光子集成芯片(PIC)凭借其高带宽、低损耗与高速传输等显著优势,早已成为光通信、数据中心光互连、激光雷达、增强现实及虚拟现实显示、光学计算等领域的核心关键技术。然而,长期以来,光子器件的设计高度依赖人工反复迭代,这个过程涉及电磁学、半导体物理、射频工程、版图设计等多学科交叉,单个器件从零开始探索,周期通常需要数周甚至数月。若要构建一个完整系统,所需时间更是难以预估。这种效率显然无法跟上产业化的快速发展节奏。
2026年6月2日,Flexcompute公司的研究团队在arXiv上发表了一篇题为《面向光子学的自主智能体设计》的论文。他们提出了一种基于通用大语言模型的自主智能体光子设计方法论。引人注目的是,该方法无需定制专用模型,仅通过让一个商业编码助手学会调用数值仿真工具并执行设计规则检查,便能驱动“几何方案提出-数值仿真-性能评估-参数迭代”的完整闭环,自主完成从无源器件到有源系统的多物理场耦合设计。最终生成的器件性能已直接对标顶级文献中的先进水平。
自主智能体光子设计框架
该框架的核心思路清晰明确:以通用大语言模型为核心执行单元,以可编程数值仿真器作为客观性能评估器,并结合可量化的性能指标与制造约束,实现一个无需人工干预的内层设计循环。
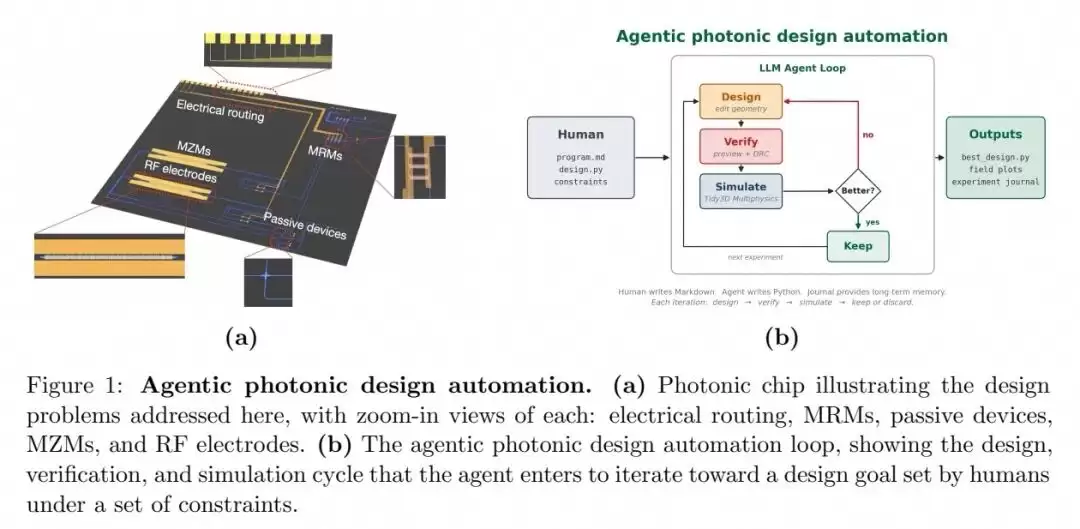
工程师需要提供的初始输入包括:一份明确的设计目标与约束指令文档、一个可编辑的几何参数与材料属性仿真模板、一组用于启动仿真、几何预览及DRC的脚本文件,以及作为智能体长时记忆的运行日志。此后,智能体便进入自主迭代过程:它会基于文献调研和历史记录提出几何形状或参数调整方案,通过广义DRC验证设计的物理合理性与可制造性,调用数值仿真工具获取性能指标,对比当前设计与历史最优性能,保留有效改进或回滚无效尝试。该过程不断重复,直至所有验收准则均被满足。
值得一提的是,所有实验均使用了Anthropic公司的Claude Opus 4.7大语言模型(Max Effort模式),这充分证明了通用编码助手在复杂工程设计任务中的强大能力。此外,该方法具有良好的可扩展性,理论上可推广至任何结合数值仿真与可量化评估准则的工程设计问题。
单域设计任务验证
