今日关键词:大模型、数据库、RAG、向量检索、AI Agent、多模数据库、DBA
大模型火了之后,DBA圈子里讨论最多的,倒不是“AI会不会替代DBA”,而是另一个更实际的问题:大模型真正落地的时候,数据库究竟扮演什么角色?
这个问题值得好好拆解一下。结合最近的一些资料和与AI应用领域朋友的交流,这里把思考的脉络梳理出来,希望能给同样在琢磨这件事的朋友一些启发。
大模型的四个数据难题
大模型虽聪明,却有四个绕不开的“硬伤”。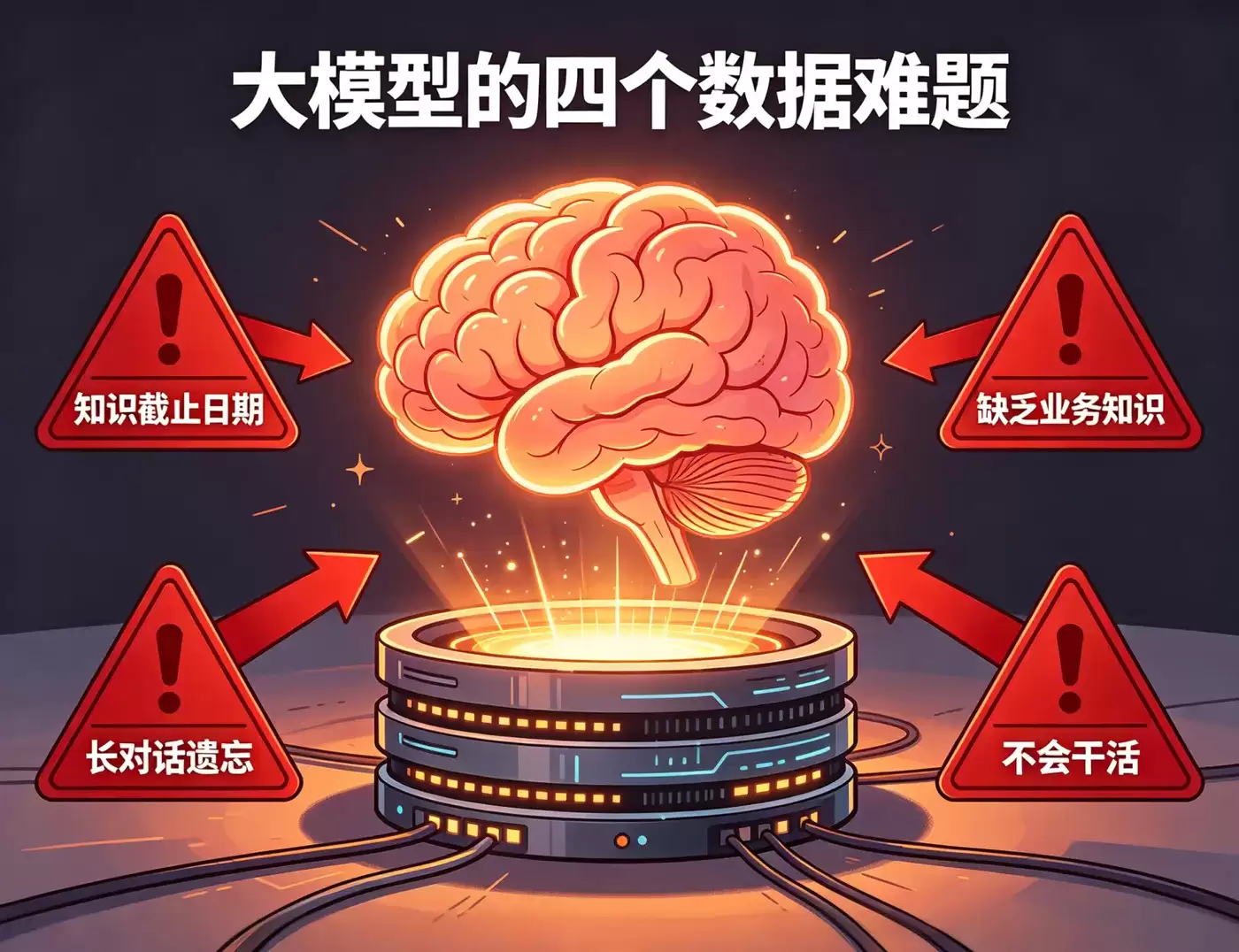
首先,知识是有“保质期”的。训练数据不可能实时更新,你问它今天的股价,它大概率答不上来。
其次,它对你的业务一无所知。公司内部的文档、流程、核心数据,训练时它根本没接触过。
再者,它记不住长对话。上下文窗口虽然在不断扩展,但成本和注意力稀释的问题也随之而来。窗口越大,模型越容易“遗忘”中间的关键信息。而且,每次对话都把完整历史塞进提示词,token费用是个不小的负担。
最后,基础模型本身并不会“干活”。它擅长生成文本,但让它查数据库、调接口、操作文件,必须依赖Agent和函数调用。难点不在于“能不能”,而在于“如何可靠地执行”。
这四个问题,最终都指向同一个核心:数据层。在大模型时代,数据库非但没有被弱化,反而变得比以往任何时候都更重要。
RAG:让大模型真正理解你的数据
解决知识不足的方案,叫RAG,也就是检索增强生成。
思路很直接:把你的文档切片,转换成向量,存入向量数据库。当用户提问时,先在向量库中进行语义检索,找到最相关的几段内容。然后,将检索到的内容连同用户问题,一并交给大模型,让它基于这些信息生成回答。
这里的关键技术是向量检索。传统关系数据库擅长结构化查询,而向量检索走的是语义相似度,通过近似最近邻算法来寻找结果。比如“数据库备份”和“数据快照”,字面上完全不同,但在向量空间里距离很近。
向量数据库存储的不是行列数据,而是高维向量。常用的索引算法如HNSW、IVF,在百万级向量规模、合理维度下,能做到毫秒级返回。
RAG让大模型从一个“通用助手”,变成了真正“懂你业务”的助手。而数据库的角色,也从单纯的数据存储,升级为知识存储。
Agent的记忆:数据库支撑对话的连续性
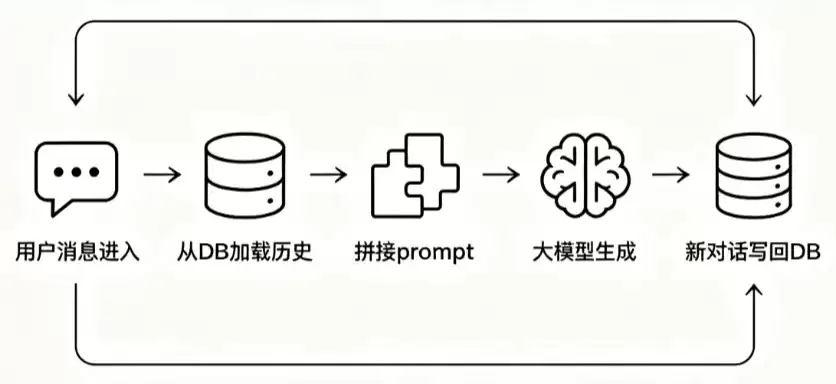
大模型的另一个硬伤是“记性差”。上下文窗口再大也有上限,而且塞太多历史内容,模型推理成本高,注意力也会被稀释。
