检索增强生成(RAG)之所以能成为当前大模型应用中最热门的技术路线,核心原因在于它在缓解模型幻觉问题上确实有一套。借助一些编排框架,快速搭建一个知识问答的原型应用并不是难事。但真正让开发者头疼的是:即便用上了RAG、构建了信得过的知识库,大模型依然会给出错误答案——原因可能是上下文不准确、信息错乱,或者压根儿就不完整。这些“幻觉”和不可靠性问题,正是当前AI应用真正落地投产时,绕不开的拦路虎。
最近,谷歌研究人员的一篇新论文《SUFFICIENT CONTEXT: A NEW LENS ON RETRIEVAL AUGMENTED GENERATION SYSTEMS》带来了一个全新的观察角度——“充分上下文”(Sufficient Context)。这项研究不只是停留在表面分析,而是深入剖析了RAG系统失败的底层原因,并提出了一套行之有效的解决方案。对于提升企业级AI应用的准确性和可靠性来说,这无疑是一份值得关注的成果。
RAG的困境
RAG系统在理想状态下是这样运作的:当提供给大语言模型(LLM)的上下文信息足以回答用户问题时,模型应该给出正确答案;如果信息不够,它应该选择“拒绝回答”或者主动请求更多信息。
然而现实情况远没有那么理想。此前的研究常常笼统地把问题归结为“检索质量不佳”或“上下文不相关”,但谷歌的论文明确指出,这种描述过于模糊。我们真正需要弄清楚的是:LLM犯错,到底是它没能理解上下文,还是上下文本身就不包含足够的信息?
为了精准回答这个问题,研究团队提出了“充分上下文”这个概念。
“充分上下文”是什么?
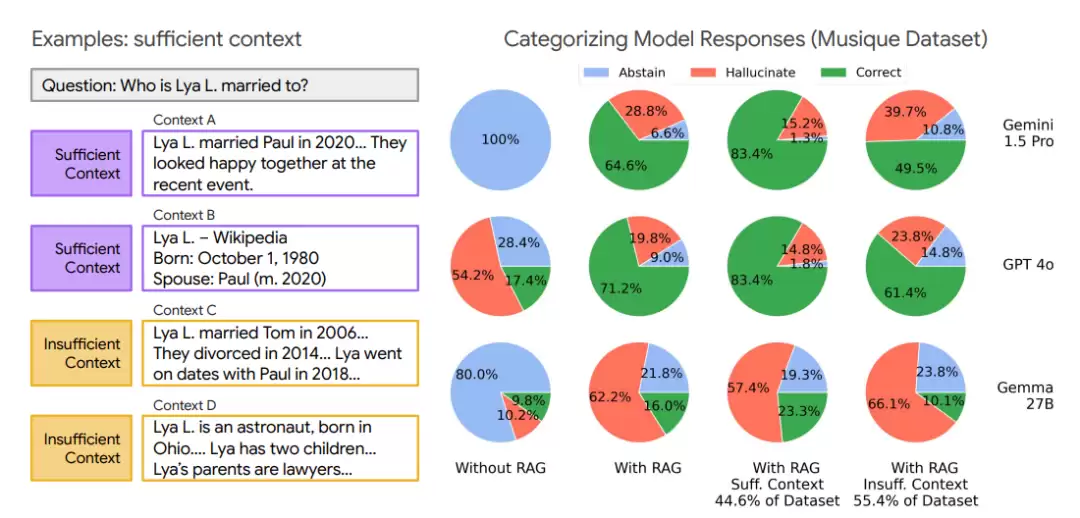
研究人员将输入给模型的“查询-上下文”对分成了两类:
充分上下文(Sufficient Context):指提供的上下文已经包含了回答用户查询所需的全部信息,模型可以据此给出明确的答案。
不充分上下文(Insufficient Context):指上下文缺少关键信息。可能的原因是信息不完整、存在矛盾,或者查询本身涉及到上下文中没有的专业知识。
这个分类的最大亮点在于:判断时不需要“标准答案”。也就是说,在真实世界应用场景里,即使无法提前知道正确答案,我们也能评估上下文的质量。
为了让这个判断过程自动化,研究团队开发了一个基于LLM的“自动评估器”(Autorater)。实验结果显示,谷歌的 Gemini 1.5 Pro 模型仅通过一个示例(1-shot)的提示,就能以高达93%的准确率判断上下文是否充分——这为大规模分析和应用打下了坚实基础。
三大关键发现:碘伏对RAG的传统认知
通过“充分上下文”这个新视角,研究人员对多种主流LLM(包括Gemini、GPT、Claude等)在不同数据集上的表现进行了深入分析,得出了几个令人意想不到的结论:
1. 即使上下文充分,模型依然会产生幻觉
这是最值得警惕的发现之一。很多人认为,只要检索到的信息正确、全面,模型就应该能答对。但数据显示,即使在“充分上下文”的情况下,模型产生幻觉(给出错误答案)的频率仍然高于它选择“拒绝回答”。这意味着,单靠优化检索系统远远不够,LLM自身的推理能力和利用上下文的水平同样关键。
2. RAG有时反而会降低“谦逊度”,让模型更不愿意承认自己不知道