研究团队首先在四类典型的光子芯片设计任务上验证了该框架,覆盖了无源电磁仿真、有源载流子输运仿真、射频全波仿真以及芯片级电布线等核心领域。
无源器件设计
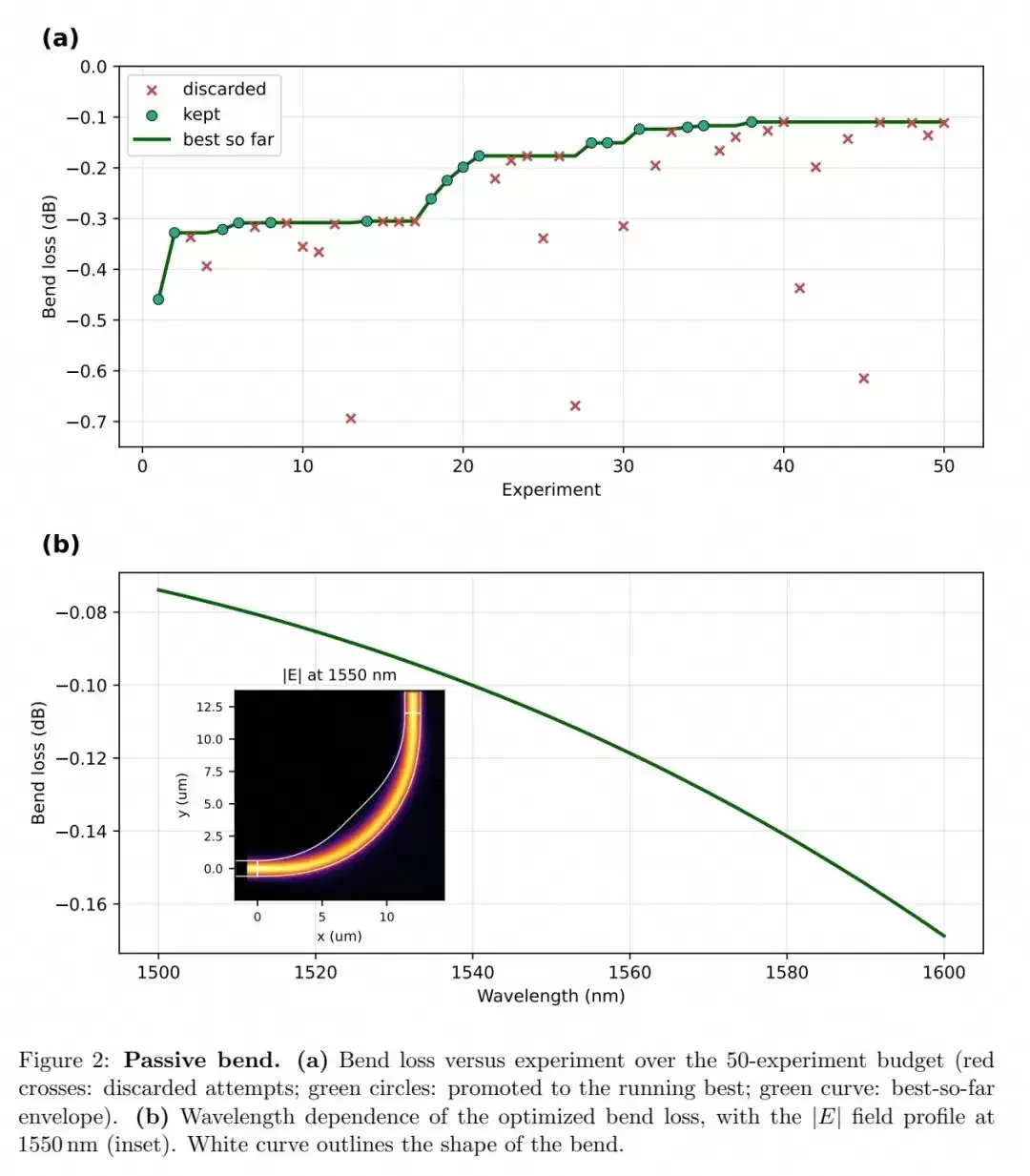
他们在氮化硅与220nm绝缘体上硅两种主流平台上,验证了五类基础无源器件的自主设计能力:SiN紧凑型波导弯曲、SOI平台的1×2多模干涉分束器、波导锥度、部分刻蚀聚焦光栅耦合器以及波导交叉。结果十分理想,所有器件均在预设迭代预算内达到了卓越性能:12μm半径SiN波导弯曲损耗为0.109dB,1×2分束器插入损耗为0.015dB,6μm长0.5-5μm锥度插入损耗为0.114dB,聚焦光栅耦合器峰值耦合损耗为2.89dB,6μm×6μm波导交叉插入损耗为0.11dB。

以12μm半径SiN波导弯曲为例,初始圆形弯曲的基模传输效率仅为89.96%(对应损耗0.460dB)。智能体仅通过50次迭代,依赖三步基于物理原理的改进,即将传输效率提升至97.51%(对应损耗0.109dB),损耗降低了约4倍:首先将圆形弯曲替换为