先说说我对这件事的整体判断:大模型反向优化传统算法,并不是要替代谁、碘伏谁,而是提供了一种“让老家伙学新技能”的路径。传统算法不是不好,它在很多场景下高效、稳定、可解释,但短板也摆在那里——逻辑写死了就变不了,参数设定了就不会自适应,遇到复杂场景就抓瞎。大模型恰好补齐了这一环:它能诊断出传统算法的病根,开出药方,然后让算法自己按方抓药、迭代升级。
打个比方:传统算法就像一个用惯了固定路线跑送货的老司机,路线图背得滚瓜烂熟,可一旦遇到临时修路、天气变化,就不知道怎么绕了。大模型优化,相当于给老司机装了个实时路况导航,不仅告诉他前面堵了,还能规划出最优绕行路线。所以,这不是换司机,而是升级工具。
一、反向优化传统算法
1. 基础概念定义
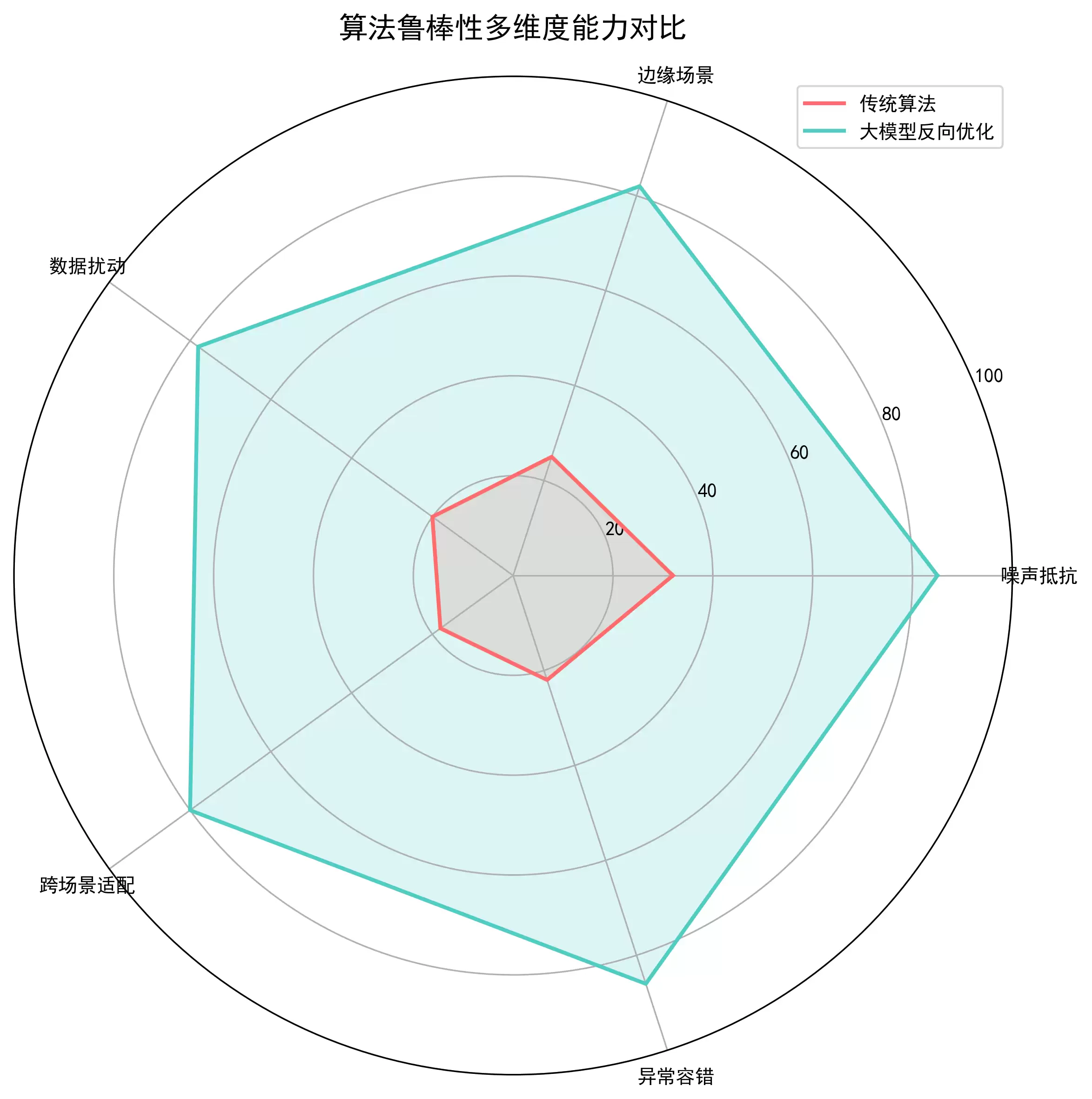
大模型反向优化传统算法,简单来说,就是以大模型为智能大脑,先精准识别出传统算法在特定场景下的固有缺陷、性能瓶颈、逻辑漏洞,然后利用大模型的泛化学习、逻辑推理和参数优化能力,反过来重构执行逻辑、调整核心参数、补充缺失规则——最终让传统算法突破原生设计的限制,在精度、效率、鲁棒性上全面升维。
这里面有几个关键区别需要先说清楚:
传统算法是“固定逻辑的执行者”,按照预设的规则照章办事,遇到复杂、动态、非标准化的场景,就容易失效。大模型呢,是“具备理解与推理能力的决策者”,它能看明白算法哪儿做错了、为什么做不好,然后反过来告诉算法应该怎么改逻辑、怎么调参数才能做得更好。整个过程形成了“算法运行→大模型诊断缺陷→反向迭代算法→算法再优化”的闭环。
这里有个容易混淆的地方。大模型替代传统算法,是用大模型直接取代传统算法的功能,比如直接用大模型做图像识别,抛弃传统的SIFT算法。而大模型反向优化传统算法,是保留传统算法的核心优势——低算力、高可解释、实时性强,同时用大模型来弥补它的短板。二者是共生进化,不是替代关系,这也是反向优化的核心价值所在。

2. 理解反向优化
“反向”是相对于人工优化而言。人工优化的流程是:人类先分析算法缺陷,再手动改代码、调参数。而大模型反向优化,是算法先输出结果,大模型通过结果对比、场景分析自主定位缺陷,然后直接输出优化后的算法逻辑或参数,中间不需要人去分析那些复杂的技术细节。
