香蕉也能变成礼服?Google 真的实现了!
在最新一期谷歌开发者节目中,Google DeepMind 团队首次完整展示了 Gemini 2.5 Flash Image —— 一款具备原生图像生成与编辑能力的全新 AI 模型。它不仅能快速输出高质量图像,还能在多轮对话中保持场景一致性,带来了突破性的互动体验。可以说,这是一次真正意义上的“图像生成革命”。
更重要的是,负责研发与产品落地的幕后团队也首次公开亮相了。
深度解析幕后研发团队
首先,让我们认识一下这几位关键人物。
Logan Kilpatrick

作为 Google DeepMind 的高级产品经理,Logan 负责 Google AI Studio 和 Gemini API 的产品规划。在 AI 开发者社区中,他的名字几乎无人不知——他此前在 OpenAI 负责开发者关系,被业内称为“LoganGPT”。更早的时候,他还在 Apple 做过机器学习工程师,甚至在 NASA 担任过开源政策顾问。
在 Google,他主导了 Gemini 2.0 Flash 本地图像生成功能的推出,让开发者能够通过自然语言指令生成和编辑图像。多轮对话式编辑、图文交替生成、基于世界知识的图像生成,都是这套系统的主要亮点。他几乎成了 Google AI 的“非正式代言人”,经常在 X 平台分享产品更新和开发者资源。
Logan 毕业于哈佛和牛津,早期在 NASA 开发月球车软件,后来在 Apple 训练过机器学习模型。有趣的是,他对 Julia 编程语言非常看好,2024 年还曾表示,直接冲向人工超智能(ASI)而忽视中间阶段的做法“越来越可能”。

Kaushik Shivakumar

Kaushik 是 Google DeepMind 的研究工程师,主攻机器人技术、人工智能和多模态学习。他在 UC Berkeley 获得计算机科学学士学位,之后在 AUTOLab 实验室攻读硕士,师从 Ken Goldberg 教授。研究生期间,他主要研究可变形物体操作、语言模型以及强化学习在机器人上的应用。
加入 DeepMind 前,他在 Google Brain 做过软件工程实习生,研究深度神经网络的不确定性估计方法。在 UC Berkeley 的 RISE Lab 和 Snorkel AI 等机构也都有过研究经历。进入 DeepMind 后,他参与了不少重量级项目,包括 Gemini 2.5 模型的开发,这套模型在推理能力、多模态理解和长上下文处理上进步显著。此外,他在机器人操作、物体追踪、语义搜索方面也发表过多篇论文。
Robert Riachi

Robert 是 Google DeepMind 的研究工程师,专注于多模态 AI 模型的研发,尤其在图像生成和编辑方面有显著贡献。他主修计算机科学和统计学,毕业于加拿大滑铁卢大学。

在 DeepMind,他参与了 Gemini 2.0 和 2.5 系列的研发,致力于将图像生成能力与对话式 AI 相结合,让用户可以通过自然语言指令进行精细的图像编辑。在此之前,他还在 Splunk、Bloomberg、SAP 和 Deloitte 等公司担任过软件工程师和机器学习工程师。
Nicole Brichtova

Nicole 本科和研究生分别毕业于乔治敦大学和杜克大学富卡商学院,现任 Google DeepMind 视觉生成产品负责人,专注于构建生成模型,推动 Gemini 应用、Google Ads 和 Google Cloud 等产品的发展。

在加入 DeepMind 之前,她在 Google 的消费产品团队做过产品和市场战略工作,还在德勤咨询公司担任过顾问,为财富 500 强的科技公司提供创新和增长方面的建议。

她特别关注生成式 AI 如何赋能创意、设计,以及人与技术互动的新方式。在多个公开场合,她分享了 DeepMind 在视觉生成领域的最新进展,重点展示了模型理解复杂指令和生成高质量图像的能力。
Mostafa Dehghani

