微调大语言模型,尤其是为意图识别这类垂直场景进行定制优化,实际步骤并不如想象中复杂,但每个环节都有不少关键细节值得留意。下面我们将完整流程逐一拆解,从基座模型选型、参数调优到结果验证和常见踩坑点,一次性讲透。
一、微调流程
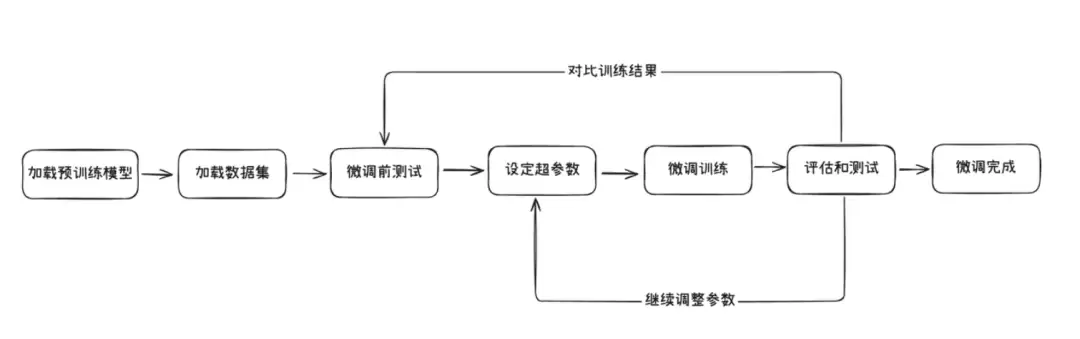
二、选择微调基础模型
在执行监督指令微调时,建议优先选择带 -Instruct 后缀的模型。这些后缀实际上隐含着模型的擅长方向与能力定位,具体的命名规则可参考下方两张截图。
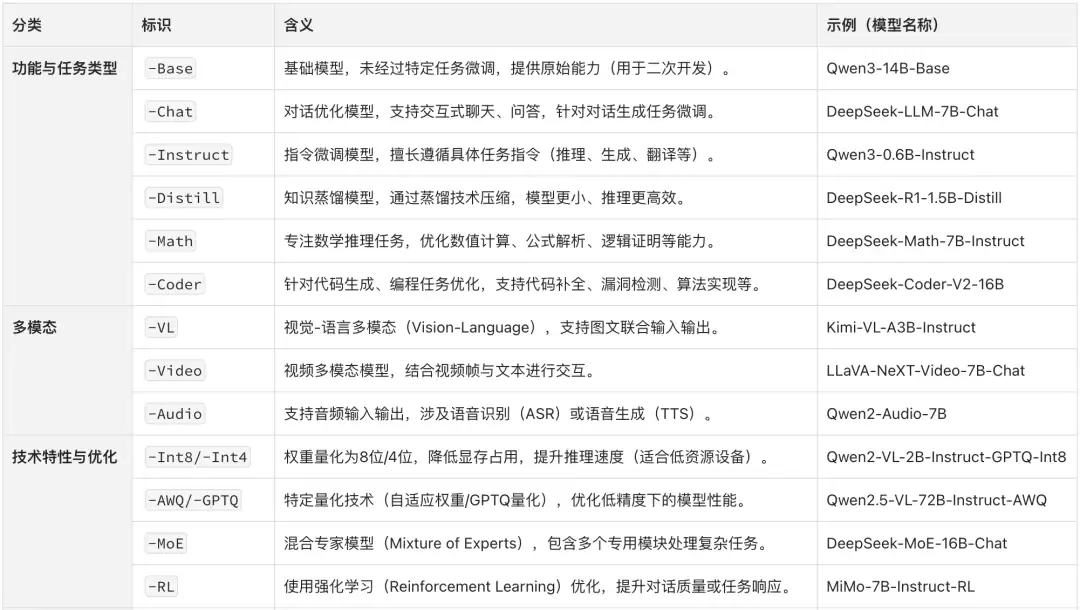
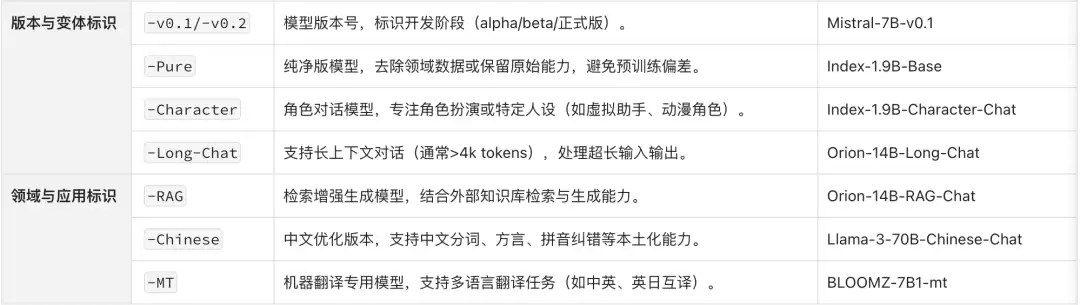
三、准备意图识别微调训练集与验证集
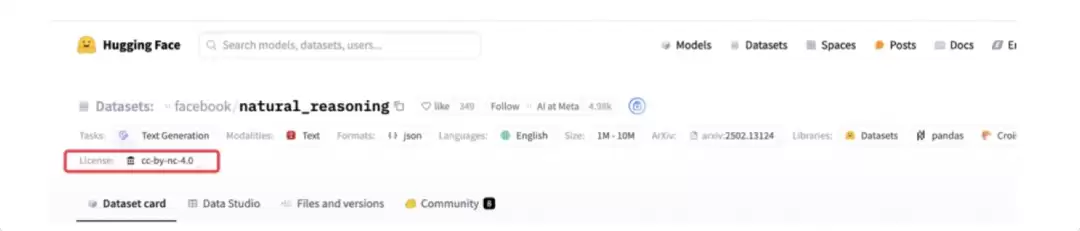
从 Hugging Face 等开源平台下载数据集时,有一个容易被忽略的点——务必仔细查看数据使用协议,尤其要确认是否支持商业用途。例如,Facebook 提供的推理数据集标注了 cc-by-nc-4.0 协议,那就仅限非商业场景使用。
### 训练数据集样例
[{"instruction":"你是一个意图识别专家,可以根据用户的问题识别出意图,并返回对应的意图和参数", "input":"我想听音乐", "output":"play_music()"}]
验证集可以直接从训练数据中随机抽取 10% 来使用,简单高效。
四、模型微调过程介绍
这里采用 LoRA 方法,借助 LlamaFactory 框架完成微调。下面是在 AutoDL 平台上的实际操作流程(温馨提示:AutoDL 的云主机关机后仅保留 15 天,长时间不用记得将数据下载到本地)。
1. 在平台上租用一块 RTX 4090D 显卡,选择 Llama-Factory 社区镜像启动实例。
2. 启动云主机的 Llama-Factory WebUI,然后通过 SSH 命令将 Web 页面通过端口映射到本地,在浏览器中即可看到如下界面。
