6月20日,x86生态系统咨询小组(EAG)正式发布了ACE规范1.15版本。这个版本最核心的价值,在于通过原生矩阵乘法引擎和低精度格式,给x86架构的AI性能来了一次实打实的增强。说白了,就是让x86芯片在跑AI任务时更顺手、更高效。
说起来,EAG这个组织本身就很有意思。去年英特尔和AMD这对老对手“世纪破冰”,联手成立了这个小组,目的就是协调x86架构的未来演进方向,推动整个生态的规范化和标准化。毕竟AI任务带来的挑战越来越具体,光靠单打独斗已经很难形成合力了。
ACE的全称是AI Compute Extensions,一套专门为加速人工智能与机器学习负载设计的x86指令集。它的核心目标非常明确:一是优化矩阵乘法运算——这是深度学习里最频繁的计算操作;二是优化低精度数据格式的处理。这两个方向,几乎就是当前AI推理和训练场景的命门。
从长期愿景来看,这次ACE的推出有一个很关键的设计初衷:避免重蹈A VX-512的覆辙。过去A VX-512因为各厂商实现方式不同,导致软件生态碎片化严重,开发者苦不堪言。而ACE从设计之初就要求AMD与英特尔共同承诺支持,并且未来产品更迭不会轻易废弃——这等于给开发者吃了一颗定心丸。
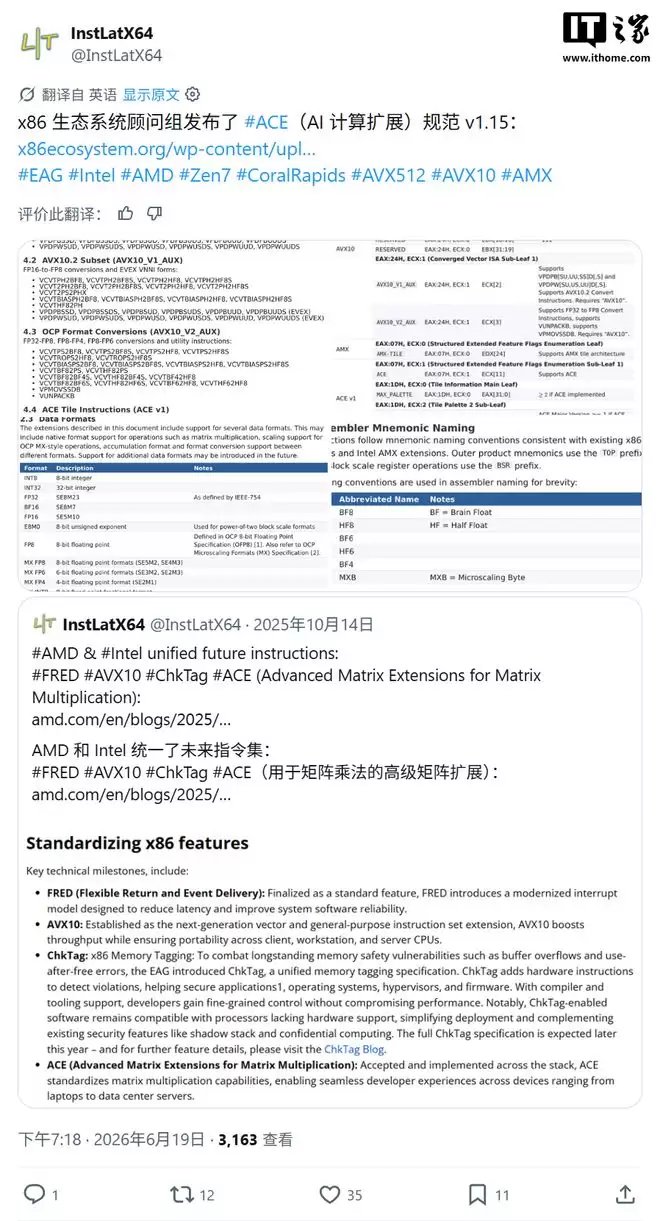
技术细节方面,ACE在现有的A VX向量指令基础上,新增了“图块寄存器”(tile register)状态,并定义了相应的数据移动与处理操作。同时,ACE还纳入了A VX10框架下的专用格式转换指令,进一步完善对低精度数据的支持。可以理解为,它在硬件层面为AI计算专门开辟了一条“快车道”。
部署路线图上,AMD已经亮出了明确的时间表:Zen 6将引入“新AI数据类型支持”与“更多AI管线”,而Zen 7则直接配备“新矩阵引擎”与“AI数据格式扩展”。这意味着,从下一代架构开始,AMD的芯片在AI加速方面会有质的飞跃。

在数据格式支持上,ACE的覆盖面相当广:INT8、INT32、FP32、BF16、FP16、E8M0、FP8,以及MX联盟定义的MX FP8(SE5M2/SE4M3)、MX FP6(SE3M2/SE2M3)、MX FP4(SE2M1)和MX INT8等。几乎把主流和前沿的低精度格式一网打尽,为开发者提供了足够灵活的选择空间。
参考