Mostafa 是 Google DeepMind 的研究科学家,主要研究方向为深度学习,包括自监督学习、生成模型、大模型训练和序列建模。他博士毕业于阿姆斯特丹大学,研究聚焦于如何在不完备监督下改进学习过程——探索将归纳偏置引入算法、融入先验知识、以及利用数据本身进行元学习,目标是让算法在噪声或有限数据中表现得更好。
他 2020 年加入 DeepMind,参与了不少重要项目,包括多模态视觉语言模型 PaLI-X、220 亿参数的 Vision Transformer(ViT22B),以及 DSI++(Differentiable Search Indices)—— 一种用于文档增量更新的检索增强学习方法。
Nano Banana 演示中的技术亮点
具体如何做到“指哪儿打哪儿”?我们来看看节目里演示的几个亮点。
图像编辑与场景一致性
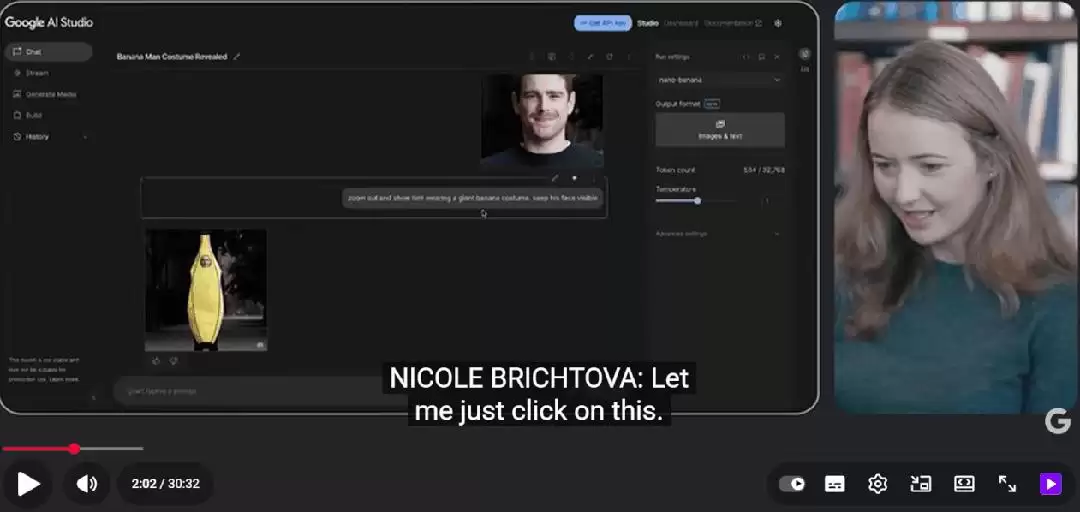
以第一个演示为例。让 AI 给 Logan “穿上一件巨大的香蕉服”,生成仅需十几秒。结果不仅保留了 Logan 的脸部特征,还自动加上了芝加哥街头的背景,场景一致性令人惊叹。
创意解读与模糊指令处理
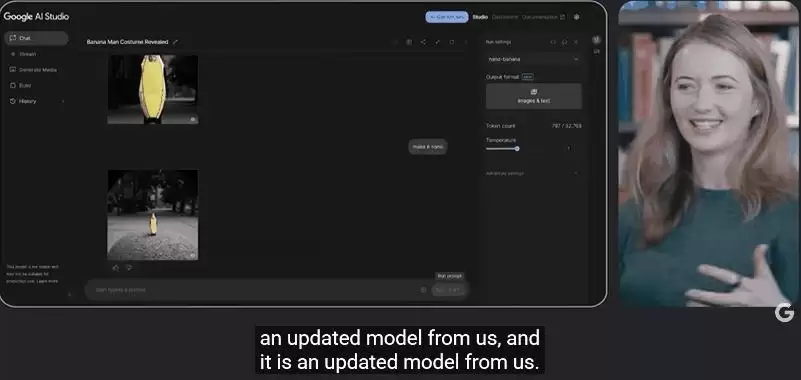
更有趣的是,当提示改为“让它变成纳米(Nano)”,模型直接生成了 Logan 的“迷你 Q 版”形象,但香蕉服的设定一点没丢。整个过程中,模型能通过自然语言进行多轮互动,并且在多次编辑里始终保持场景一致性,完全不需要用户提供冗长的提示词。
过去图像生成 AI 最大的槽点是什么?是“写字像外星文”。但这次,Gemini 2.5 Flash Image 已经能在图中正确生成简短文字了,比如“Gemini Nano”这种。

