本文推荐一套系统学习Transformer模型的五章节教程,从Seq2Seq模型基础与注意力机制入门入手,逐步深入解析Encoder与Decoder的结构细节,最终通过机器翻译项目实战巩固所学知识。教程强调Transformer中每个结构设计都蕴含原理,建议多次阅读以加深理解,全文通读大约需要1至2小时。通过本教程,读者能够全面掌握Transformer模型的工作原理与实现方法,为后续学习大规模模型奠定坚实基础。
如果你正在学习深度学习或大模型相关领域的知识,一定对Transformer不陌生——作为目前最有望实现统一框架的模型,其重要性不言而喻。
许多同学在学习Transformer的过程中,可能难以透彻理解其中每一个结构设计的具体细节和背后的原理。本期内容主要为大家推荐一套从入门到深入理解Transformer的优质教程。
该教程的具体内容如下:
第一章:引言
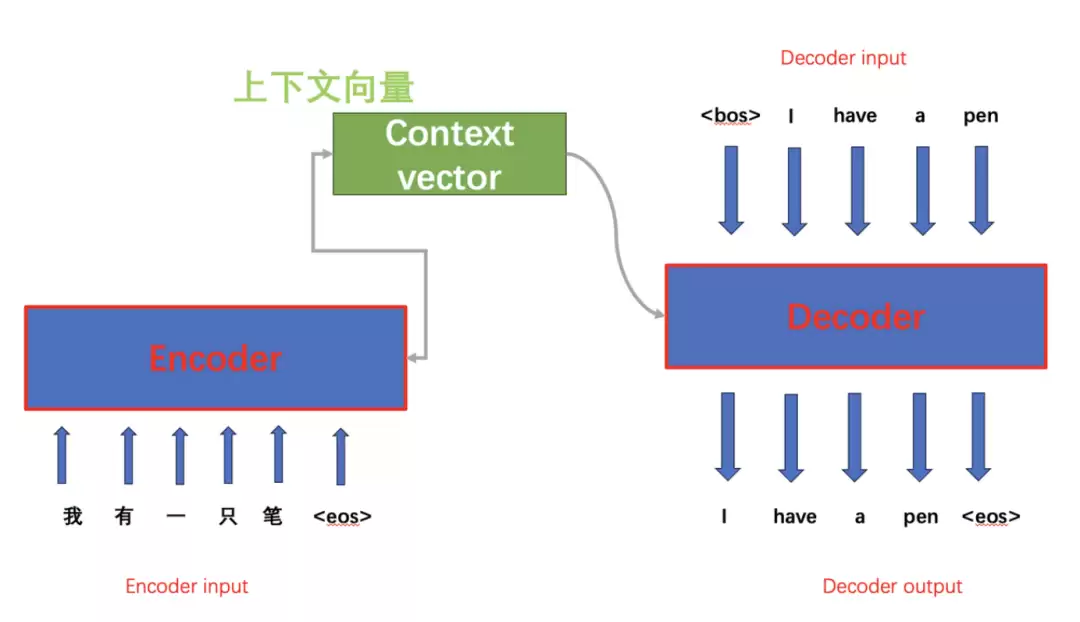
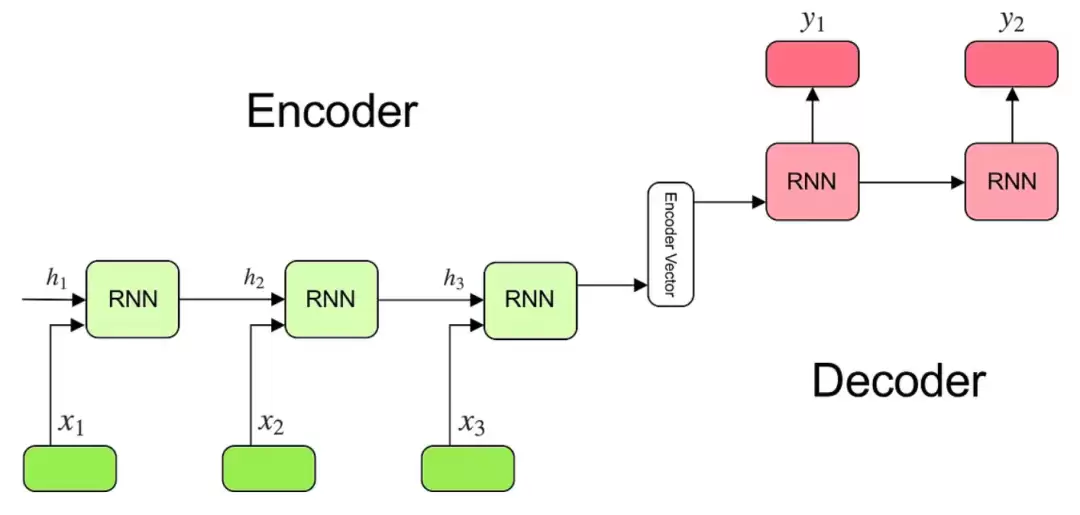
Transformer模型是对Seq2Seq模型的改进,继承了Encoder-Decoder的思想,但摒弃了RNN,转而采用注意力机制重构内部运作方式。