解决方案是把对话历史持久化到数据库中。每次用户发消息,先从数据库加载历史对话,与当前问题拼接后发给大模型。回答生成后,再把新一轮对话写回数据库。
这就要求数据库的读写延迟足够低。用户发消息后,数据库需要在毫秒级完成历史对话的读取和新对话的写入。模型推理本身需要几秒钟,数据库绝不能在这个基础上再拖慢响应。
更复杂的是多轮对话的上下文管理。不是把所有历史一股脑都塞进去就行,token有上限,必须做摘要、做截断、做优先级排序。这些逻辑的顺畅执行,都依赖数据库层的结构化存储。
Agent还需要挂载外部知识库,把企业内部的文档、FAQ、操作手册索引起来,随时供其检索。这样一来,数据库就从“被动存储”变成了“主动供给”。
工具调用:数据库成为AI的执行层
Agent不仅能聊天,还能干活。查数据库、调接口、发邮件、操作文件,这些操作都需要一个可靠的数据层来支撑。
比如,Agent要帮用户查订单状态。它得理解用户意图,生成SQL,执行查询,最终返回结果。在这个过程中,数据库不仅仅是存储工具,更是Agent的执行层。
再比如,Agent要自动处理工单。它需要读取工单内容,进行分类、分配、更新状态。每一步都离不开数据库的读写操作。
这给数据库提出了新要求:不仅要能存能查,还得支持低延迟、高并发、多模型。关系数据、JSON文档、向量嵌入,可能都在同一个业务流程中间出现。
这也正是多模数据库出现的背景。一套引擎支撑多种数据模型,Agent无需对接多套系统,大大简化了架构。
DBA怎么办?
说到这里,DBA可能会有些焦虑:这些新东西我还没掌握,该怎么办?
其实,底层逻辑并没有变。
向量数据库再新,核心依然是存储和查询。数据结构从行列变成了高维向量,查询方式从精确匹配变成了相似度搜索,但DBA的调优思维、容量规划、高可用设计,这些经验依然价值连城。
变的是工具和接口。DBA需要学习的,不是“如何被替代”,而是“如何扩展”。在原有能力基础上,加上向量检索的理解、多模存储的认知、AI应用架构的基本概念,这就足够了。
大模型时代,DBA非但没有被边缘化,反而离应用层更近了。以前,DBA只关心数据怎么存、怎么查、怎么备份。现在,DBA要参与的环节更多了:数据如何向量化、如何索引、如何支撑Agent的实时查询,这些都是DBA可以大展拳脚的方向。
大模型火了之后,数据库的角色确实变了。从“存数据的地方”,变成了“撑AI的底座”。RAG需要向量检索,Agent需要记忆持久化,工具调用需要可靠的执行层,这些需求全都压在数据库身上。
对于DBA而言,与其焦虑被替代,不如先搞清楚数据库在AI体系中到底扮演什么角色。弄清楚了,方向自然就清晰了。




