今日,智谱正式公开了GLM-5技术报告。当整个行业还在为参数规模和上下文窗口争得面红耳赤时,这份报告悄然把大模型的核心竞争力,引向了一个更本质的方向——如何让AI真正学会"学习"。
对开发者来说,大模型的痛点从来都很具体:写代码时,它能快速生成片段,却很难独立完成一个完整项目;做交互时,它能精准回应单轮提问,却在长周期任务里频频"掉线"。这些问题的本质,不是模型不够"聪明",而是它的学习方式,还停留在"复刻已知",而非"探索未知"。
GLM-5的出现,就是要打破这个僵局。
三层RL架构:让大模型在交互中进化
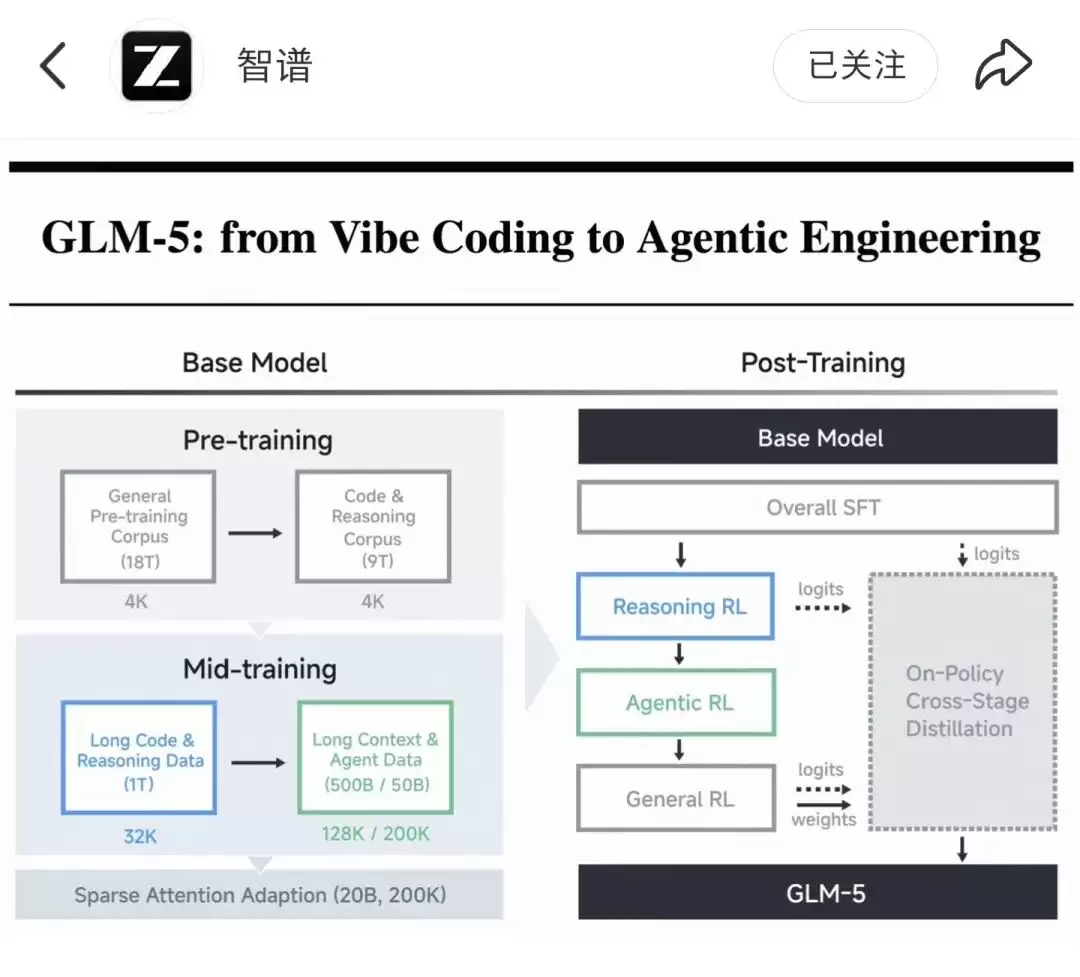
在GLM-5的后训练流程里,Reasoning RL、Agentic RL、General RL三层强化学习,构成了它的核心骨架。这不是简单的技术堆叠,而是一套完整的"学习闭环"。
Reasoning RL让模型在推理过程中不断校准逻辑,避免在复杂问题上"想当然";Agentic RL则专注于长周期交互,让它在多步骤任务里学会拆解目标、规划路径;而General RL则负责把这些能力泛化到更多场景,让模型不只是"会做",更是"会学"。
这种设计,让大模型从"被动输出",变成了"主动试错"的智能体。就好比一个新手工程师,在一次次项目迭代中积累经验,而不是永远停留在"照抄模板"的阶段。
异步RL基础设施:效率翻倍,进化加速
为了支撑这套复杂的RL架构,GLM-5构建了全新的异步RL基础设施。它把"生成"和"训练"彻底解耦,让模型在迭代时不再需要等待完整的生成过程,训练效率直接翻倍。
这意味着,同样的时间里,GLM-5能经历更多次"试错-学习"的循环,更快地优化策略。大模型不再是笨重缓慢的系统,而是能快速适应新任务、新场景的"敏捷学习者"。
而DSA(稀疏注意力适配)技术,则为这种高效学习提供了基础。200K的上下文窗口,让它能在超长信息里精准定位关键,不会因为任务复杂就"失忆",也不会因为成本高昂就"妥协"。
Agent RL:从"响应"到"规划"的质变
优化后的Agent RL算法,是GLM-5最具碘伏性的突破。它不再是你说一步、它动一下的工具,而是能主动拆解目标、制定步骤、长期执行的"队友"。
接到一个开发任务,它会先分析需求、设计架构、编写代码、测试优化,而不是只输出一段孤立的函数;参与一个复杂交互,它会记住历史信息、预判用户需求、调整自身策略,而不是每次都从零开始。
这种"规划能力",才是大模型从"生成工具"走向"智能体"的关键。当AI能像人一样,为了一个长期目标,在试错中调整策略,在交互中优化方案,它的价值就不再局限于"辅助",而是真正成为"伙伴"。
过去,我们用大模型,是在"指挥工具";未来,我们用大模型,是在"合作队友"。它能帮我们完成闭环项目,能在复杂交互中持续进化,能在陌生场景里主动试错——这才是AI真正的价值。
当大模型的学习方式被彻底改写,我们离真正的智能体时代,就又近了一步。