欧拉分数为0.45的欧拉-圆形-欧拉混合弯曲,消除了曲率突变导致的模式失配;随后引入正弦平方包络的宽度调制,在曲率最大处将波导宽度从1.2μm平滑加宽至2.4μm,增强了弯曲模式的光场限制;最后加入向内径向偏移,进一步优化有效曲率分布。最终设计的性能与已发表的同半径波导弯曲文献结果相当。
有源器件设计
硅微环调制器是高速光互连系统的核心有源器件,其性能由调制效率与结电容之间的权衡关系决定。最小化VπL·Cj乘积,是降低驱动电压、减小功耗、提升带宽的关键所在。
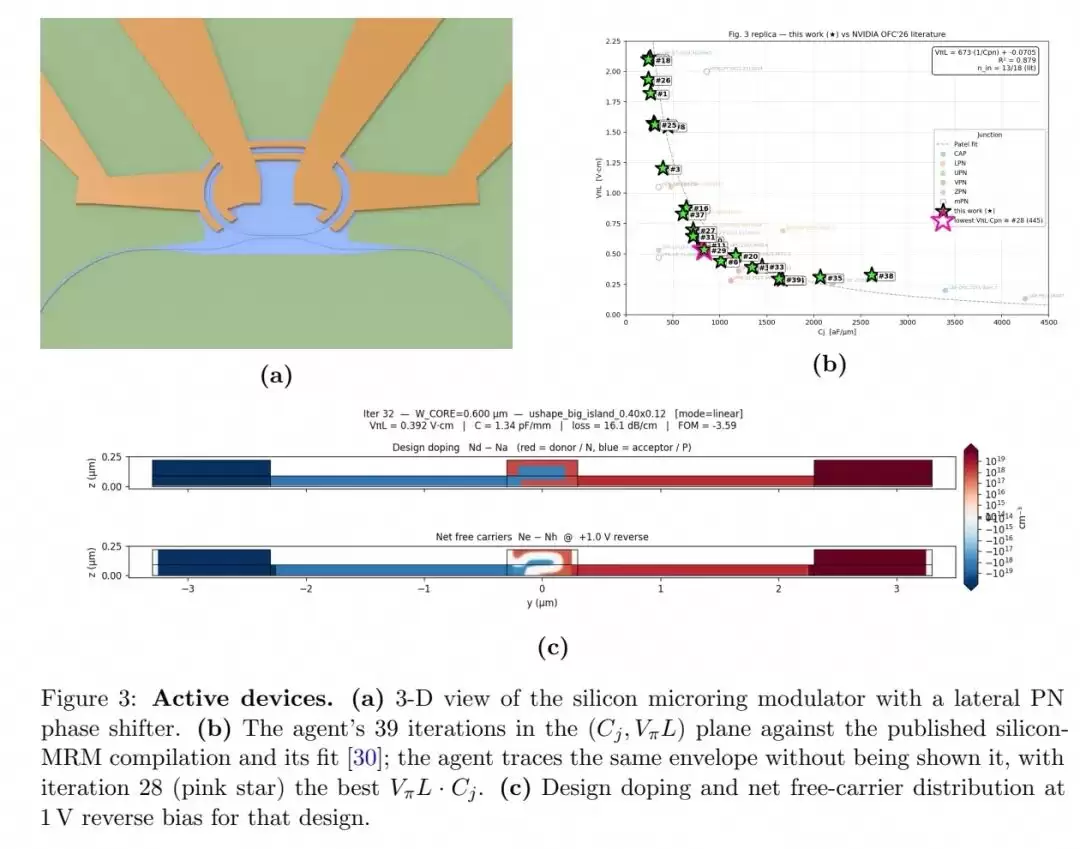
本次实验中,研究团队要求智能体在没有任何先验知识的条件下,优化横向PN结相移器的VπL·Cj乘积。每次评估都需要耦合稳态漂移扩散载流子输运仿真与五个反向偏置点下的光模求解。智能体在39次迭代中探索了六种结拓扑结构,并自主绘制出了完整的VπL-Cj权衡曲线。

