别急着搞多智能体,先把上下文搞明白
Multi Agent(多智能体)应用,正在成为大模型落地的一个热门范式。这个话题最近讨论得很多,尤其是Anthropic那篇关于如何构建生产级多智能体系统的最佳实践,相信不少人都看过。
但事情总有另一面。全球首位AI程序员Devin的幕后团队——Cognition AI,却对这个方向持不同看法。他们最近抛出了一个犀利的观点:在2025年这个时间点,追求让多个AI智能体并行协作,是一条极其脆弱、极易翻车的路。
为什么这么说?问题的核心,指向了一个词:上下文灾难。
- 信息孤岛: 并行工作的子智能体,彼此看不到进度和决策。就像几个蒙着眼睛的工匠各自做零件,最后风格无法统一,根本组装不起来。
- 决策冲突: 智能体的每一个动作,其实都暗含了“隐性决策”。多个智能体独立决策时,这些决策极大概率会相互打架,直接把整个项目带向混乱。
那出路在哪儿?Cognition AI 团队给出的答案是:别光想着加智能体,而是回归本质——搞透信息的管理和传递。他们主张用一种单线程的线性架构,确保信息流完整、连续,每一步行动都站在完整的历史背景上。遇到超长任务怎么办?他们提出的方案是用一个专门的模型来“智能压缩上下文”,而不是简单粗暴地把任务分包。
换个角度来说,上下文工程是地基,而多智能体是未来的上层建筑,两者并非二选一。但如果非要选一个更重要的,地基显然比空中楼阁更关键。低质量的扩展,带来的往往就是早期那些全自主Agent应用(比如GPTs)的命运——被模型能力的天花板卡住,又被系统复杂度压垮,最后难以落地。这就像Web架构里“单体 vs 分布式”的争论,早期分布式搞得不好,反而给了Dify、n8n这类过渡性产品生存和壮大的机会,也成就了当下最火热的Agent构建工具。
有时候,简单实用,远比“花哨”更重要。
以下,是Cognition AI团队原文《Don’t Build Multi-Agents》的全文编译,供参考。
上下文工程的原则
我们先梳理出要逐步阐明几个核心原则:
- 共享上下文
- 行动承载着隐性决策
- 我们为何要思考这些原则?
1993年,HTML诞生。2013年,Facebook发布了React。到了2025年,React(及其衍生技术)已经主导了开发者构建网站和应用的方式。为什么?因为React不只是一个写代码的脚手架,它代表了一种哲学。用React,意味着你接受了一种响应式、模块化的构建方式——如今大家都觉得这是基本要求,但在早期Web开发者眼里,这可不是什么理所当然的事。
在LLM和AI智能体的时代,我们感觉又回到了玩原始HTML和CSS的阶段,正摸索着如何把它们组合成更好的体验。除了最基础的概念外,目前还没有任何一种构建智能体的方法成为公认标准。
更关键的是,某些库(比如OpenAI的Swarm、微软的AutoGen)正在大力推广一种我认为是错误的方向——多智能体架构。接下来,我会详细解释为什么。
话说回来,如果你刚开始接触智能体构建,确实有不少关于搭脚手架的资源。但要说到构建严肃的生产级应用,那完全是另一回事了。
构建长时运行智能体的理论
聊可靠性。当智能体需要在长时间运行中保持可靠、维持连贯的对话时,你必须想办法控制复合错误的潜在风险。否则一不留神,系统就会迅速崩塌。而可靠性的核心,就是上下文工程。
什么是上下文工程?