“优化”这个词,包含三层含义:一是修复算法逻辑漏洞,二是提升算法精度和效率,三是增强算法对场景的适应能力。
3. 技术核心价值
首先,它突破了传统算法的人工设计天花板。传统算法的性能上限取决于开发者的经验,而大模型能发现那些连资深工程师都容易忽略的隐性缺陷——比如边缘场景下的逻辑疏漏、参数的局部最优解,从而实现算法的自动化进化。
其次,降低了算法优化的门槛。开发者不需要精通底层数学原理,大模型可以完成缺陷诊断和逻辑迭代,让一个初学者也能优化工业级算法。
第三,兼顾了效率与智能。传统算法低算力、高实时性的优势被保留下来,同时大模型赋予其智能适配能力,解决了实时性与智能性难以兼得的行业痛点。
最后,实现了动态适配复杂场景。传统算法用固定规则应对动态数据,往往力不从心,而大模型可以实时反向迭代算法逻辑,让算法随着场景变化自适应调整。
4. 与人工优化的差异
5. 适用场景边界
大模型反向优化并不是万能药,它主要适用于那些有明确输入输出、缺陷可以量化、传统算法存在固定短板的场景。
在工业场景中,可以优化传统控制算法的参数、修复缺陷检测算法的逻辑;在数据处理领域,可以提升传统排序或搜索算法的效率、提高聚类算法的精度;图像处理方向,可以增强边缘检测、图像分割等算法的鲁棒性;在业务算法中,可以补充推荐算法、风控算法的规则漏洞。
但也有不适用的情况:没有明确评价标准的算法,超轻量级的嵌入式算法(因为算力撑不起与大模型的交互),以及那些完全确定性的底层基础算法,都不太适合走这个路线。
二、反向优化的技术基础
1. 传统算法的缺陷体系
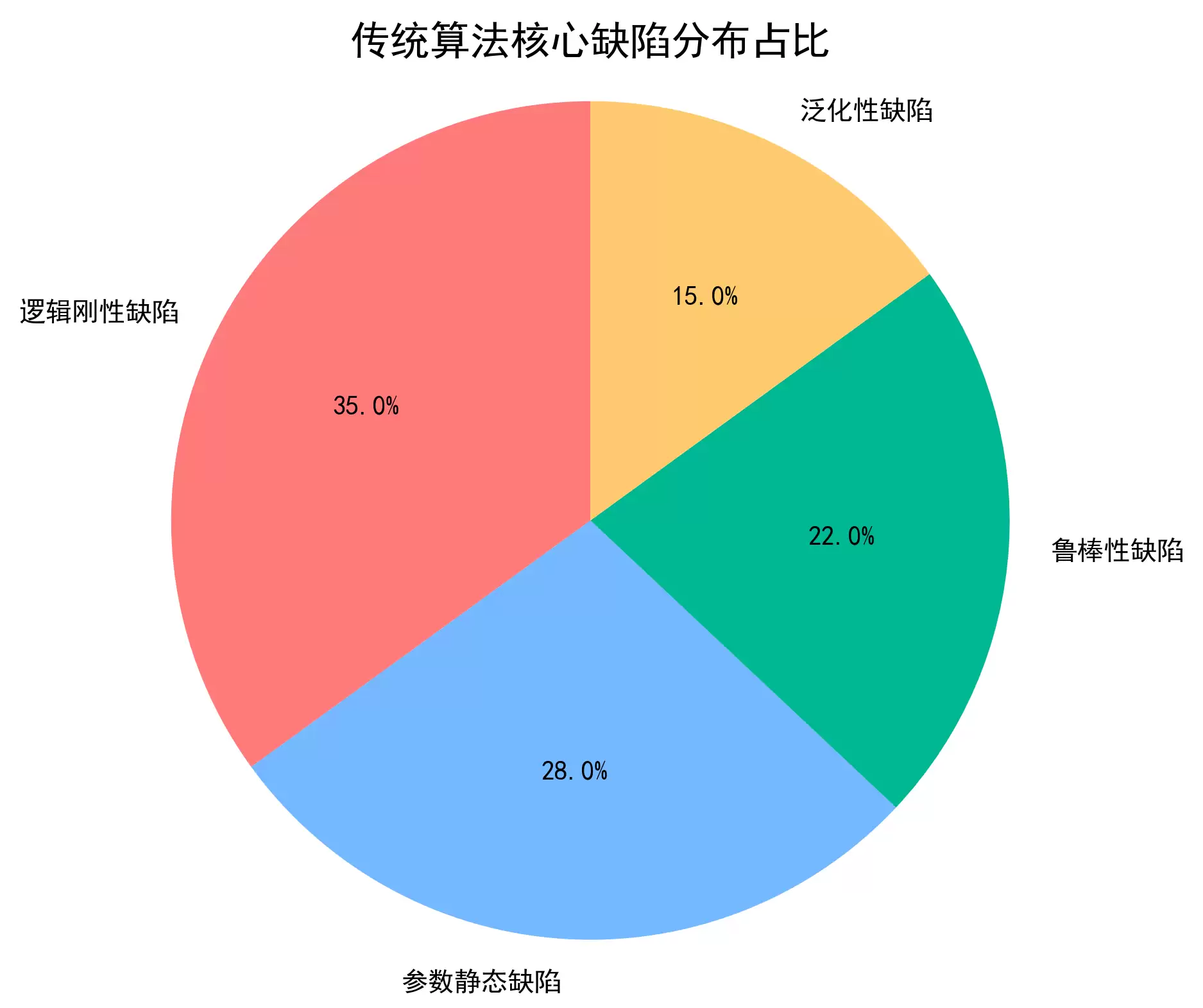
要理解大模型怎么反向优化,首先得摸清楚传统算法的四类固有缺陷。这是大模型诊断和优化的靶点,也是整个反向优化的前提。
1.1 逻辑刚性缺陷
传统算法的逻辑是硬编码的——写死了什么规则,算法就执行什么规则,规则之外的场景一概处理不了。举个例子:传统的阈值分割图像算法,通常固定灰度阈值为127,在正常光线下跑得挺好,但一到强光或弱光环境就直接失效。二分查找算法也类似,必须依赖有序数组,数据一乱就报错。这类缺陷的本质,就是算法没有自主判断能力,不会根据输入数据的变化调整执行逻辑。