最优设计是一个带有300nm×100nm埋入P岛的U形结结构,P岛埋在硅片上方50nm处,内外掺杂浓度均为7×10¹⁷cm⁻³。在1V反向偏置下,VπL=0.53V·cm,Cj=0.83pF/mm,乘积约为4.4V·pF。更关键的是,智能体独立得到的权衡曲线,与Nvidia公司在OFC 2026会议上发布的、汇总了过去十年硅MRM研究成果的曲线高度吻合。
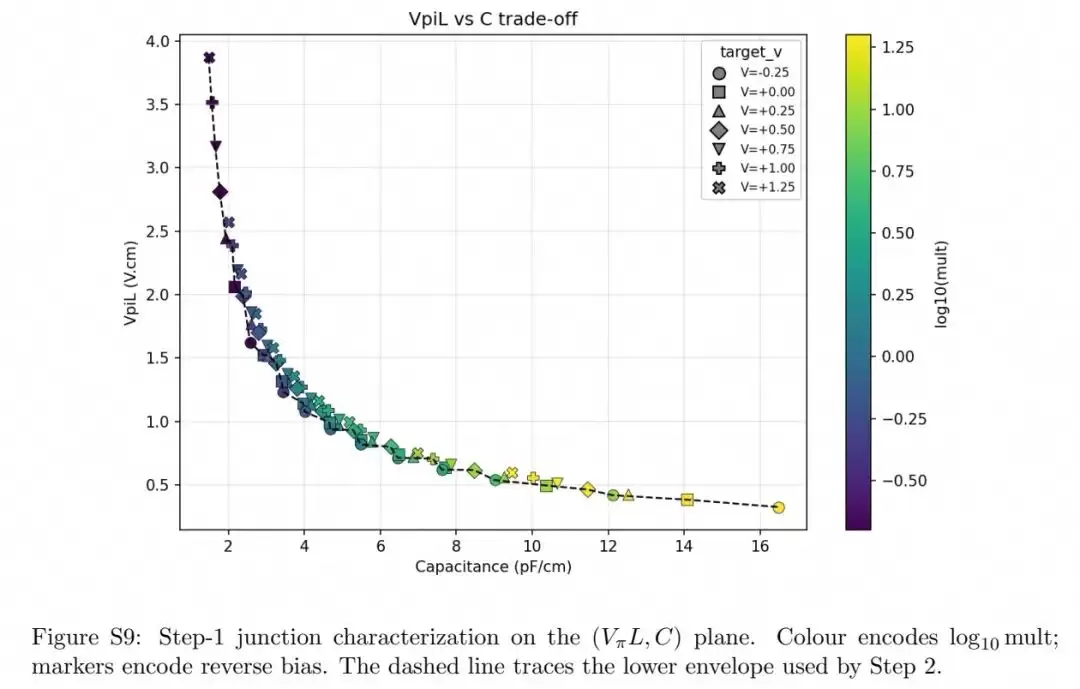
为确保设计的物理合理性与可制造性,他们还引入了广义DRC机制,该机制能够自动检测不可制造的亚100nm掺杂,以及耗尽区与光模场不重叠的无效设计,在仿真执行前就过滤掉无意义的候选方案,显著提升了迭代效率。
射频电极设计
高速行波调制器的带宽最终由射频传输线电极的性能决定,需要同时满足低微波损耗、光-微波速度匹配以及50Ω特征阻抗匹配这三个相互竞争的设计目标。
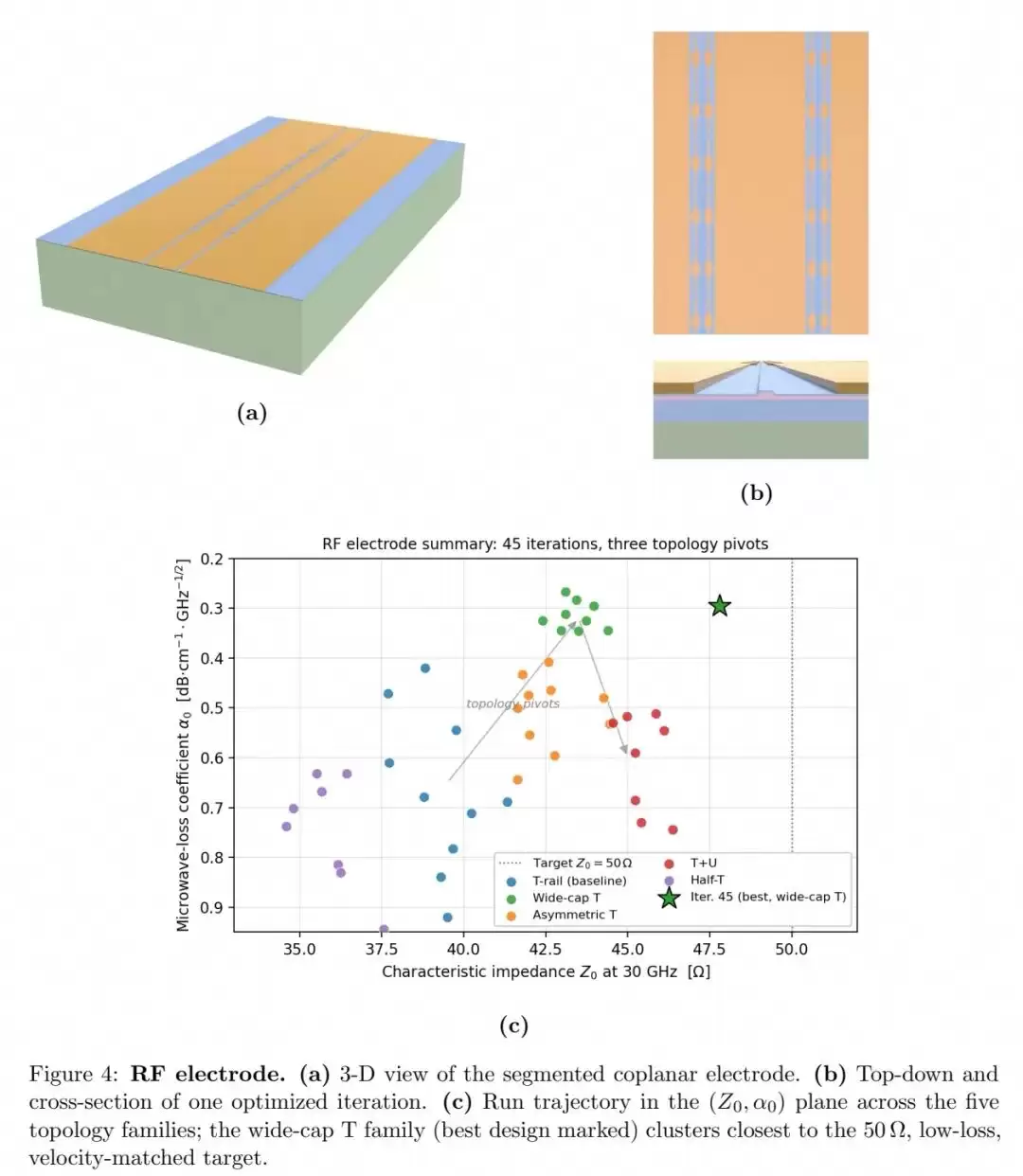
本任务要求智能体优化分段慢波共面电极结构。智能体在45次迭代中遍历了五种电极拓扑家族,当发现当前拓扑的性能进入平台期时,它会基于自身运行日志自主切换拓扑并提出新的优化假设。