2025年的模型已经极其聪明了。但再聪明的大脑,如果缺少任务上下文,也很难把事干好。过去我们发明了“提示工程”这个词,说的是如何为LLM聊天机器人写出理想格式的任务指令。而“上下文工程”则是它的下一代升级——它要在一个动态系统里自动完成这件事。它需要更精细的把握,实际上,这是所有AI智能体工程师的首要和核心工作。
举个例子,常见的一种智能体类型是这么干的:
- 先把工作拆成几块
- 启动子智能体来处理这些任务
- 最后合并结果
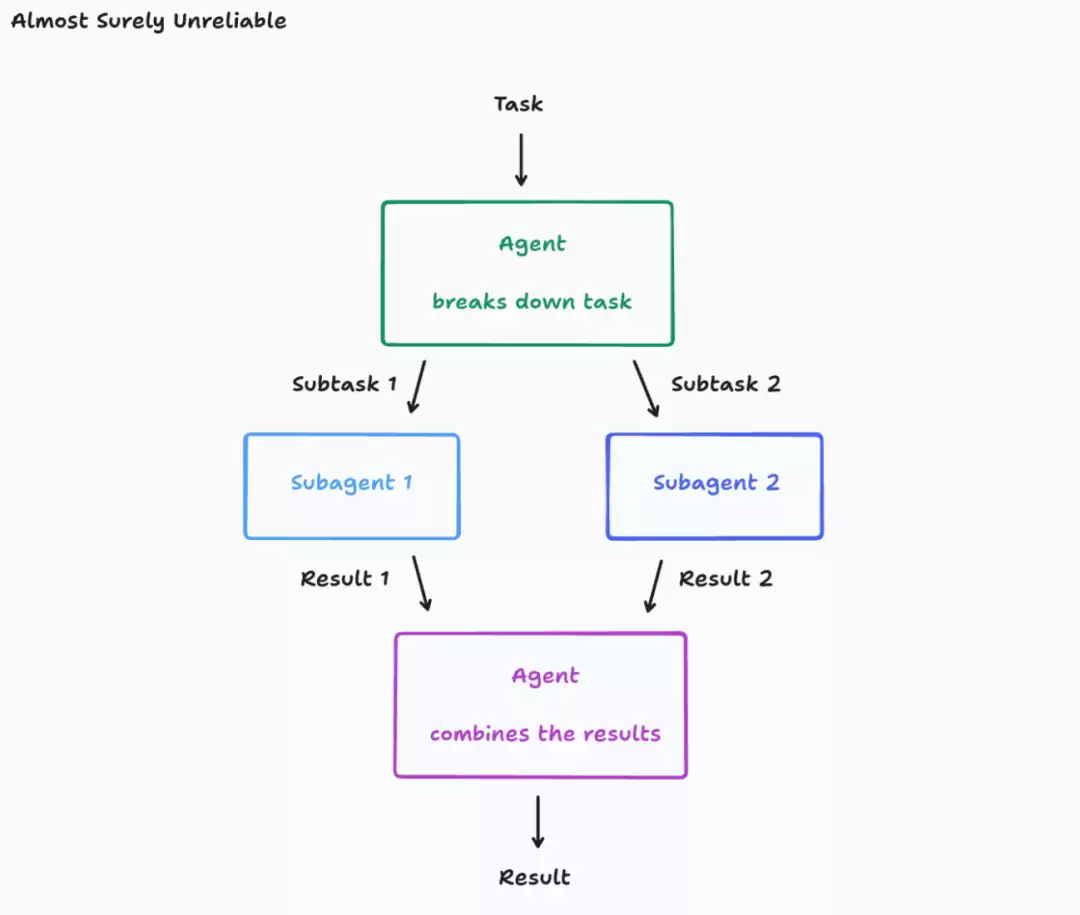
这个架构很诱人,尤其当你的任务包含多个并行组件时。但它非常脆弱。关键的风险在于:看起来像是刻意编造的,但现实中的大多数任务都包含着许多层次的细微差别,每一个细节都可能被误解。你可能会想,把原始任务上下文也复制给子智能体,不就解决了?但注意,在真实的生产系统里,对话是多轮的,智能体可能要调用工具才能决定怎么拆任务,任何细节都会影响对任务的解读。
原则一:共享上下文,而且是完整的智能体追踪记录,而非孤立信息。
让我们重新看看这个智能体,这次确保每个子智能体都拿到了前序智能体的上下文。
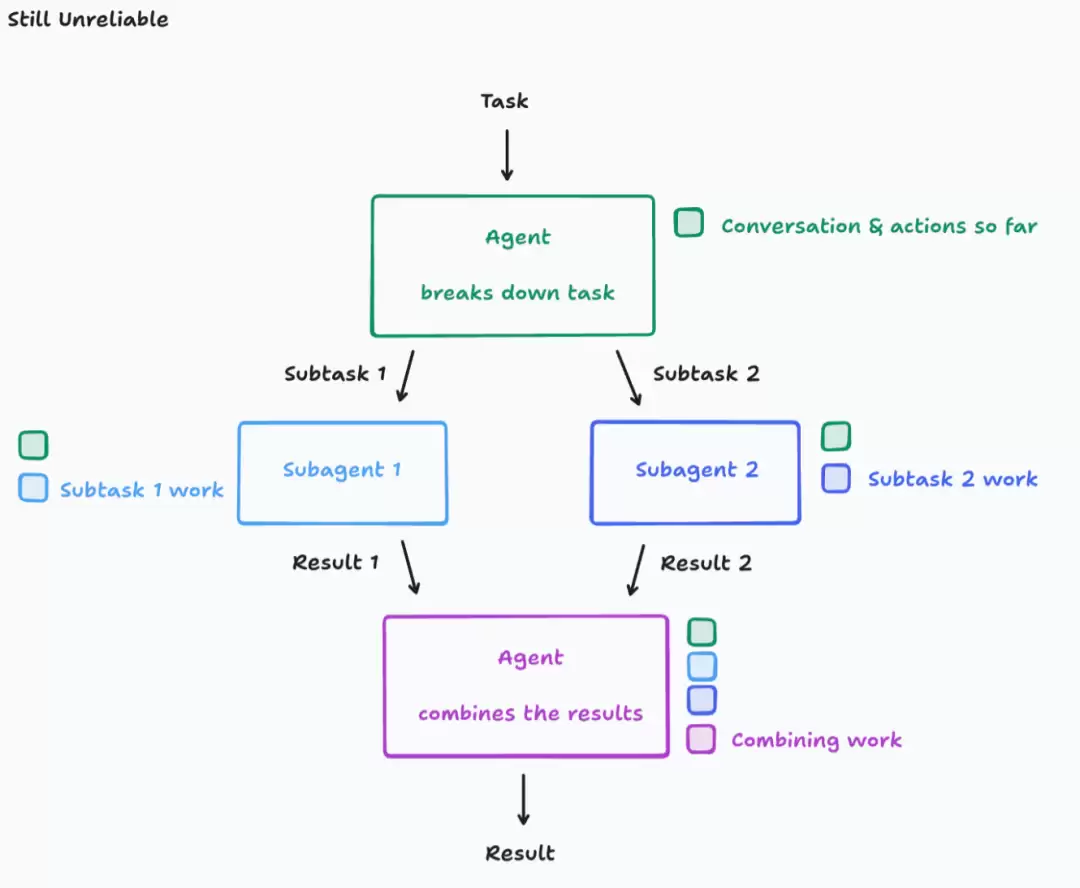
不幸的是,问题还在。当你给它们同一个Flappy Bird克隆任务时,你可能会得到一只鸟和一个背景,但它们的视觉风格完全不一样。子智能体1和子智能体2看不到对方在做什么,最终工作不一致。