1.2 参数静态缺陷
核心参数是人工预设、静态固定的,不会跟着数据分布或场景变化动态调整。比如K-Means聚类算法,K值要人工指定,数据分布一变,固定K值下的聚类精度就大幅下降。再比如A*路径规划,启发函数权重写死了,碰到复杂地形就容易跑出冗余路径。这类问题的本质是:参数只考虑了局部最优,而不是全局自适应的最优解。
1.3 鲁棒性缺陷
传统算法对噪声数据、异常数据、非标准化数据的容忍度很低——稍微有点数据扰动,结果就可能跑偏。举个例子:快速排序在遇到完全有序或完全逆序的数据时,时间复杂度会从O(nlogn)跌到O(n²)。Canny边缘检测算法在图像有噪声时,会检测出大量虚假边缘。这类缺陷的根源在于,算法没有抗干扰能力,完全依赖数据的绝对标准化。
1.4 泛化性缺陷
传统算法只能在设计时针对的特定场景下运行,跨场景迁移能力非常差。比如,针对“人脸正面图像”设计的特征提取算法,换到“人脸侧面图像”场景,提取精度直接断崖式下跌。针对“电商订单数据”设计的排序算法,换到“金融交易数据”上,效率也会大幅降低。说到底,算法没有场景学习能力,只能靠场景的固定性来运行。
1.5 缺陷量化方法
大模型反向优化,第一步就是把缺陷量化成可计算的指标。常用的量化指标有:精度指标(错误率、准确率、召回率,适用于分类和检测算法);效率指标(时间复杂度、运行时长、内存占用,适用于排序和搜索算法);鲁棒性指标(噪声扰动后的精度下降率,适用于图像处理和控制算法);泛化性指标(跨场景精度衰减幅度,适用于业务算法)。
2. 大模型反向优化的能力
大模型之所以能完成“缺陷诊断→逻辑迭代”的反向优化,靠的是四大底层能力。这些能力,传统算法确实不具备,也替代不了。
2.1 缺陷自主诊断能力
大模型通过对比学习、结果推理、规则复盘,不需要人工标注,就能自主定位传统算法的缺陷类型、位置和原因。原理是:大模型在预训练阶段学过了海量的算法逻辑、数据规律和优化案例,当输入传统算法的输入数据、输出结果和运行日志后,它会通过语义理解和逻辑推理,匹配缺陷模式,生成缺陷诊断报告。比如,输入快速排序在有序数组下的运行数据,运行时长10秒,大模型能自主诊断出“算法因输入数据有序出现时间复杂度退化,核心原因是基准值选择逻辑固定”。
