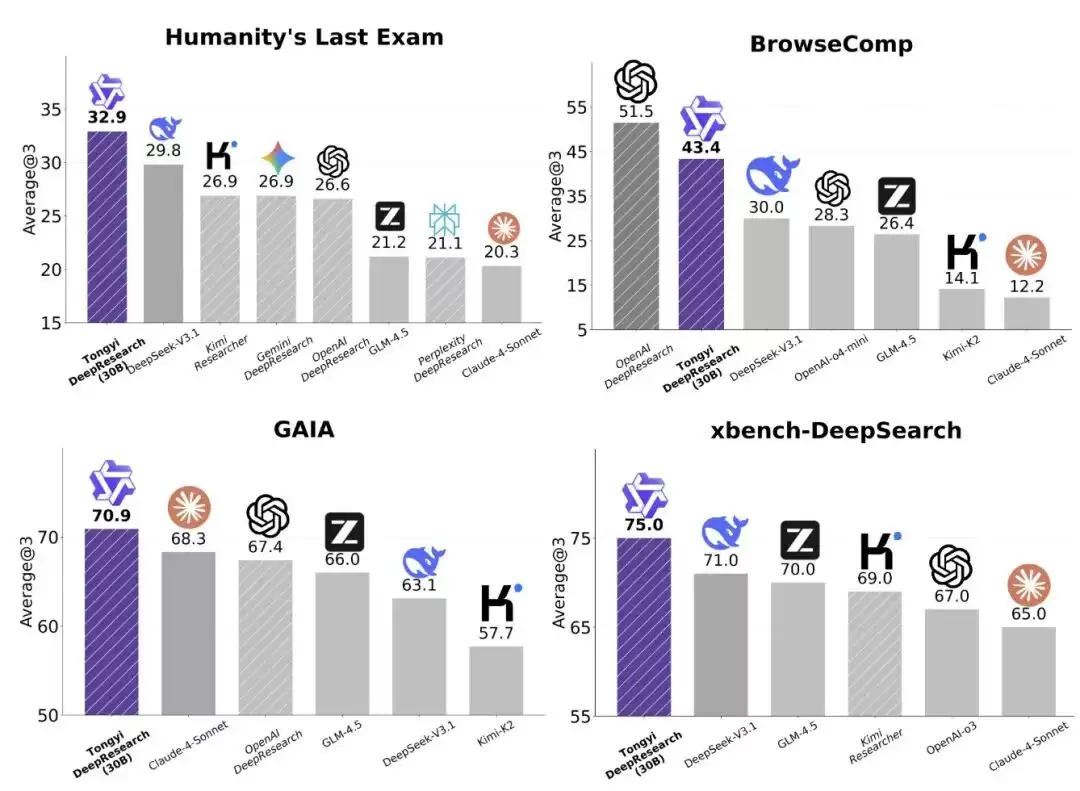
具体成绩如下:HLE基准测试得分32.9分,BrowseComp测试双项均超过43分,xbench-DeepSearch更是达到了75分。这一成绩在开源模型中相当亮眼。
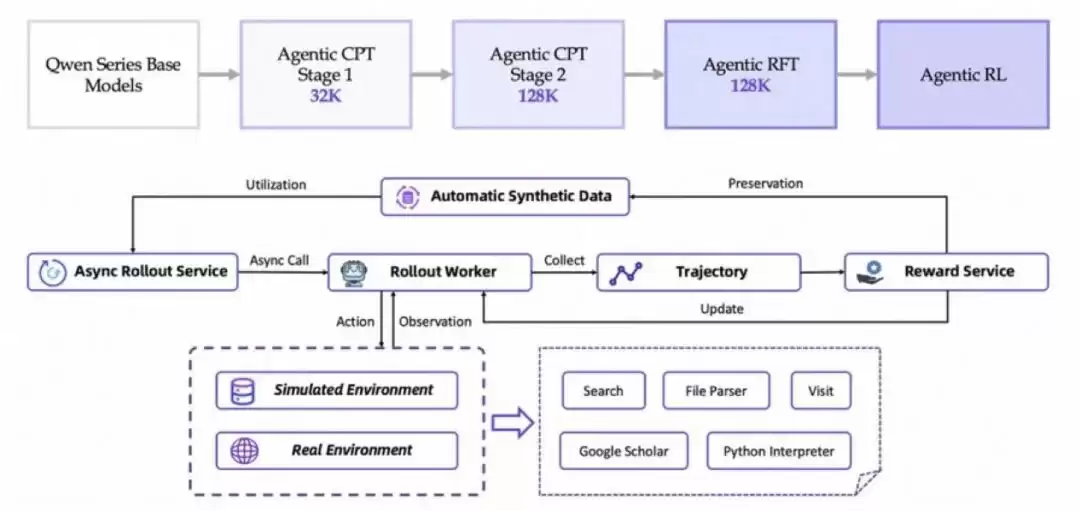
从技术角度看,它采用了从Agentic CPT预训练开始的全流程方案,支持原生的ReAct模式,并新增了一个Heavy模式。简单来说,就是让智能体既能“快速思考”也能“深度思考”,根据问题复杂度灵活切换策略。
项目相关资源链接如下,感兴趣的话可以自行查阅:
Hugging Face数据集:https://huggingface.co/datasets/Lk123/InfoSeek
GitHub代码库:https://github.com/VectorSpaceLab/InfoSeek
技术论文:https://arxiv.org/abs/2509.00375
通义博客:https://tongyi-agent.github.io/blog/introducing-tongyi-deep-research/
通义模型HuggingFace:https://huggingface.co/Alibaba-NLP/Tongyi-DeepResearch-30B-A3B