子智能体1和子智能体2采取的行动,基于事先没有明确规定的、相互冲突的假设。
原则二:行动承载着隐性决策,冲突的决策导致糟糕的结果。
原则1和原则2如此关键,几乎不值得去违背它们。所以,你默认就应该排除任何不遵守这些原则的智能体架构。你可能会觉得这限制太多,但实际上,你仍然可以探索广阔的架构空间。
遵循这些原则最简单的方法,就是使用单线程的线性智能体:
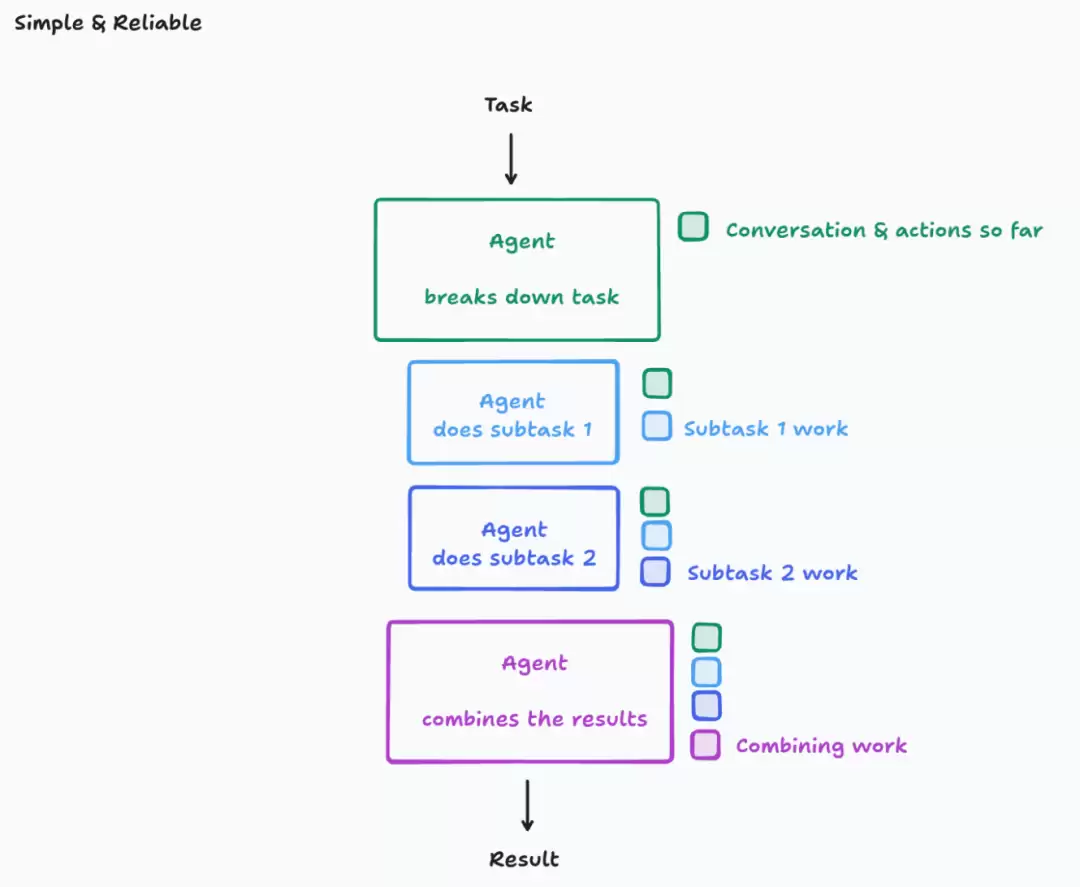
在这里,上下文是连续的。但对于子部分非常多的大型任务,你可能会遇到上下文窗口溢出的问题。

说实话,简单的架构就能让你走得很远。但对于那些真正面临超长任务、且愿意投入精力的人来说,你们可以做得更好。解决这个问题的方法不止一种,我今天只介绍其中一种:
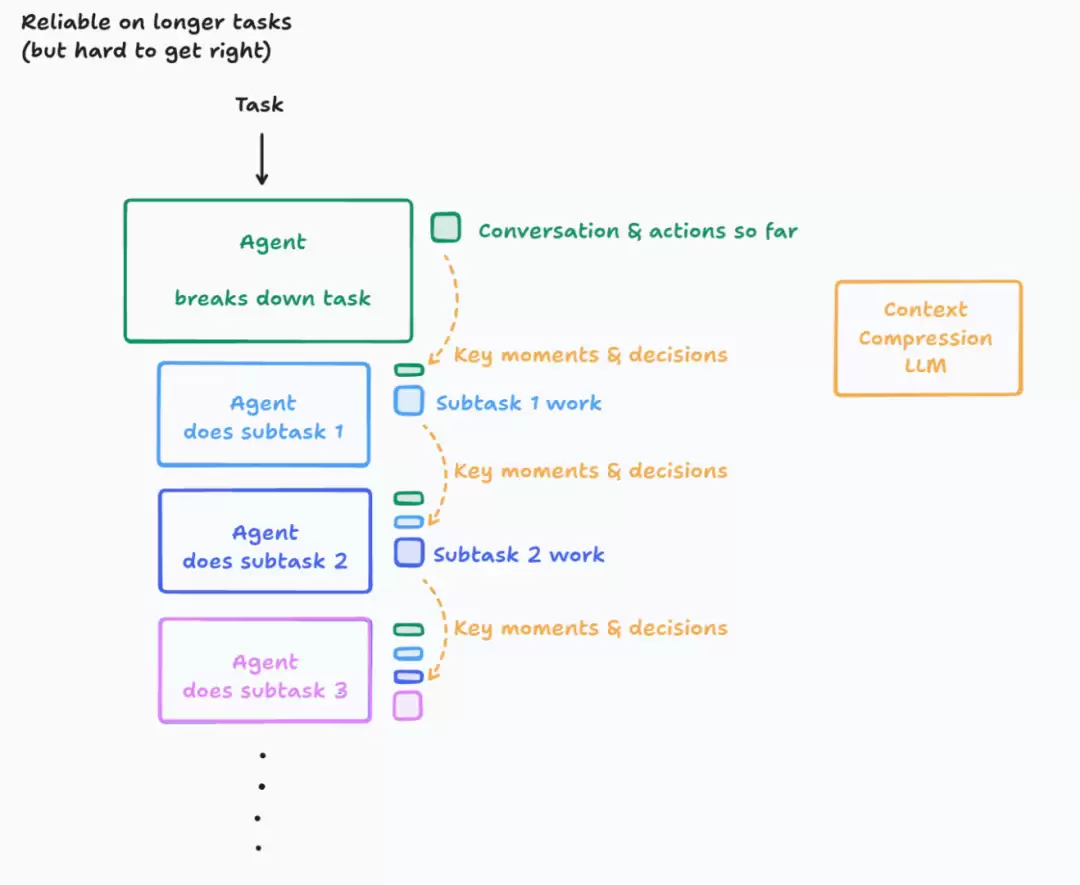
在这个方案里,我们引入一个新的LLM模型,它的核心任务是:把行动和对话的历史,压缩成关键细节、事件和决策。这并不容易做好,需要投入精力去弄清楚哪些信息最终是关键,并创建一个擅长此事的系统。根据领域不同,你甚至可以考虑微调一个更小的模型——事实上,这正是我们在Cognition做的事情。
你得到的好处,是一个能有效处理更长上下文的智能体。不过,最终还是会达到一个极限。对这个方向感兴趣的读者,我鼓励你们思考更好的方法来管理任意长的上下文——这最终是一个相当深的兔子洞。
应用原则