本章先介绍Seq2Seq模型以及Encoder-Decoder结构的工作流程,随后讲解注意力机制的发展历程及其优缺点。
第二章:Transformer简述
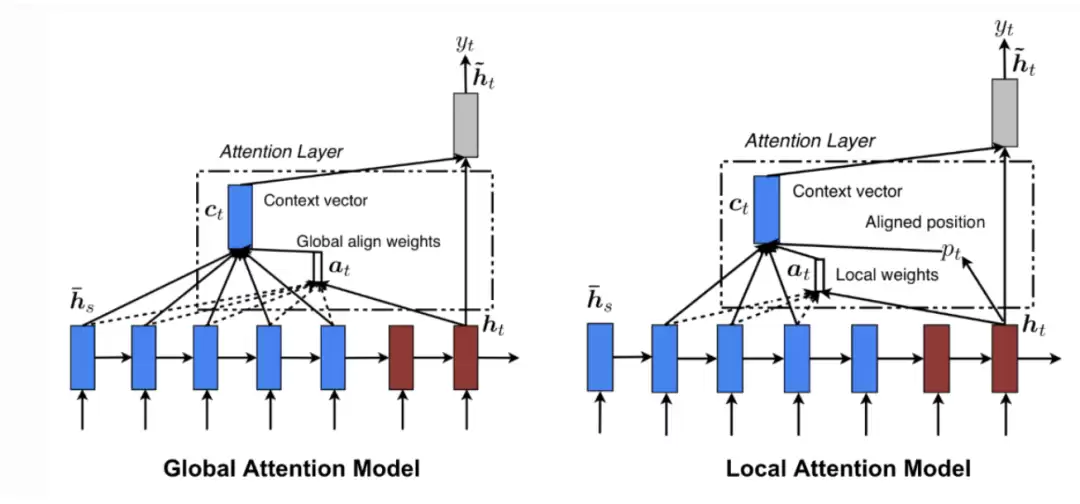
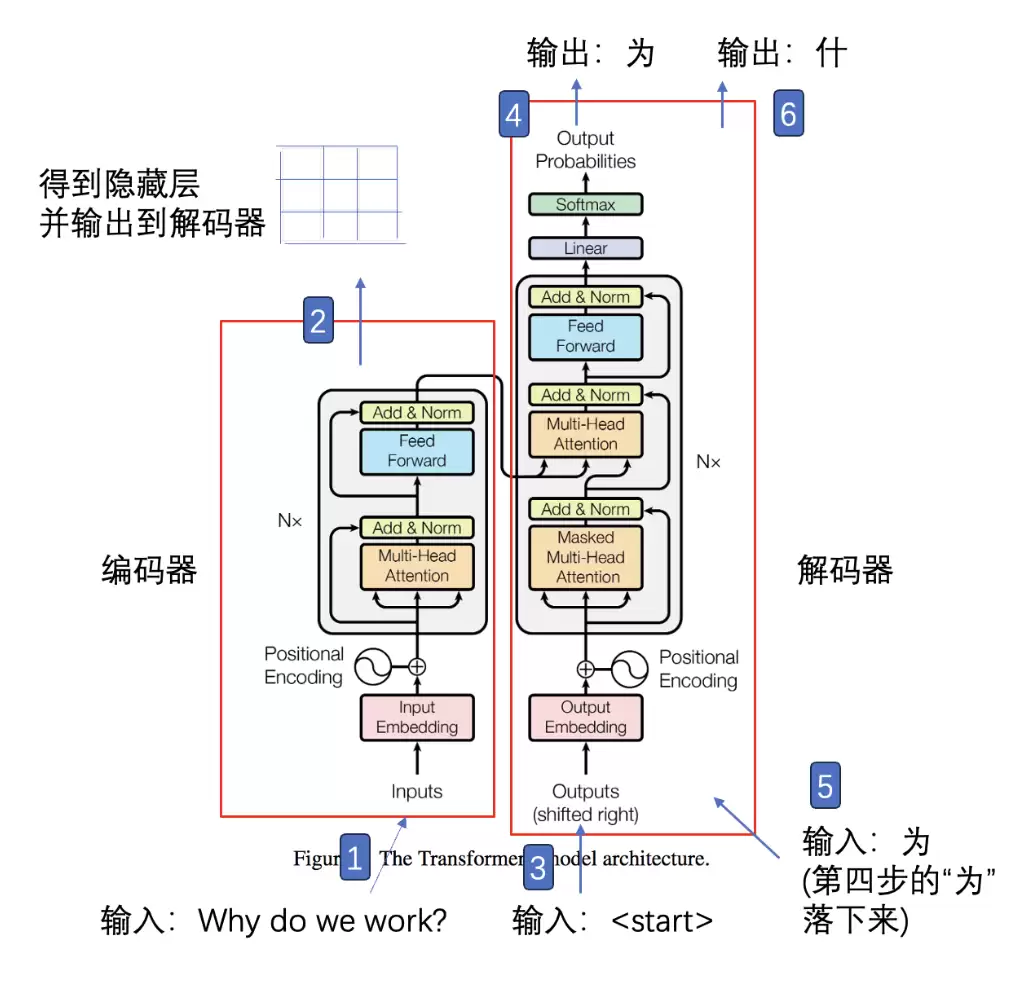
本章首先介绍深度学习如何引入注意力机制、注意力机制的作用原理、全局注意力与局部注意力机制的差异,然后讲解Transformer模型的整体结构及工作流程,最后对比Transformer、RNN和CNN在特征提取能力上的区别。
第三章:Encoder结构
