苹果M4芯片内置的神经网络引擎,原本仅对推理任务开放访问权限——开发者可以借此运行预训练模型,但想要直接在引擎上训练新模型?根本不可能。然而,一位ID为@0x0SojalSec的X平台用户声称,他已经成功突破了这一软件限制,并对M4 SoC完成了完整的反向工程。

整个破解过程的核心在于将所有数据保留在RAM中执行,避免使用常规的读写流程,因此运行速度极快,操作体验也相当流畅。
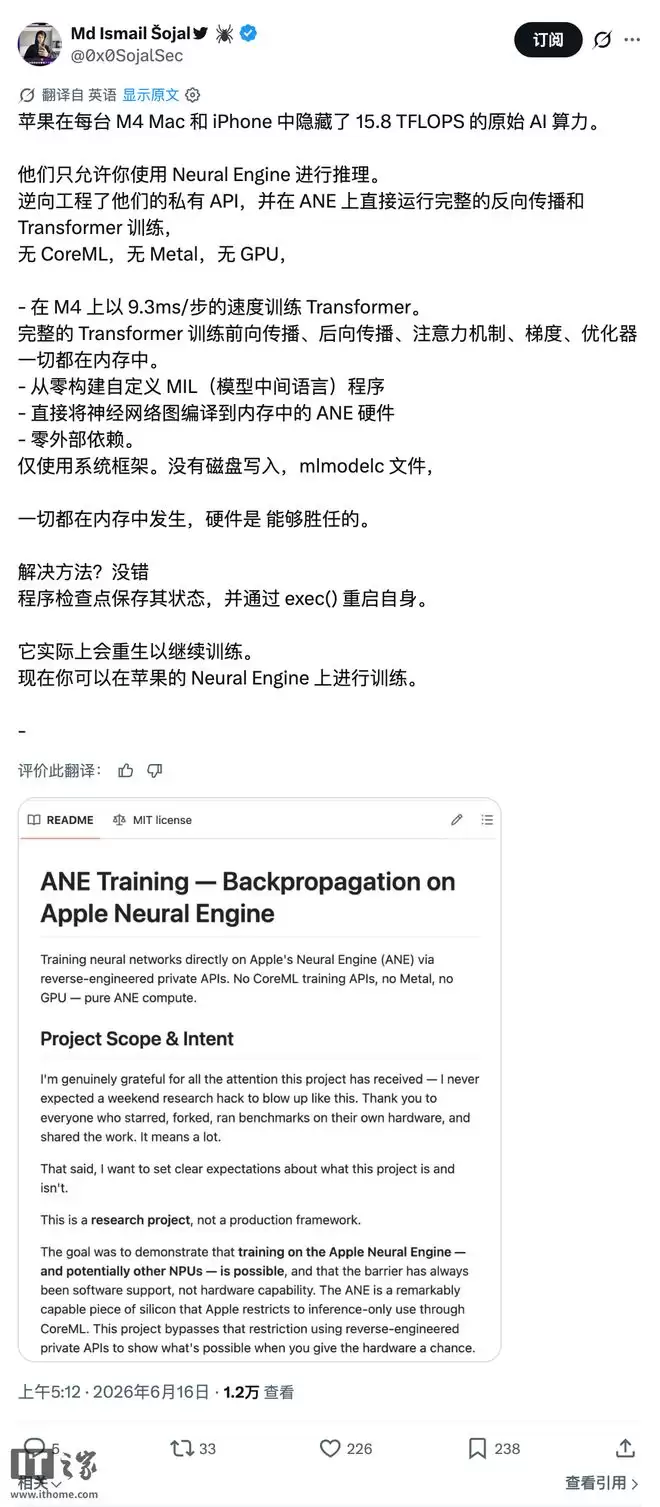
@0x0SojalSec今天凌晨在X上分享了一个GitHub代码仓库,展示了如何彻底释放M4的运算潜能。他没有借助苹果官方的Core ML、Metal等工具(因为苹果并未开放直接与这些芯片通信的权限),也没有调用GPU,而是从零构建了一套自定义的MIL(模型中间语言),利用这套工具直接与M4进行底层通信。
由于苹果对M4的硬件能力实施了“封锁”,整个过程需要采用一些变通手段。举例来说:当训练进程陷入卡顿、需要重置才能继续时,这套自定义MIL会调用exec()指令,使进程重新启动并继续训练。这样一来,程序可以刷新当前状态,避免直接崩溃,同时保证学习过程持续进行。
为了提升速度,整个解锁流程完全避免了写入NAND闪存。NAND闪存写入速度较慢,而RAM速度快得多,因此整个流程能够维持高速运行。突破软件限制后,iPad或Mac中的M4可达到15.8 TFLOPS的AI处理性能——这一算力足以承担AI模型的训练任务。
值得注意的是,目前尚无法确认同一套自定义MIL能否适用于更新的Apple Silicon芯片,也无法确认exec()在新平台上是否仍能按预期正常工作。