如果你是智能体构建者,请确保你的智能体的每一个行动,都基于系统中其他部分所做的所有相关决策的上下文。理想情况下,每个行动都应该能看到其他所有东西。但很遗憾,由于上下文窗口有限和实际权衡,这并不总是可能做到。你需要决定,为了你追求的可靠性,你愿意承担多大的复杂性。
在思考如何设计智能体架构以避免决策冲突时,以下现实案例可供参考:
- Claude Code的子智能体: 截至2025年6月,Claude Code是一个会生成子任务的智能体范例。但它从不与子任务智能体并行工作,而且子任务智能体通常只负责回答一个问题,而不是编写代码。为什么?因为子任务智能体缺乏主智能体的上下文,而这种上下文对于执行超出回答一个定义明确问题之外的任务是必需的。如果并行运行多个子智能体,就可能给出相互矛盾的响应,导致文章前面提到的可靠性问题。Claude Code的设计者刻意选择了一种简单的方法。
- 编辑-应用模型: 2024年,许多模型在编辑代码方面表现很差。编码智能体、IDE、应用构建器(包括Devin)中一个常见的做法是“编辑-应用模型”。核心思想是:让一个小模型根据你想要的更改的Markdown解释来重写整个文件,实际上比让一个大模型输出格式正确的差异补丁更可靠。因此,构建者让大模型输出代码编辑的Markdown解释,然后给到小模型来实际重写文件。但这类系统仍然极易出错,小模型常常因为指令中微小的含糊不清而误解大模型的指令,做出错误编辑。如今,编辑决策和应用执行更常由单个模型在一次行动中完成。