本章详细阐述Encoder的工作流程,涵盖数据输入、位置编码、多头注意力层、残差连接与层归一化、缩放点积注意力、自注意力机制等内容,随后对比交叉注意力与自注意力的差异。这部分内容较为细致,建议认真通读一遍。
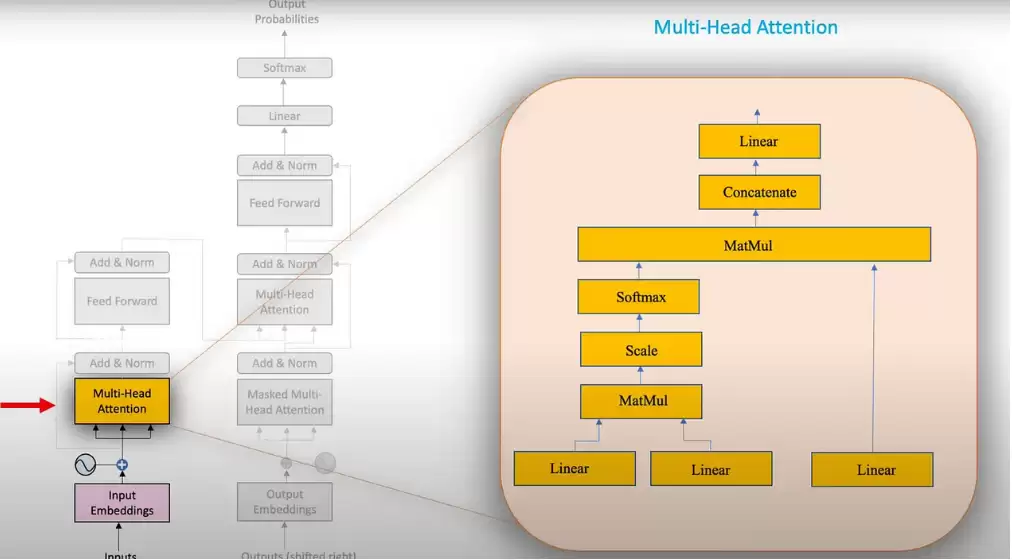
第四章:Decoder结构
本章首先介绍Decoder的解码流程,然后深入讲解掩码多头注意力机制、掩码填充的原理。Decoder与Encoder的主要区别在于多了一个交叉注意力层,最后还会介绍模型的训练与评估技巧,以及Bert模型和GPT模型的相关知识。