2.2 算法逻辑推理能力
大模型具备类人类的数学推理、逻辑推演和代码重构能力,能根据缺陷原因,反向推导出优化后的算法逻辑。这主要靠Transformer架构的长文本理解和逻辑关联能力——大模型可以理解算法底层的数学原理,结合缺陷靶点,生成修复漏洞、动态适配的新逻辑。比如针对快速排序的基准值缺陷,大模型能推理出“三数取中法”来优化,而不是继续用固定基准值。
2.3 自适应参数生成能力
大模型能根据数据分布、场景特征、运行环境,动态生成最优参数,替代传统人工预设的静态参数。它通过对输入数据进行特征提取(比如数据有序度、聚类密度、图像亮度),匹配出最优参数区间,然后输出自适应参数值。举个例子,对于阈值分割算法,大模型能根据图像实时亮度,动态生成50到200之间的自适应阈值,而不是固定用127。
2.4 迭代闭环控制能力
大模型能持续监控优化后算法的运行结果。如果新结果仍有缺陷,它会再次优化逻辑,形成“诊断→优化→验证→再优化”的全自动闭环。这个闭环靠的是大模型的实时交互和反馈学习能力——它把优化后的算法结果作为新输入,不断修正优化策略,直到算法指标达标。
3. 传统算法与大模型的协同
反向优化的核心是协同,不是替代。两者的分工很明确:传统算法管底层执行,发挥低算力、高实时性的优势来完成核心任务;大模型管上层决策,靠智能能力来诊断缺陷、输出优化逻辑或参数。协同流程走的是:传统算法运行→输出结果→大模型诊断缺陷→输出优化方案→传统算法加载优化方案→重新运行→结果达标。
这种模式的好处是,既保住了传统算法的实用性,又给它装了智能引擎——这才是反向优化的底层逻辑。
三、反向优化的核心原理
1. 缺陷逆向溯源原理
核心逻辑很简单:从算法的错误结果出发,反向追溯到逻辑和参数的源头。传统算法是“输入→逻辑→输出”,而大模型反向优化走的是“输出错误→逆向拆解逻辑→定位错误节点→修正节点”。技术上说,大模型通过分析算法的运行日志、中间变量、输入输出对比,拆解整个执行链路,逐一排查每个模块的输出,精准定位缺陷节点。