团队甚至把文本渲染能力当成了评估模型的新指标——因为它能反映模型生成图像“结构”的能力,也反过来作为衡量整体图像质量的信号,有助于指导模型改进。他们通过追踪这个指标,成功避免了模型退步。当然,目前文本渲染方面仍有不足,团队也在持续优化。
话说回来,Gemini 2.5 Flash Image 可远不止是一台“画图机器”。它最核心的魅力,在于能“看懂图片”。
团队介绍说,这款模型实现了原生图像生成与多模态理解的紧密结合:图像理解为生成提供信息,生成又反过来强化理解,两者相辅相成。通过图像、视频甚至音频,Gemini 能从世界里学到额外知识,从而提升文本理解与生成能力——视觉信号,某种程度上成了理解世界的一条捷径。
在操作体验上,模型引入了“交错生成机制(interleaved generation)”。面对复杂、多点修改的任务,它会自动把一次指令拆解成多轮操作,逐步生成与编辑图像,相当于“像素级别的完美编辑”。用户只需要用自然语言下达指令,就算提示比较模糊,Gemini 也能创意解读,并且保持场景一致性。不管是角色动作、服装,还是背景环境,修改与生成都能在多轮中保持连贯。
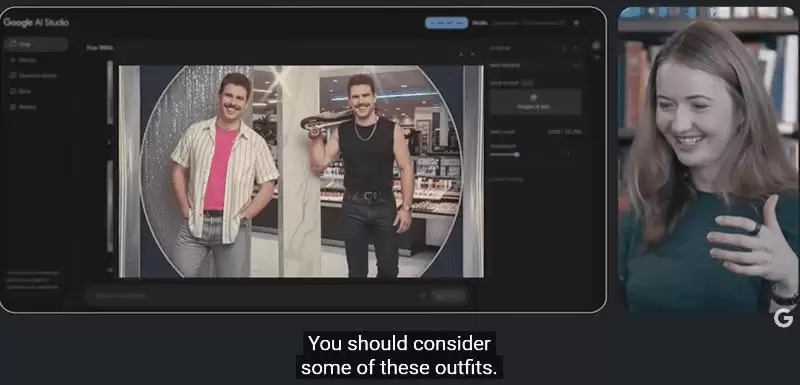
举个例子,让它用 1980 年代美国魅力购物中心的风格生成多张图片,每张图都能风格一致,且彼此之间有上下文关联。模型会利用多模态上下文,参考先前的图像来生成修改。
因此除了娱乐搞怪,Gemini 2.5 Flash Image 在实际应用场景里也大有用武之地。比如家居设计,用户可以快速查看多种方案——房间换不同窗帘的效果,模型能精准只修改窗帘部分,不破坏整体环境。又比如人物 OOTD,无论是换衣服、变角度,还是生成 80 年代复古风形象,人物的面部和身份一致性都能保持得很稳。生成一张图只要十几秒,失败了也能迅速重试,创作效率确实提升了一大截。
那么,在实际开发中,开发者到底该在 Imagen 和 Gemini 之间怎么选?
Nicole Brichtova 的回答很直接:Gemini 的终极目标,是整合所有模态,朝 AGI(通用人工智能)方向迈进。这意味着 Gemini 不只是一个图像生成工具,而是一个能利用“知识转移”、在跨模态复杂任务中发挥作用的系统。相比之下,Imagen 专注文本到图像的任务,在 Vertex 平台里提供多种变体,针对特定需求做了优化——比如单张图像的高质量生成、快速输出、成本效益等方面。简单说,如果任务目标明确、追求速度和性价比,Imagen 依然是理想选择。
但一旦涉及复杂的多模态工作流,Gemini 的优势就出来了。它适合复杂多模态任务,支持生成+编辑、多轮创意迭代,能理解模糊指令。Gemini 能利用世界知识理解模糊提示,特别适合创意场景。Nicole 还补充了一句:Gemini 可以直接把参考图像作为风格输入,比 Imagen 更方便。这让它在处理“以某公司风格设计广告牌”这类任务上,操作起来更自然、更高效。
最后,团队成员也分享了对未来能力的展望。
一个是智能提升。Mostafa Dehghani 希望模型能展现出真正的“智能”——就算不完全遵循指令,也能生成“比我想的更好”的结果,让使用者感觉自己在和一个更聪明的系统打交道。另一个是事实性与功能性。Nicole Brichtova 对“事实性”充满期待,希望未来的模型可以生成既美观又功能准确的信息图或图表,甚至自动帮你做好工作简报。在她看来,这不过只是这些模型能力的一小部分罢了。