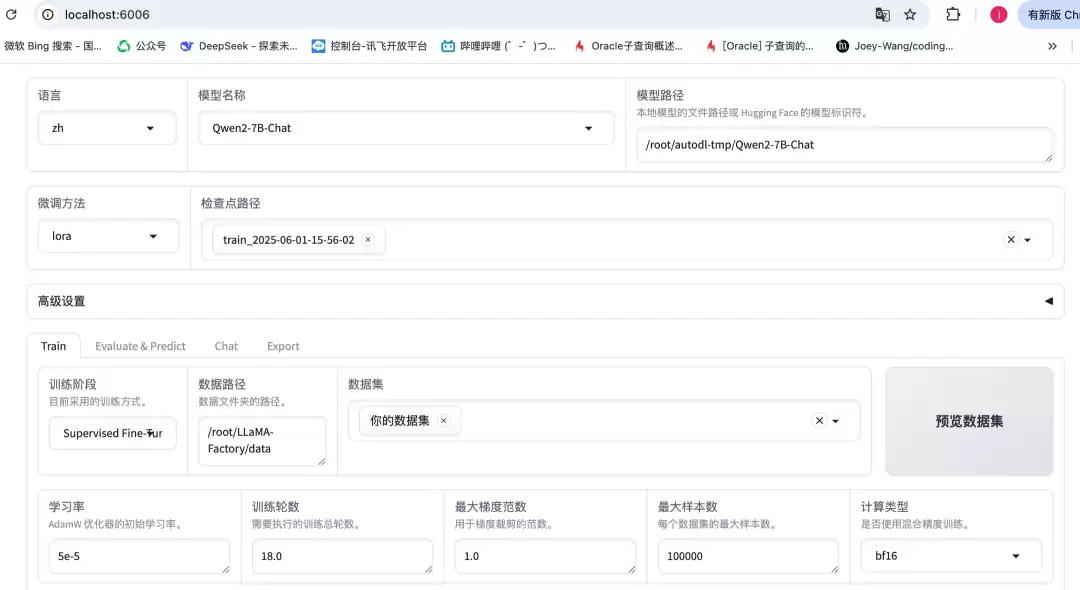
3. 加载数据集并进行基础模型训练。建议训练轮次控制在 10 个 epoch 以内,尽量在此范围内将 loss 拟合到 0.7~1.4 之间。
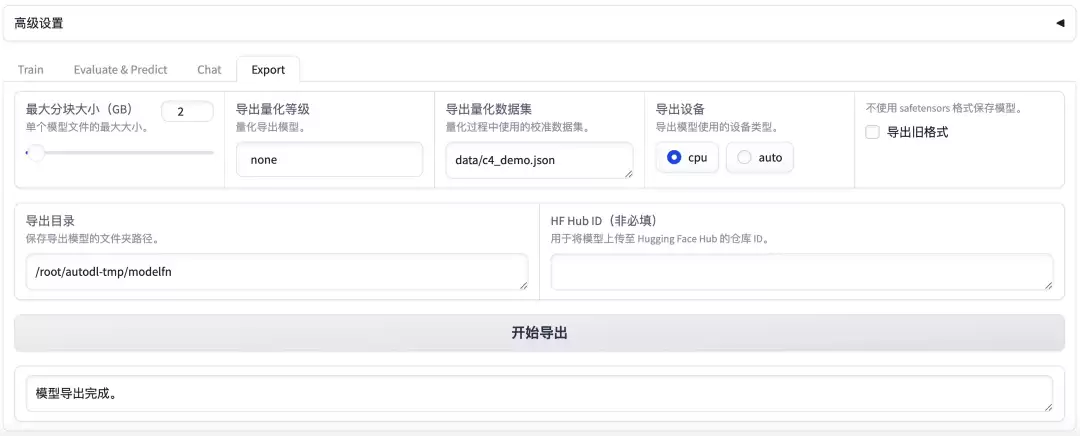
4. 在 Llama-Factory 页面中将模型保存到云主机的指定目录。
Google 的 Colab 平台也提供了免费显卡(需借助科学上网工具),操作步骤类似:

Colab 上的微调流程大致分为:从 Hugging Face 加载预训练模型 → 加载数据集 → 配置微调参数并执行训练 → 测试微调效果 → 将模型保存为 GGUF 格式 → 上传到 Hugging Face(需提前配置 access token)→ 最后用 ollama 运行微调后的模型。具体步骤和代码将在后续实操中详细介绍。
五、微调主要参数介绍
1. 学习率(Learning Rate)
学习率决定了每次参数更新的步长,通常取值范围在 (0, 1) 内。简单来说,它控制着模型学习的“速度”。学习率越大,参数调整幅度越大;越小则更新更稳健。
建议初始阶段采用较小的学习率,例如 5e-5 或 4e-5,然后根据模型实际表现逐步调整。尤其当数据集规模不大时,不要一开始就用 1e-4 或 2e-4 这类偏大的值。较小的学习率往往能实现更稳定的拟合,效果也更可控。
2. 训练轮数(Number of Epochs)
一个 epoch 表示模型完整遍历一次全部训练集。通常建议控制在 10 个 epoch 以内,最好在此范围内将 loss 降至 0.7~1.4。
3. 截断长度(Cutoff Length)
也称为 Max Length,决定了模型能接收的最大 token 数量。它直接影响模型对上下文信息的捕获能力以及显存占用。具体值应根据你自己的数据集平均长度来设定——数据长就适当调大,数据短就调小,不必死守固定数值。