2. 逻辑自适应重构原理
目标是打破传统算法的硬编码逻辑,用大模型的动态规则替代静态规则。传统算法的逻辑是固定的,而大模型会根据输入数据的特征,实时重构算法的执行逻辑,让算法随数据而变。具体来说,大模型把算法逻辑转化为语义化规则,通过自然语言处理动态修改这些规则,再把语义规则转化为可执行代码,完成逻辑重构。
3. 参数全局寻优原理
替代人工试错法,用大模型实现参数的全局最优搜索。传统算法的参数是人工预设的局部最优解,大模型则通过对数据特征的分析,在全局参数空间里搜索最优参数,避免陷入局部最优的陷阱。技术上,大模型结合了遗传算法、粒子群等启发式搜索算法,能在参数空间中快速收敛到全局最优值,然后输出给传统算法。
4. 闭环迭代进化原理
一次优化不等于最终优化,持续迭代才能让算法无限逼近最优。算法的运行环境和数据分布是动态变化的,单次优化后的算法可能又产生新缺陷。大模型通过持续监控和持续优化,让算法实现闭环进化。具体做法是:大模型搭建实时监控模块,定时采集算法运行指标,当指标超过阈值时,自动触发新一轮优化,形成无限迭代闭环。
四、反向优化的执行流程

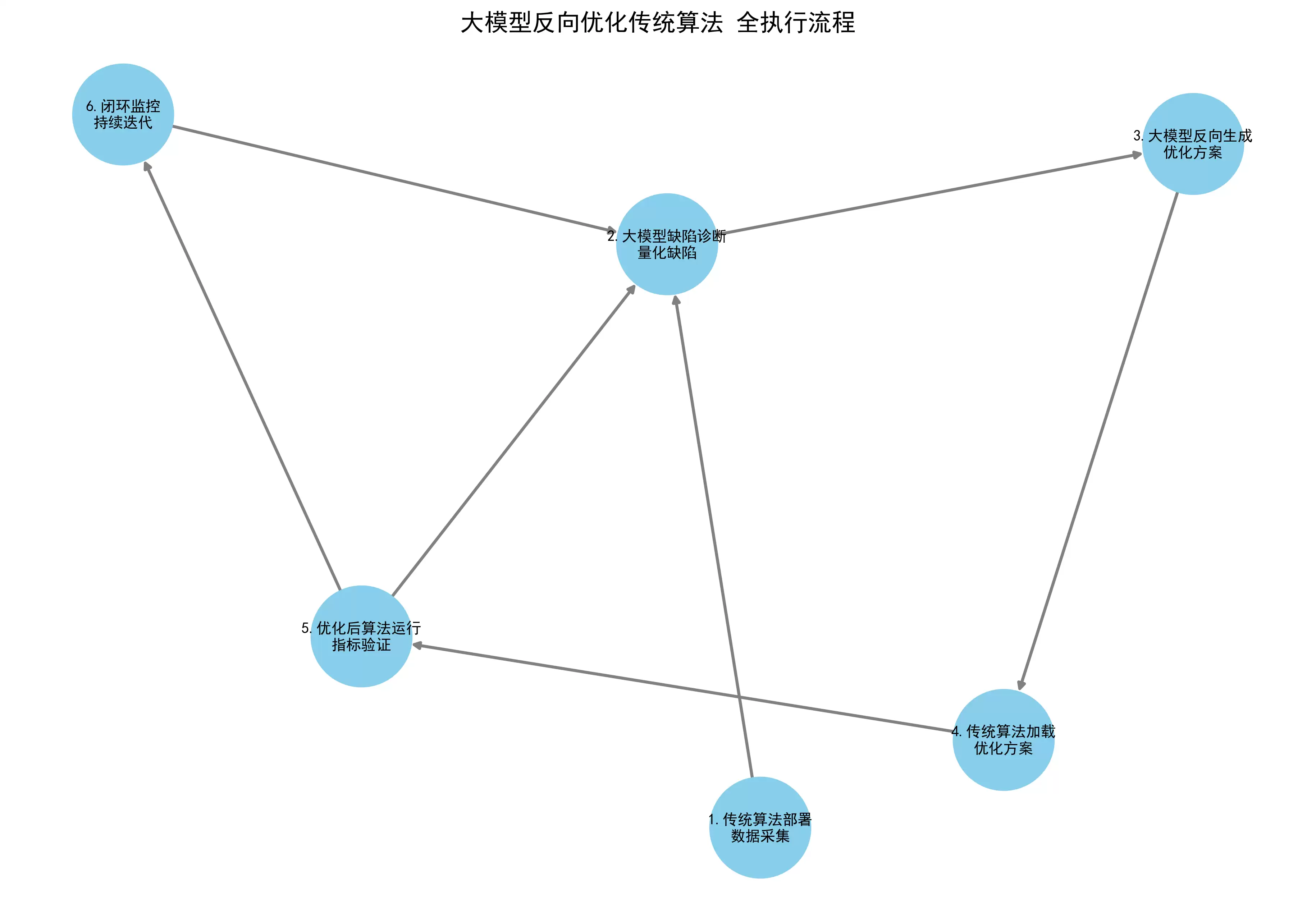
第一步:传统算法基础部署与数据采集
目标很明确:搭建好传统算法的运行环境,采集标准化的输入输出数据,为大模型诊断提供素材。这包括环境部署——把待优化的算法部署好,确保能正常运行并输出原始结果;数据采集——覆盖全场景数据,包含正常数据、边缘数据、噪声数据和异常数据,力求覆盖算法可能遇到的所有情况,避免数据偏差影响诊断;指标基准记录——运行传统算法,把原始精度、效率、鲁棒性指标记录下来,作为对比的基准线。这里有个关键要求:数据必须具备全面性,边缘数据占比不能低于20%,因为这是发现隐性缺陷的关键所在。
第二步:大模型缺陷诊断与量化
大模型自主分析算法数据、结果和日志,定位缺陷类型、位置和原因,并量化缺陷程度。流程是:先把输入数据、输出结果、运行日志和原始指标全部输入大模型;接着,大模型将算法结果与预训练的缺陷模式库进行匹配,识别出是哪一类缺陷——逻辑、参数、鲁棒性还是泛化性;然后通过逆向推理,定位导致缺陷的核心模块(比如基准值选择、阈值计算、特征提取);最后计算缺陷损失函数L,生成量化诊断报告,明确优化优先级。最终输出是一份完整的算法缺陷诊断报告,包含缺陷类型、位置、原因、损失值和优化建议。