例如,它最初假设缩短T轨间距会增加单位长度电容,但仿真结果却显示相邻T轨会产生相互屏蔽效应,于是转而增加单个T轨的横向长度;随后又提出了宽帽T轨拓扑,在不显著增加串联电阻的前提下提升高频电容,有效降低了微波损耗。
最终的宽帽T轨设计采用53μm横向T轨、15μm×8μm顶部电容帽及12μm共面波导间隙,在5-45GHz频率范围内实现了特征阻抗Z0≈43-44Ω,微波损耗系数α0≈0.29-0.36dB·cm⁻¹·GHz⁻¹/²,相比普通T轨基线的0.5-0.8dB·cm⁻¹·GHz⁻¹/²降低了近50%。
更令人印象深刻的是,在运行过程中,智能体还自主发现并修正了三个仿真基础设置问题:波端口域过小导致的模式误识别、特定参数组合下相邻T顶重叠的几何构建缺陷,以及导体损耗提取中的带边伪影。这种“自我纠错”能力,在传统自动化流程中是很难见到的。
芯片级电布线设计
电布线是光子芯片设计中最繁琐的环节之一,需要在满足制造规则的前提下,将几十个有源器件的引脚连接到芯片边缘的焊盘,同时还要避免走线交叉以及与光波导、加热器等敏感层的冲突。