与直觉相反,引入RAG虽然提升了整体准确率,但也让模型在信息不足时更倾向于“强行回答”而不是“承认无知”。研究人员推测:“可能是因为任何上下文的存在都会增强模型的自信心,导致它更容易产生幻觉,而不是拒绝回答。”
3. 即使上下文不充分,模型有时也能正确回答
这是一个相当有趣的现象。研究发现,即使上下文信息不够,模型偶尔也能给出正确答案。除了模型自身的“参数化知识”(即预训练时学到的知识),研究人员还发现了其他原因:不充分的上下文有时候能起到“消除歧义”或“弥补知识鸿沟”的作用,帮助模型更好地理解问题并作出推理。
正如研究的共同作者、谷歌高级研究科学家 Cyrus Rashtchian 所说:“一个优秀的RAG系统,其基础LLM本身也必须足够强大。检索应该被视为对其知识的‘增强’,而不是唯一的真相来源。”
如何减少幻觉?“选择性生成”框架应运而生
既然模型在信息不足时倾向于产生幻觉,我们该怎么引导它变得更“诚实”?研究团队提出了一个叫做“选择性生成”(Selective Generation)的新框架。
这个方法引入了一个独立的、更小的“干预模型”,结合模型自身的置信度和上下文是否充分这两个信号,来决定主模型应该生成答案还是拒绝回答。
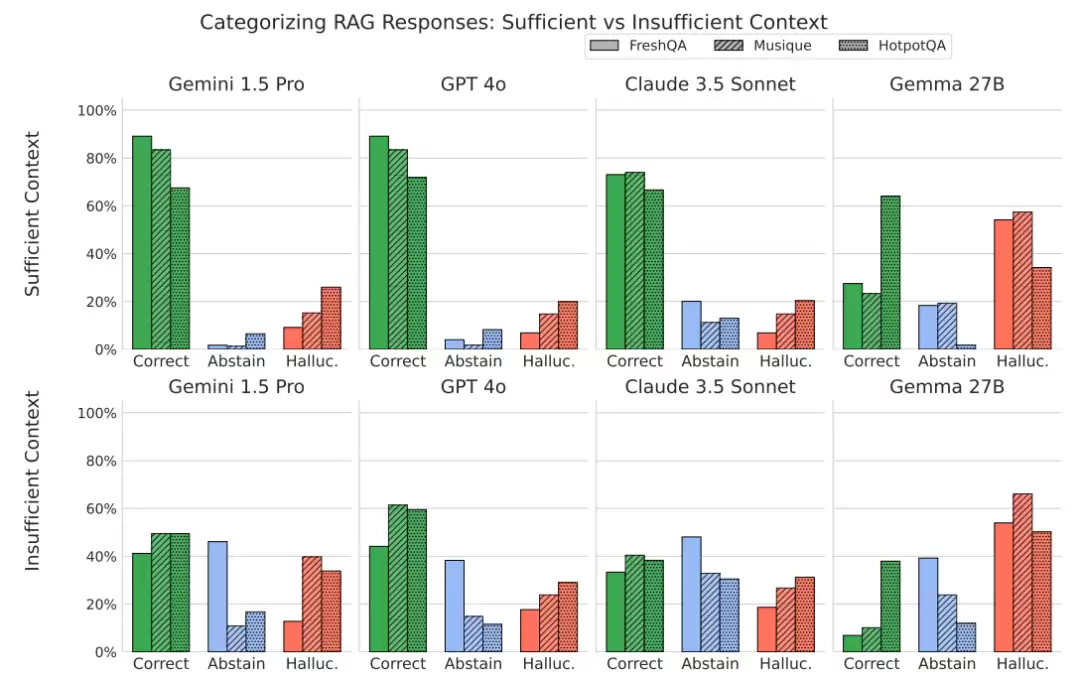
实验效果非常明显:该框架在不大幅牺牲回答覆盖率的前提下,将 Gemini、GPT 和 Gemma 等模型在回答问题时的正确率提升了2%到10%。
为了让这个提升更直观,Rashtchian举了一个客户支持的例子:“想象一个客户询问是否有折扣。如果检索到的上下文是关于当前正在进行的促销活动,模型可以自信回答。但如果上下文描述的是几个月前的旧活动,或者附带复杂的条款,那么模型最好回答‘我不确定,请联系人工客服以获取更具体的信息’。”“选择性生成”框架正是为了实现这种智能判断。
此外,研究团队也尝试了通过微调(fine-tuning)来教模型“拒绝回答”——在训练数据中将不充分上下文样本的答案替换为“我不知道”。但结果好坏参半,虽然模型的正确率有所提高,但幻觉问题依然严重。
给企业团队的实践指南
对于希望把这些洞见应用到自有RAG系统的企业团队,Rashtchian 提出了一个切实可行的四步法:
① 收集数据:收集一批能代表生产环境中真实情况的“查询-上下文”数据对。
② 自动标注:使用LLM自动评估器(Autorater)将这些样本标记为“充分”或“不充分”。
③ 诊断检索系统:分析标注结果。Rashtchian建议:“如果‘充分上下文’的比例低于80%-90%,那说明你的检索系统或知识库有很大的改进空间。这是一个非常好的可观察指标。”
④ 分层评估模型:分别评估模型在“充分上下文”和“不充分上下文”两类数据上的表现,而不是看一个总的平均分。Rashtchian指出:“这样能帮你发现那些在整体数据中被掩盖掉的重要但处理不佳的查询。”
虽然运行自动评估器会带来一些计算成本,但Rashtchian表示,对几百到一千个样本的离线诊断来说,成本相对较低。核心价值在于,它为团队提供了一个超越传统“相似度分数”的、更深刻的洞察信号。
小结
谷歌的“充分上下文”研究,清晰地指出了RAG系统失败的复杂性——问题不仅出在检索环节,更在于模型如何处理和判断所获得的信息。他们的核心发现以及“选择性生成”等创新方法,对致力于让RAG应用真正投入生产的开发者来说,确实带来了很大的启发。