4. 批量大小(Batch Size)与梯度累积步数(Gradient Accumulation Steps)
批量大小指每块 GPU 一次处理的样本数量。若只有一块 GPU,batch size 设为 16,那么每次就会处理 16 条数据。
梯度累积步数是一种实用的显存优化技巧。当你想使用较大的 batch size 但显存不足时,通过增加梯度累积步数,可以实现“分期付款”式的梯度更新。举例:目标 batch size 为 6,但显存仅支持 2,则可将梯度累积步数设为 3。实际流程是:先计算 2 个样本的梯度,暂不更新参数;再计算 2 个样本梯度,暂不更新;再计算 2 个样本梯度,然后与前两次累积的梯度合并更新。这样就以小显存实现了大 batch size 的效果。
对于 10B 以下的小模型,建议 batch size 设得小一些。如果数据集本身较少,batch size 还很大,很容易导致严重过拟合。可从 2 开始尝试,甚至从 1 开始也行——小 batch size 的拟合效果通常并不差。
5. LoRA 秩(LoRA Rank)
LoRA 中的秩决定了微调时参数更新的“表达能力”。秩越小,更新越保守;秩越大,能捕捉的特征复杂度越高,但显存消耗也越大。显存紧张时,优先降低秩(比降低 batch size 更有效)。例如从 16 降到 8,可能直接释放 30% 以上的显存。不过建议最低不要低于 8,否则会影响模型的学习效果。
六、模型微调后验证
使用预留的 10% 数据作为验证集。验证时可在输入中添加训练时使用的提示词,例如:
你是一个意图识别专家,可以根据用户的问题识别出意图,并返回对应的函数调用和参数。
关于自动评估微调后模型的具体方法,后续将补充说明。
七、训练过程中遇到的问题及计划
在公司内部的基础模型上进行意图识别微调时,发现微调后效果基本没有提升。接下来计划从以下三个方向优化:
1. 尝试切换不同的基础模型
2. 调整微调超参数
3. 优化微调数据集的质量与数量