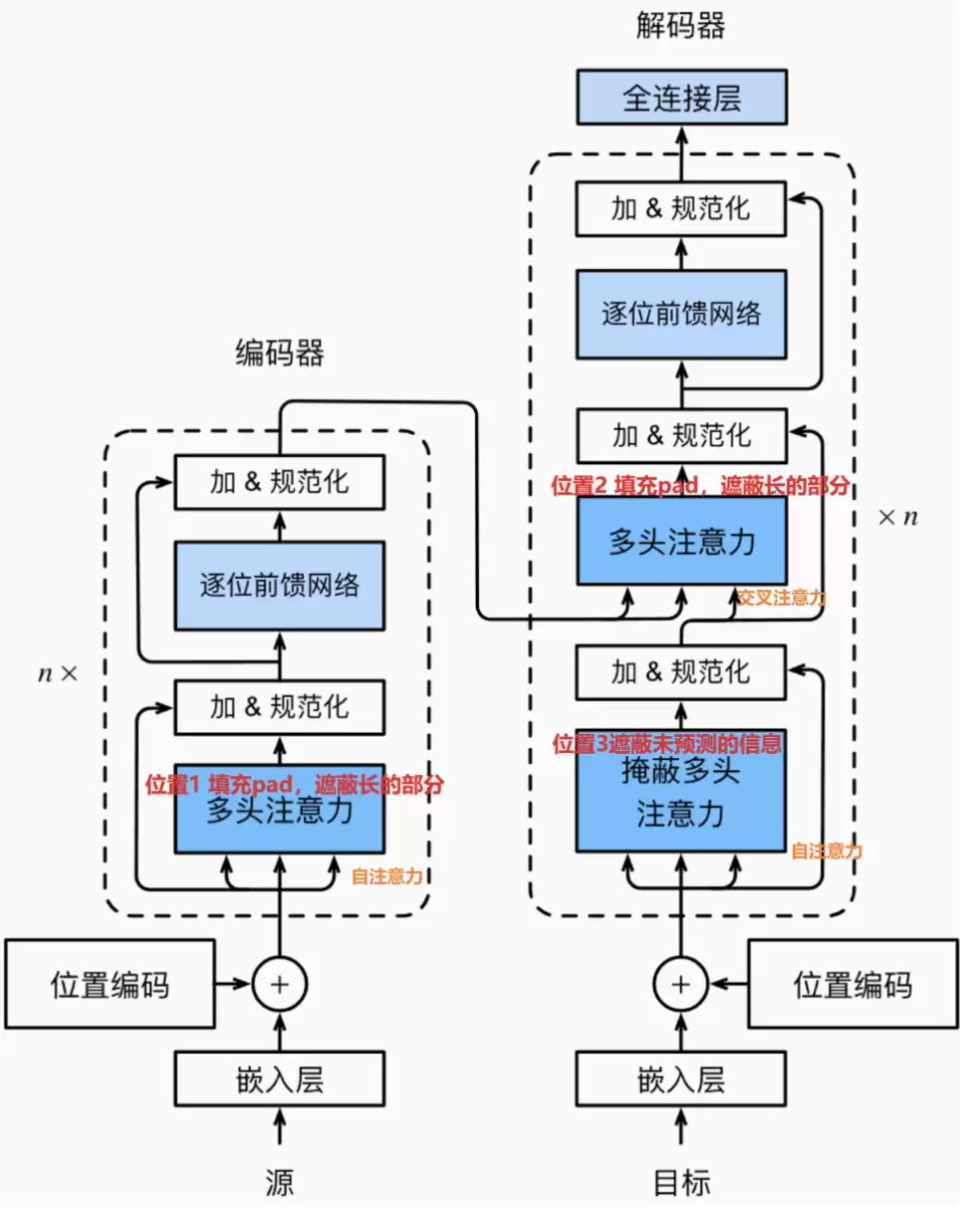
第五章:项目实战
本章展示一个实际项目案例——机器翻译。内容包括Transformer结构拆解、使用NumPy和SciPy实现通用注意力机制。学完这一部分后,你将能从代码层面更深刻地理解Transformer模型。
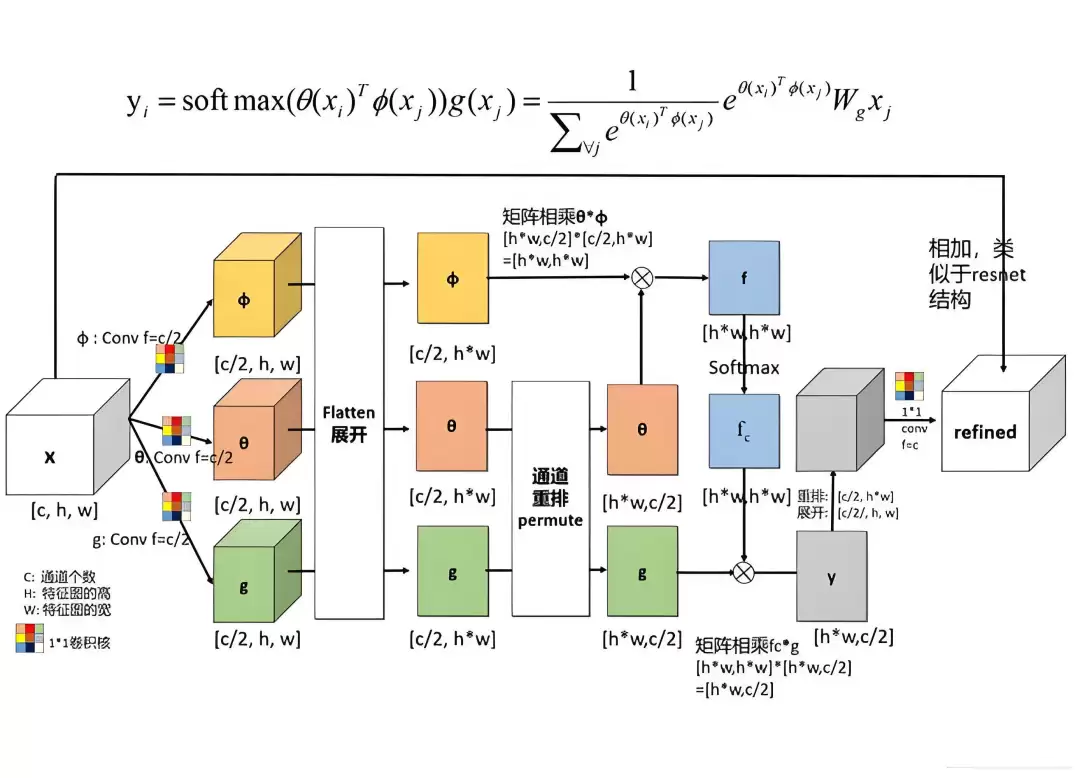
Transformer模型涉及的内容并不算多,但每一个结构都值得单独拆解分析。每一部分的设计都有其内在逻辑,建议反复阅读,以加深对Transformer模型的理解。完整阅读一遍大约需要1至2小时。