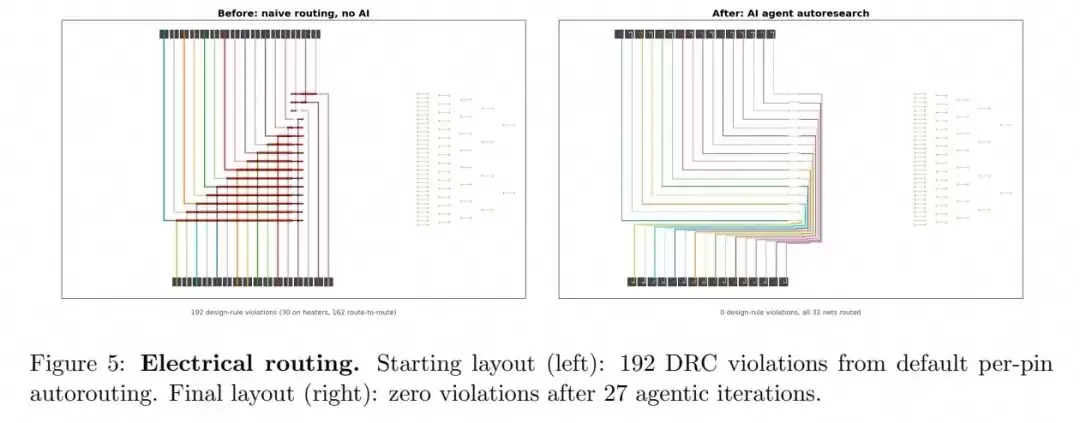
研究团队以一个包含32个金属接触点的投影芯片为测试案例。初始默认的逐点自动布线产生了192个DRC违规,包括30个加热器穿越和162个走线交叉。智能体在27次迭代、总耗时2分25秒内便成功将违规数清零。要知道,人类工程师完成同样的工作通常需要2至3小时。
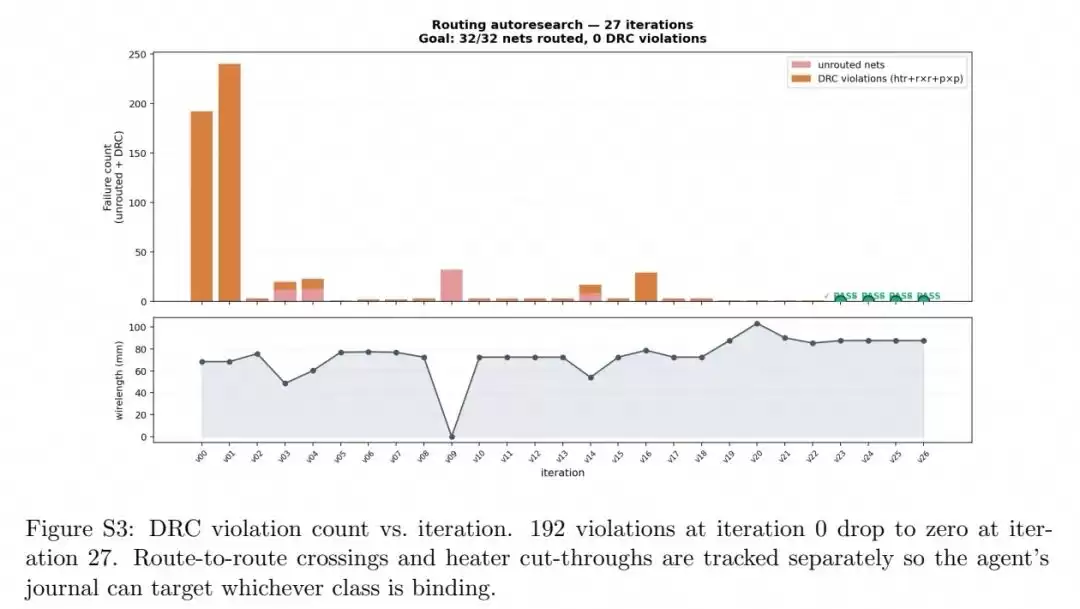
智能体采用的优化策略完全是自主生成的:首先将独立逐点布线切换为全局网格规划器,让所有网络共享布线资源;然后将加热器标记为膨胀障碍物,强制走线绕开;接着重新分配引脚-焊盘配对,消除不必要的交叉;最后加宽焊盘行以容纳成束的走线,并针对单个靠近加热器的引脚添加局部约束。这一结果充分证明,同一个智能体框架不仅适用于连续几何优化问题,也能有效解决离散组合优化问题。
端到端多物理场调制器设计
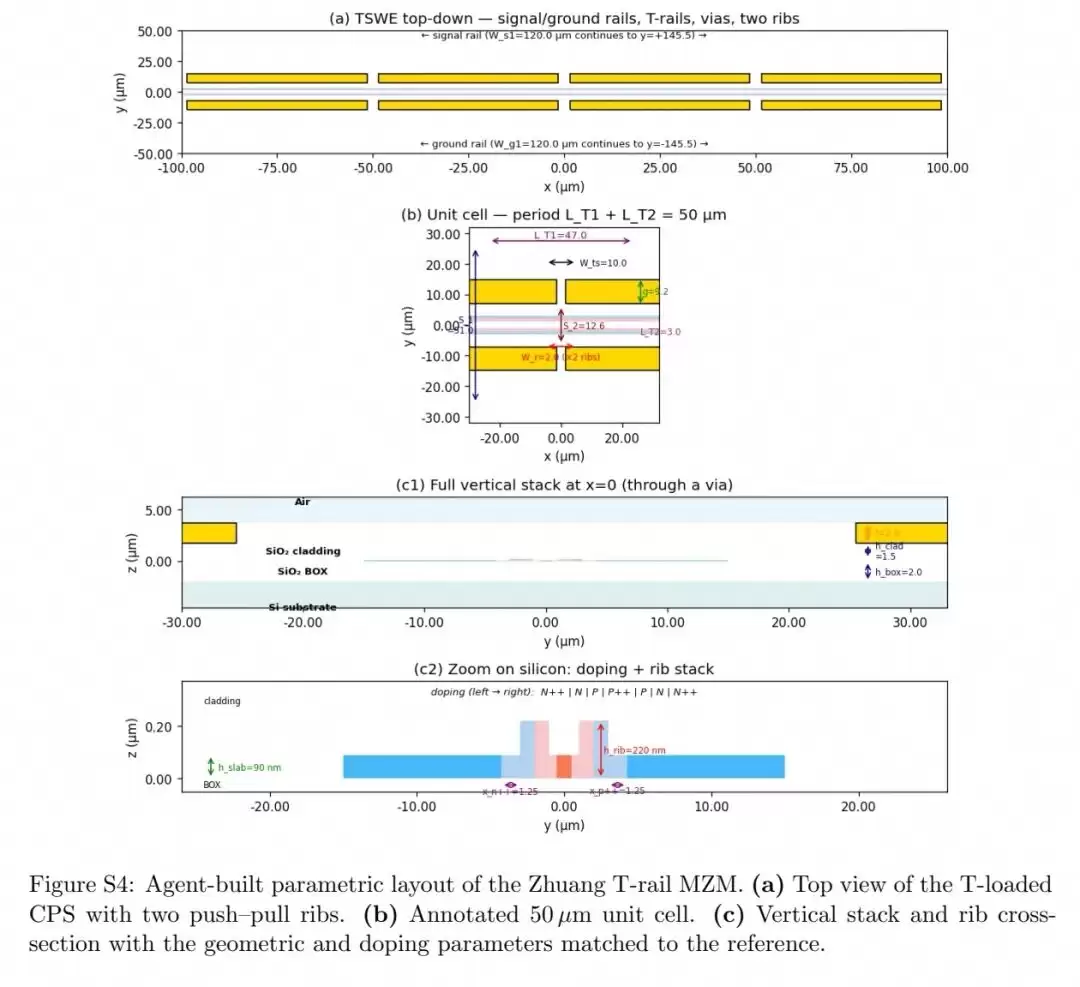
在验证完单域设计能力后,研究团队将所有元素整合起来,实现了完整硅马赫-曾德尔调制器的端到端多物理场自主设计,成功复现并优化了Zhuang等人2024年发表的T轨慢波MZM结构。
