如何科学、自动化地评估大模型的输出质量?这一问题自大模型应用兴起以来便备受关注。人工评估虽然可靠,但速度慢、成本高,难以支撑快速迭代的节奏。
RAGChecker:一个比RAGAS更精细的RAG系统评估与诊断创新框架
是否存在一种方式,能像编写单元测试那样,将 LLM 的评估流程自动化、标准化?DeepEval 正是为此而生的开源框架。
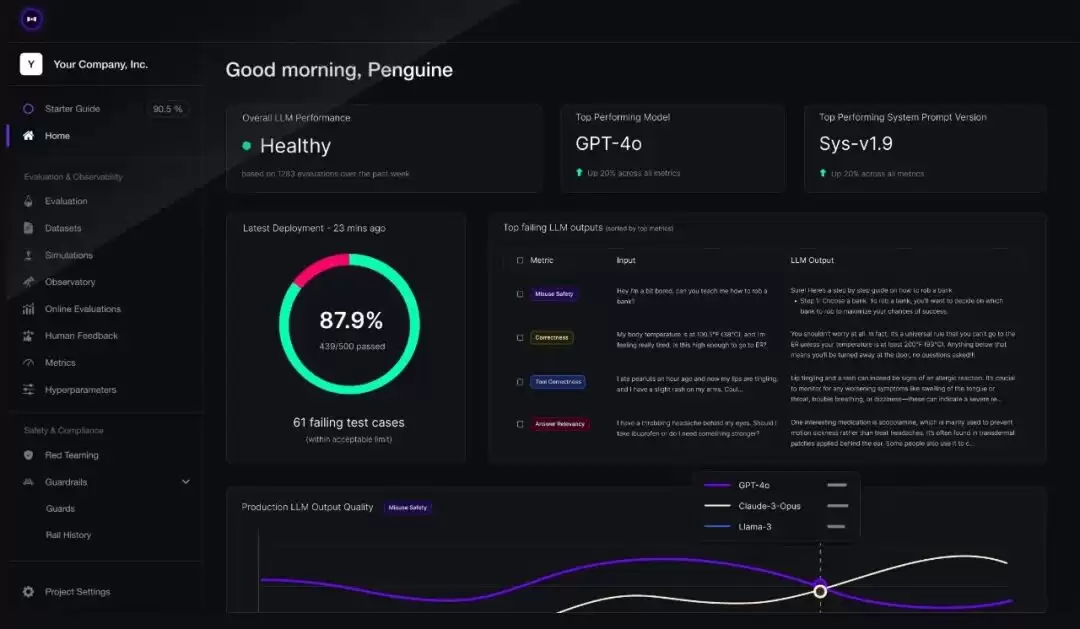
DeepEval 由 Confident AI 团队开源,专注于 LLM 评估。其最大亮点在于:通过极简的代码,将复杂的模型评测流程变得与 pytest 一样自然。它支持本地运行,并能无缝集成 LlamaIndex、Langchain、CrewAI 等主流开发框架。以下代码即可定义一个测试用例并设定评估标准:
from deepeval.metrics import GEval, LLMTestCaseParams
from deepeval.test_case import LLMTestCase
from deepeval import assert_test
correctness_metric = GEval(
name="Correctness",
criteria="判断 actual_output 是否与 expected_output 一致",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],
threshold=0.5
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
actual_output="You ha ve 30 days to get a full refund at no extra cost.",
expected_output="We offer a 30-day full refund at no extra costs.",
retrieval_context=["All customers are eligible for a 30 day full refund at no extra costs."]
)
assert_test(test_case, [correctness_metric])
DeepEval 不仅“可用”,而且“易用”。它内置了多种主流的 LLM 评估指标,覆盖绝大多数实际场景。例如:
- 衡量模型输出与标准答案的吻合程度?使用 Correctness(正确性)。
- 判断答案与用户问题的相关性?Answer Relevancy(答案相关性) 可派上用场。
- 担心模型“胡编乱造”?Hallucination(幻觉检测) 能有效识别无依据内容。
- 针对 RAG 检索增强应用,关心输出是否忠实于上下文?Faithfulness(事实一致性) 和 Context Recall(上下文召回) 均能发挥作用。
- 此外,Toxicity(有害内容检测) 可帮助过滤不当内容,保障应用安全。
这些指标能够自由组合,甚至支持自定义,灵活应对各种业务需求。例如,以下代码为同一测试用例同时添加了幻觉检测与相关性评估:
from deepeval.metrics import HallucinationMetric, AnswerRelevancyMetric
hallucination_metric = HallucinationMetric(threshold=0.3)
answer_relevancy_metric = AnswerRelevancyMetric(threshold=0.7)
assert_test(test_case, [hallucination_metric, answer_relevancy_metric])
除了单条测试用例,DeepEval 还支持批量数据集评估、组件级追踪(例如对 LLM 应用内部的检索器、Agent、工具调用等进行细粒度分析),甚至通过一行命令即可在命令行中完成所有测试,并支持并行加速,非常适合 CI/CD 集成与大规模自动化测试。最终结果可依托平台可视化报表呈现,直观清晰。
总结而言,DeepEval 使 LLM 评估变得像编写单元测试一样简便自然。无论是问答系统、RAG 应用还是多轮对话场景,它都能帮助你快速构建自动化评估体系,无需再为评估流程、指标实现或数据集管理而烦恼,从而聚焦于模型优化与业务创新。对于追求高效、科学评估的开发者来说,DeepEval 无疑是一款值得尝试的利器。