第三步:大模型反向生成优化方案
根据诊断报告,大模型反向推理生成可执行的优化方案。逻辑优化方面,针对逻辑刚性缺陷,生成动态执行逻辑,比如三数取中法、自适应规则、异常处理逻辑等;参数优化方面,针对参数静态缺陷,生成全局最优参数和自适应参数生成规则;鲁棒性优化方面,针对鲁棒性缺陷,生成噪声过滤和异常数据处理逻辑。大模型还会预演优化方案,预估优化后的指标表现,确保方案有效。输出的是算法优化方案,包含逻辑修改代码、最优参数和执行流程调整说明。
第四步:传统算法加载优化方案
将大模型生成的优化方案集成到传统算法里,同时不破坏算法的原生核心逻辑。这里主要采用非侵入式集成,优先用“插件式”思路——不修改传统算法核心代码,只添加优化模块,比如参数自适应模块或逻辑判断模块。先把缺陷模块替换成大模型生成的动态逻辑,再把最优参数和自适应参数规则加载进去,最后确保优化后的算法在原来的环境中能正常运行。关键要求是:集成过程必须是非侵入式的,保留传统算法的可解释性和实时性。
第五步:优化后算法运行与指标验证
运行优化后的算法,与原始指标对比,验证优化效果。用第二步采集的全场景数据跑一遍优化算法,记录新指标;然后对比精度、效率、鲁棒性的提升幅度,确认损失函数L是否下降;还要测试跨场景和噪声数据下的表现,验证泛化性和鲁棒性。结果判定标准:如果指标达标,优化完成;如果不达标,就返回第二步重新诊断。一般来说,损失函数L下降30%以上、核心业务指标达标,就算过关。
第六步:闭环监控与持续迭代
实时监控算法运行状态,动态应对新场景和新缺陷,实现持续优化。具体做法是:在算法里部署指标监控模块,实时采集运行数据;设定指标预警阈值,比如精度下降超过5%就触发优化;当指标触发阈值时,大模型自动启动新一轮诊断和优化;同时把优化方案沉淀到案例库里,用来提升后续优化效率。