- 多智能体: 如果真想从系统中获得并行性,你可能会想:让决策者们互相“交谈”解决问题?这是人类在出现分歧时的理想做法。工程师A的代码与工程师B的代码发生合并冲突时,正确的流程是讨论分歧并达成共识。然而,今天的智能体还远不能以比单个智能体高出很多的可靠性,来执行这种风格的长上下文、主动式对话。人类在沟通最重要知识方面效率很高,但这种效率需要非凡的智能。
自ChatGPT推出后不久,人们就开始探索多个智能体交互实现目标的想法。虽然我对协作的长期可能性持乐观态度,但很明显,在2025年,运行多个协作的智能体只会产生脆弱的系统。决策过于分散,上下文无法在智能体之间得到彻底共享。目前,我没有看到有人投入专门的努力来解决这个困难的跨智能体上下文传递问题。我个人认为,当我们让单线程智能体在与人类沟通方面做得更好时,这个问题将迎刃而解。当那一天到来时,它将释放出更大的并行性和效率。
迈向更通用的理论
这些关于上下文工程的观察,仅仅是未来可能被认为是构建智能体标准原则的开端。还有许多未在此处讨论的挑战和技术。在Cognition,构建智能体是我们思考的一个关键前沿。我们围绕这些反复学习的原则来构建内部工具和框架,以此来强化这些理念。但我们的理论可能并不完美,我们预计随着领域的发展,情况会发生变化,所以也需要保持一定的灵活性和谦逊。
原文:https://cognition.ai/blog/dont-build-multi-agents