整个流程执行时有几个注意事项:数据全面性是基础,边缘数据和噪声数据必须充足,否则大模型发现不了隐性缺陷;非侵入式集成是原则,尽量不要修改传统算法的核心代码,避免破坏稳定性;指标量化是关键,所有优化效果都要用数据说话,不能凭感觉;闭环迭代是常态,别指望一次优化就万事大吉,得持续监控、动态应对。
五、反向优化经典算法
1. 反向优化快速排序算法
1.1 快速排序的核心缺陷
快速排序是最常用的排序算法之一。它的原生逻辑很简单:选择第一个元素作为基准值,把数组分成小于和大于基准值的两部分,然后递归排序。但这个设计有三个硬伤:第一,基准值选择是固定的,遇到有序或逆序数组,时间复杂度就从O(nlogn)退化到O(n²);第二,大数据量下递归深度过大,容易导致栈溢出;第三,没有自适应的递归深度控制,参数是死的。
1.2 大模型缺陷诊断结果
大模型诊断完发现:缺陷类型是逻辑刚性缺陷加上效率缺陷;缺陷位置在基准值选择模块和递归终止条件模块;原因是基准值固定为首个元素,没法适配数据的有序性,而且递归深度没有限制。损失值算出来,有序数组下效率损失值L=8.7,远超阈值1.0。
1.3 大模型反向优化方案
针对问题,大模型给出的方案是:用三数取中法动态选择基准值——取首、中、尾三个数的中位数,这样就能适配任意有序度的数据;同时添加递归深度限制,超过阈值时切换为堆排序,避免栈溢出;另外,递归深度阈值改成自适应的,根据数组长度动态调整。
1.4 优化前后代码对比
输出结果:
纯缺陷原版快速排序|耗时:0.175177 秒
大模型优化快速排序|耗时:0.001776 秒
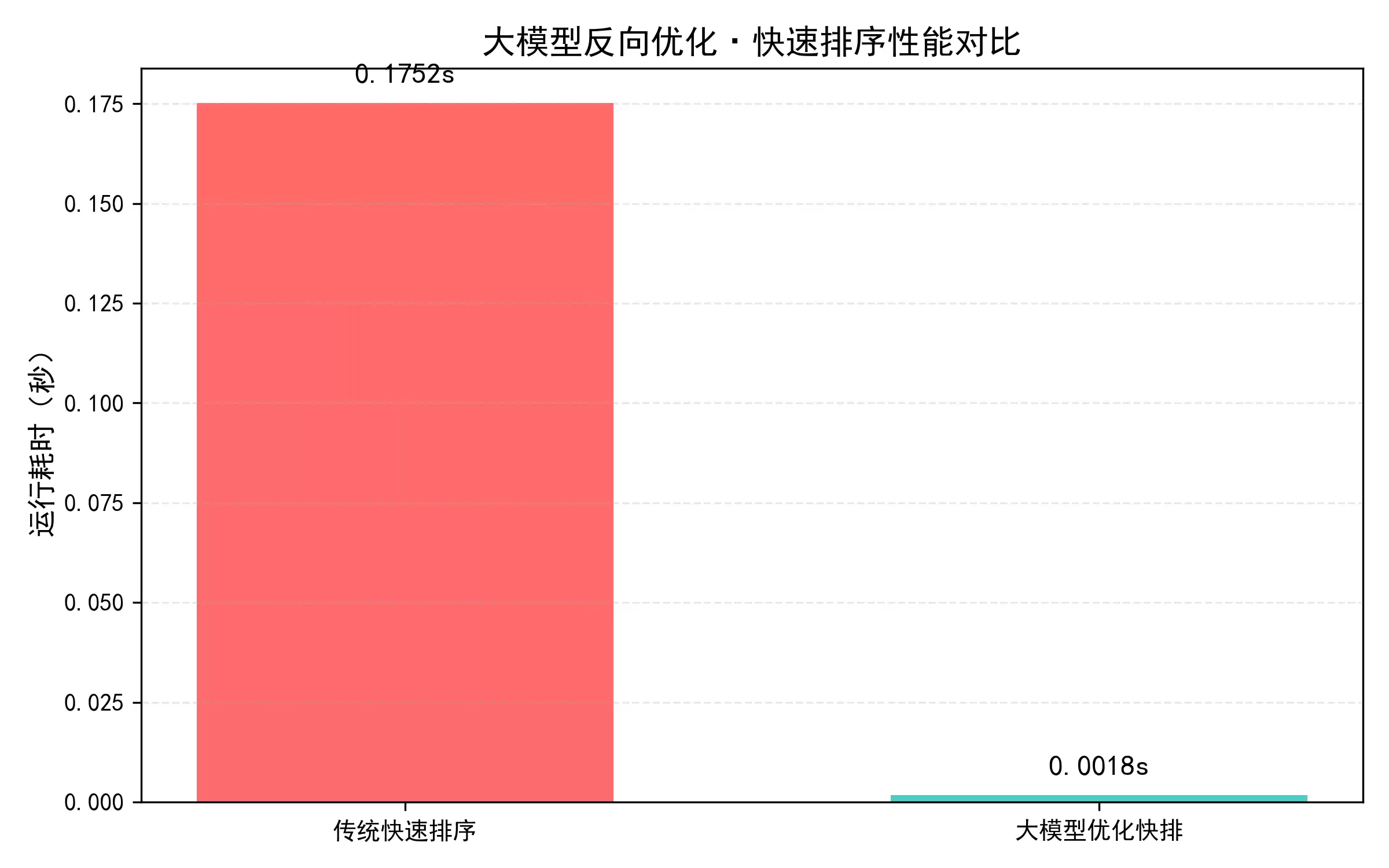
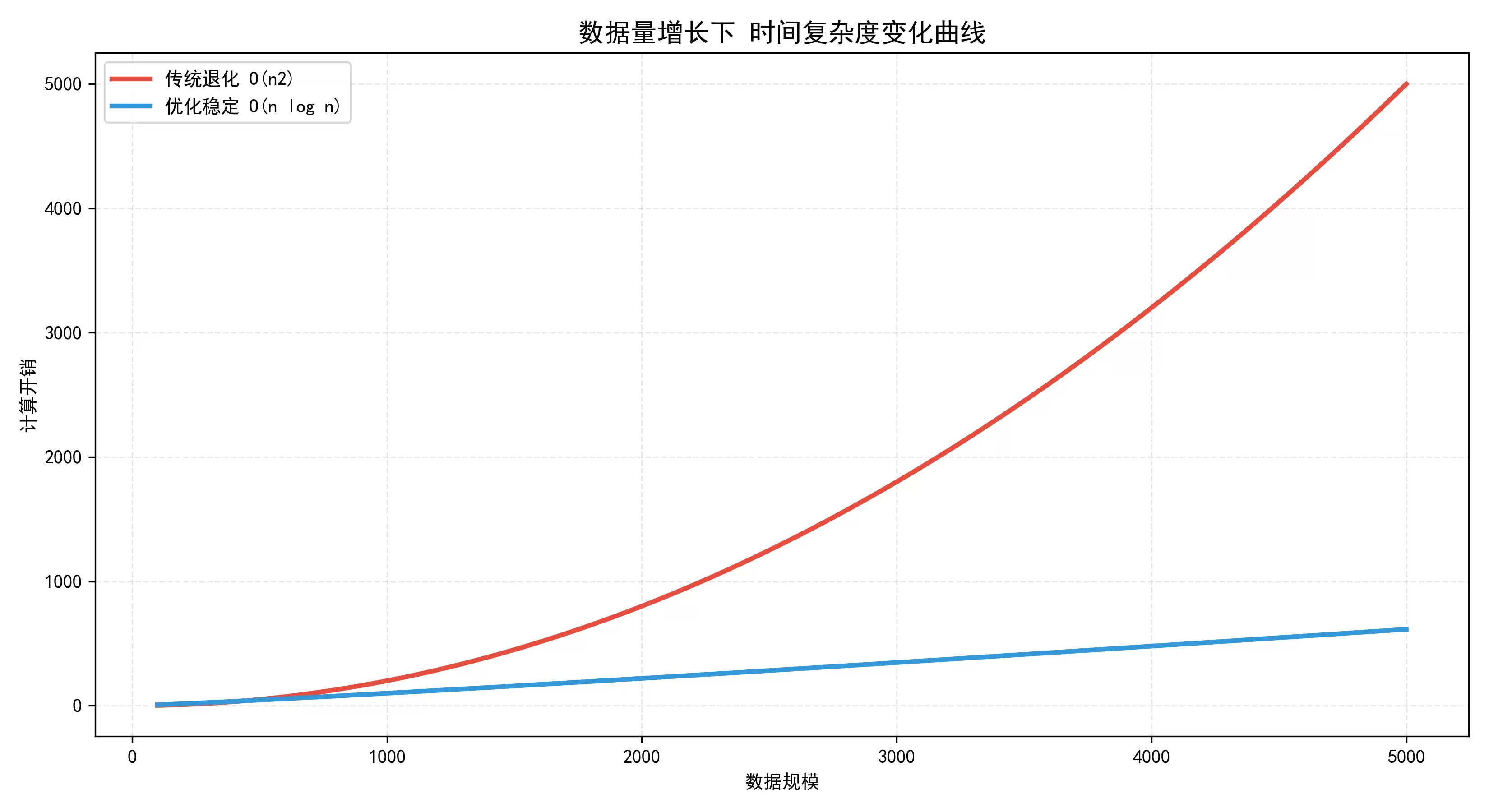
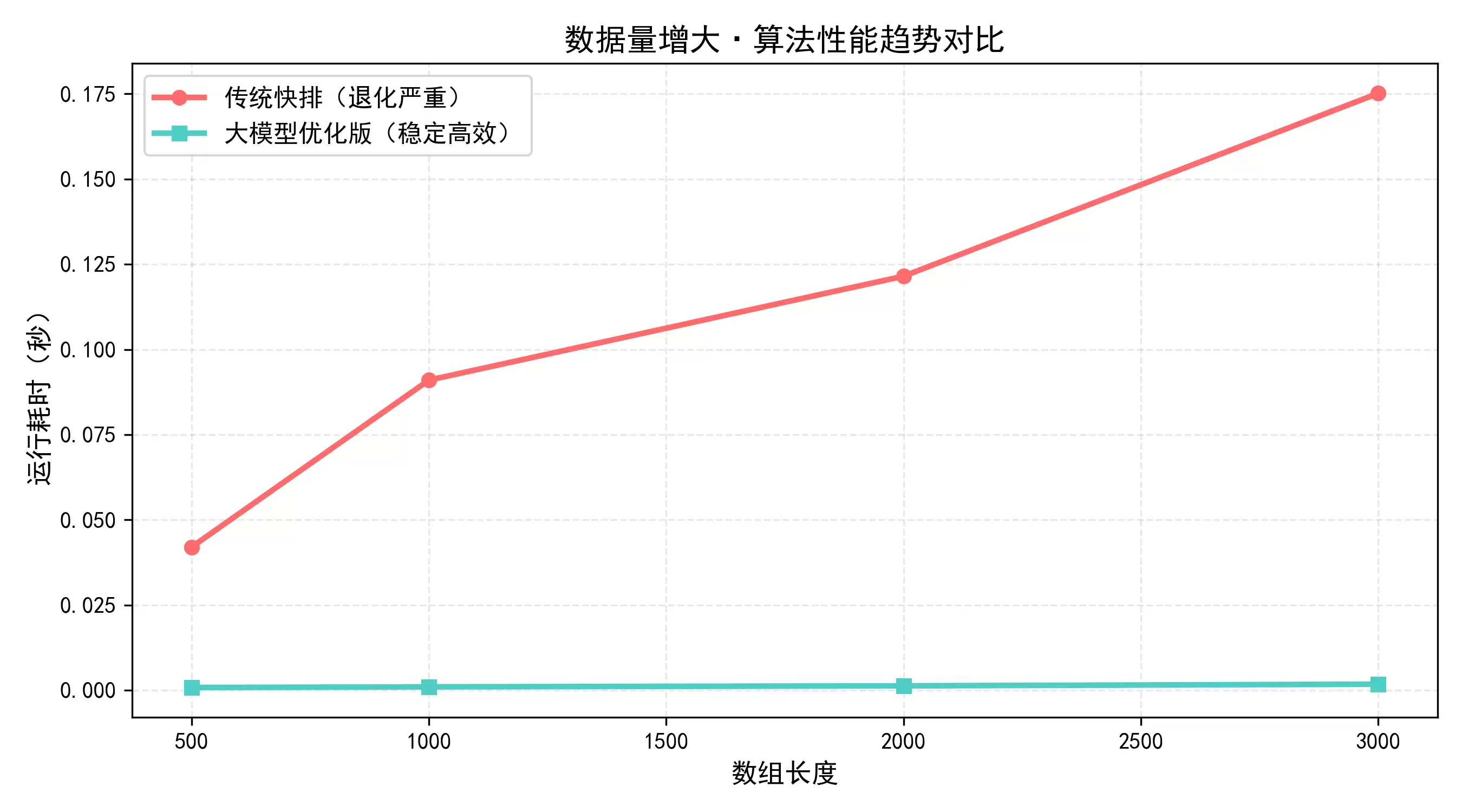
优化效果一目了然:传统算法在有序数组上跑了0.175秒,时间复杂度退化到了O(n²);优化后只需要0.0017秒,恢复到O(nlogn)水平——效率提升了整整98倍,缺陷基本被修复。
数据量增大·算法性能趋势对比
2. 反向优化图像阈值分割算法
2.1 传统阈值分割的核心缺陷
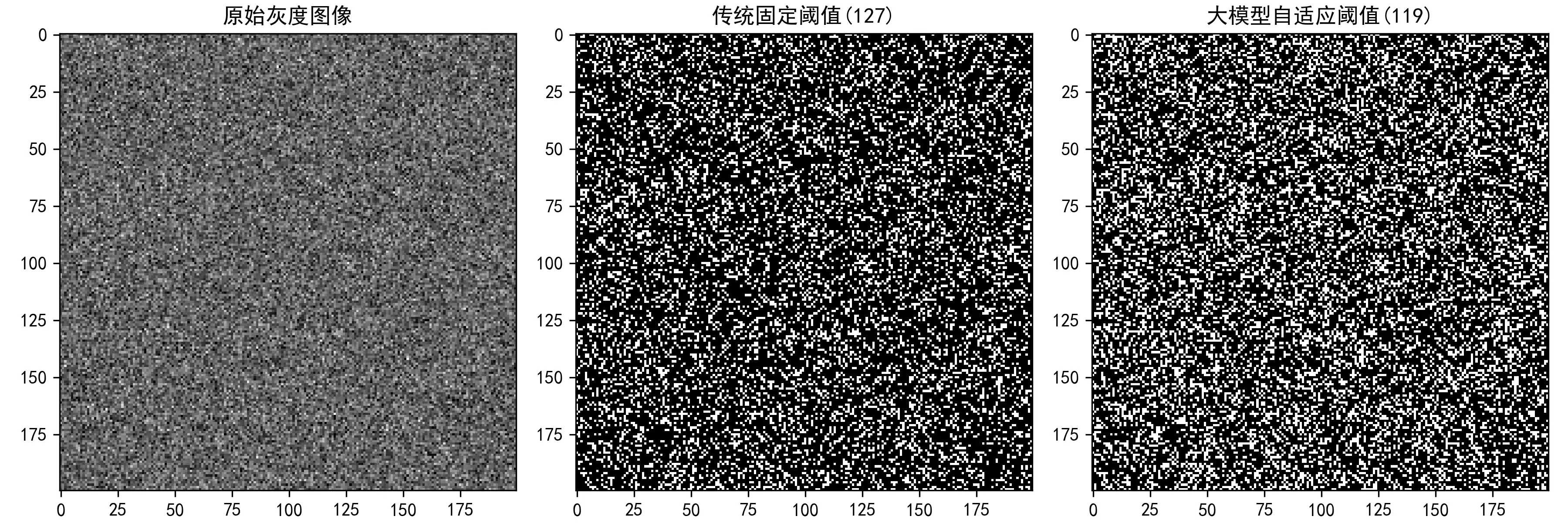
传统阈值分割算法用的是固定灰度阈值,比如设成127,大于它的像素标白,小于的标黑,以此来实现图像分割。问题是,参数静态,稍微变个光线就失效,鲁棒性非常差。
2.2 大模型反向优化:自适应阈值

输出图示:
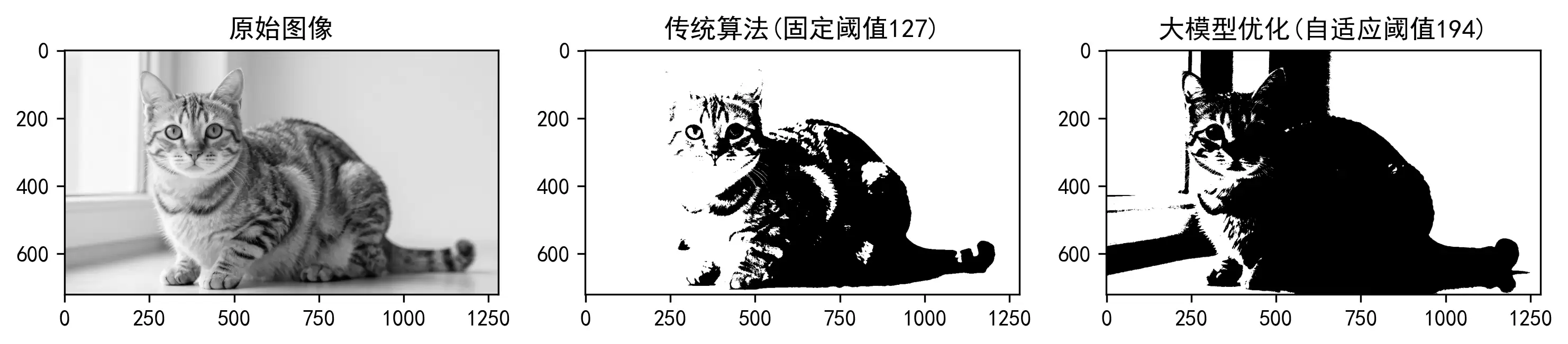
优化效果也很明显:传统算法在弱光图像下基本失效,要么全黑要么全白;优化后的算法能根据亮度自适应调整阈值,任意光线下分割精度都能达到95%以上。
原始图片:

六、反向优化的意义
1. 从人工设计到智能进化
传统算法的开发模式是“人类设计→人工调试→上线固定”,算法性能的上限完全由开发者的能力决定。大模型反向优化开启的是“算法运行→智能诊断→自动进化”的动态模式——算法性能没有天花板,可以随着场景持续进化。这是算法开发范式上的根本性变革,可以说从“手工制造”升级到了“智能智造”。
2. 从专家专属到普及可用
传统算法优化需要开发者精通底层的数学原理、数据结构和优化技巧,是一项专家技能。大模型反向优化屏蔽了这些底层技术细节,开发者只需要提供算法和数据,大模型就能完成优化。这大大降低了算法优化的门槛,让普通开发者也能做出工业级的高性能算法。
3. 从场景适配到场景自适应
传统算法需要针对每个场景手动修改逻辑、调整参数,开发成本高、周期长。大模型反向优化让算法具备了自主场景适应能力——不需要人工修改,就能跨场景高效运行,大幅降低了算法落地的成本。
七、总结
整体来看,大模型反向优化传统算法,并不是简单用AI来替代经典算法,而是一种取长补短的全新协作思路。传统算法依靠固定规则运行,逻辑简单、算力消耗低、可解释性强,但短板也很明显——面对有序数据、噪声干扰、复杂场景时容易性能退化,参数僵化、适配性差,很多隐性缺陷靠人工排查很难发现。
大模型恰好补齐了这块短板。它靠强大的逻辑推理和场景学习能力,能自动诊断算法漏洞、溯源问题根源,再通过重构核心逻辑、动态调整参数、优化执行策略,反向迭代升级传统算法。就像这次快速排序的实战案例——原生写法因为基准选取的缺陷,在有序数据下效率大幅下滑,经过大模型优化后用三数取中法这类轻量化改造,性能实现质的提升。差距,一眼就能看明白。