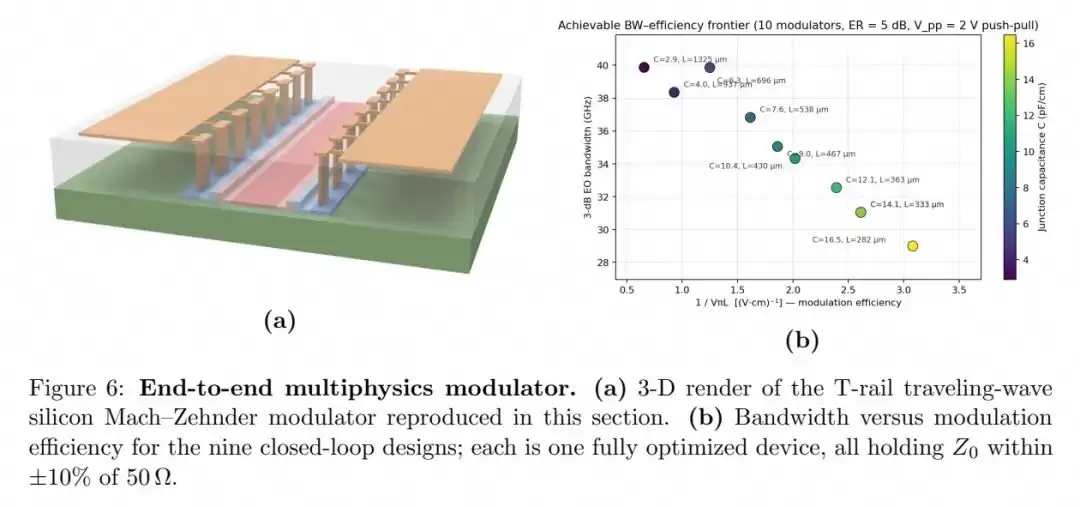
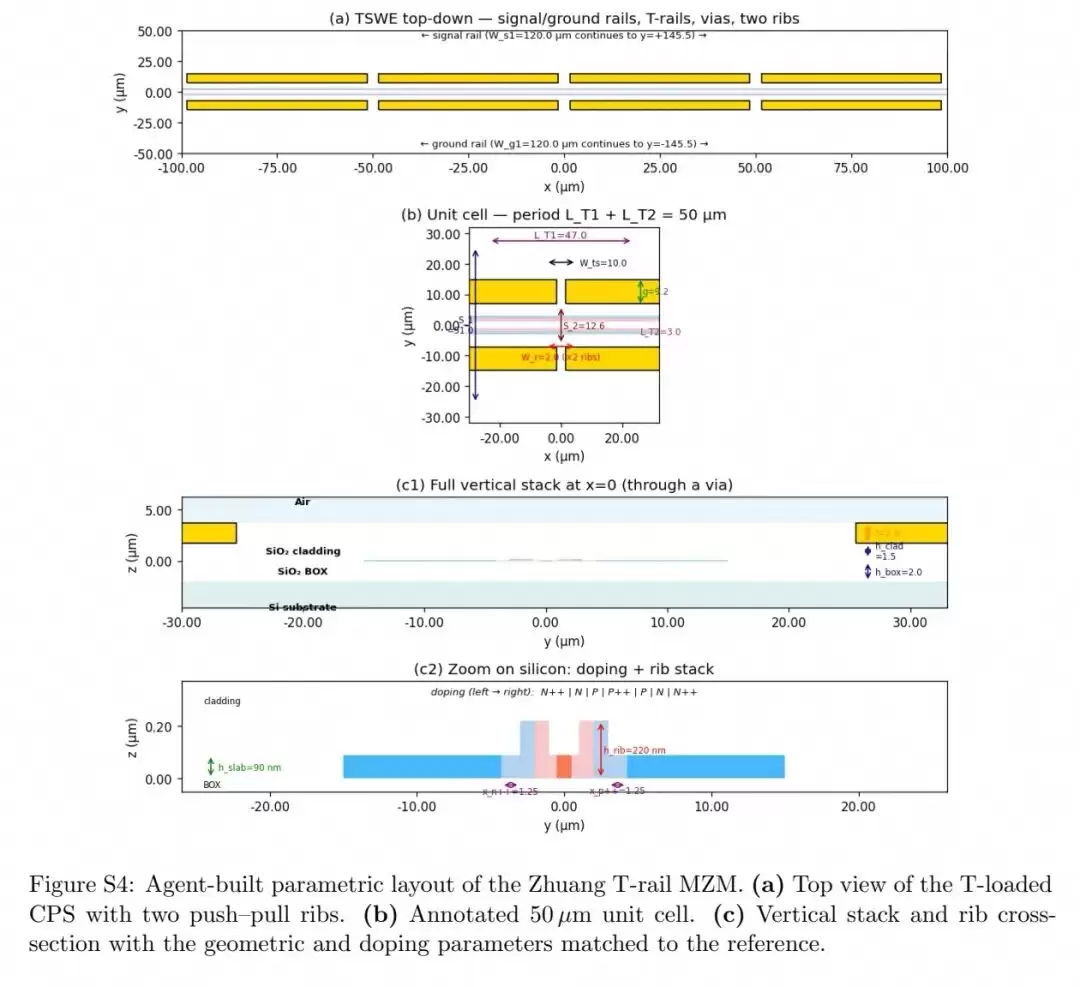
该调制器的设计需要同时协调版图、载流子输运、光模与射频仿真四个耦合的物理域。智能体首先自主搭建了完整的多物理场仿真流水线,但初始尝试遇到了两个问题:周期性加载截面的波端口模式误识别,以及结并联导纳的重复计算。当人类工程师修正了这两个初始设置问题后,智能体便进入了自主闭环优化。
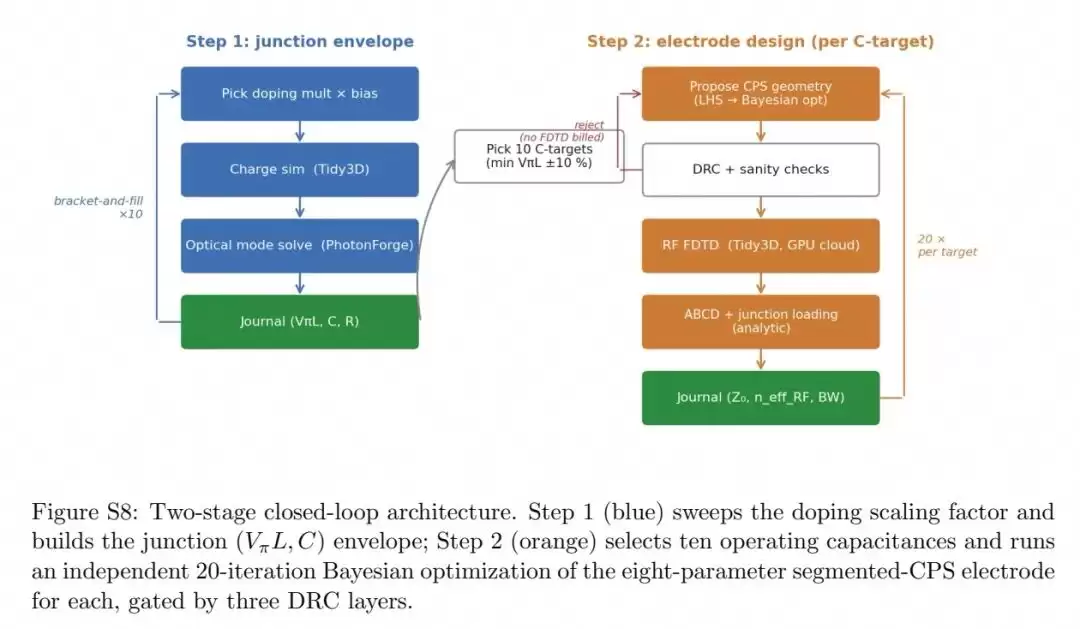
优化采用了双循环架构:第一步扫描掺杂缩放因子,生成PN结的VπL-Cj权衡曲线下包络;第二步从包络中选择10个工作电容点,每个点独立进行8参数电极的20次迭代贝叶斯优化。所有迭代都必须通过三层DRC检查:制造规则约束、固定工艺与材料栈约束、仿真设置合理性检查。
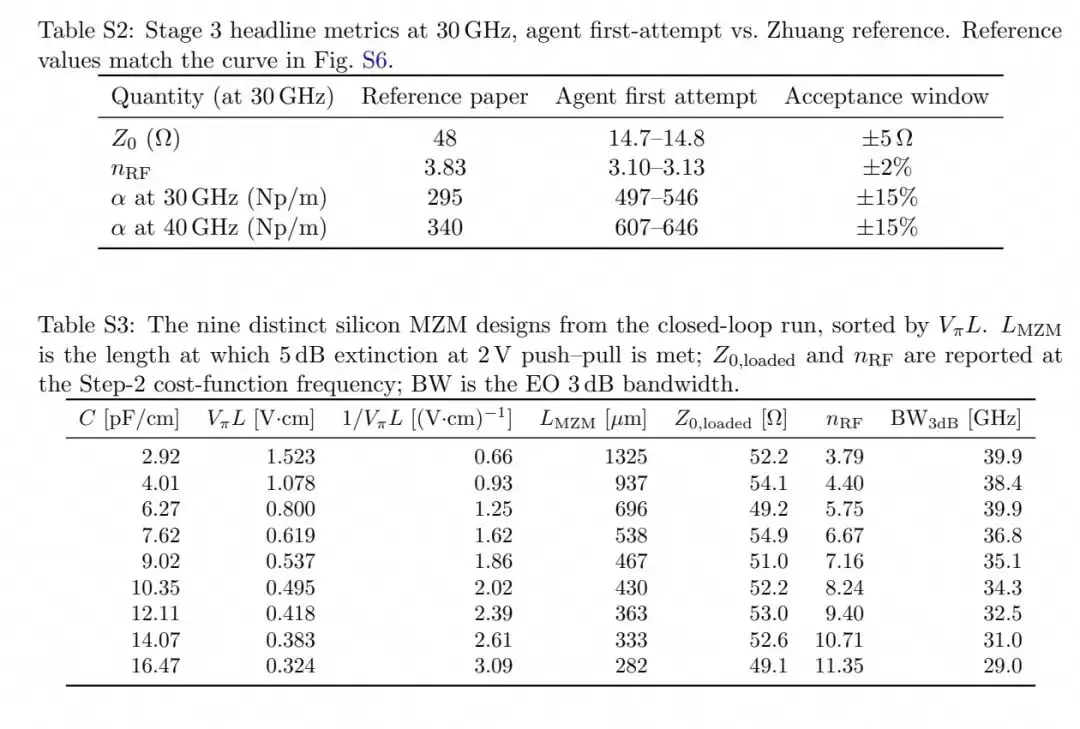
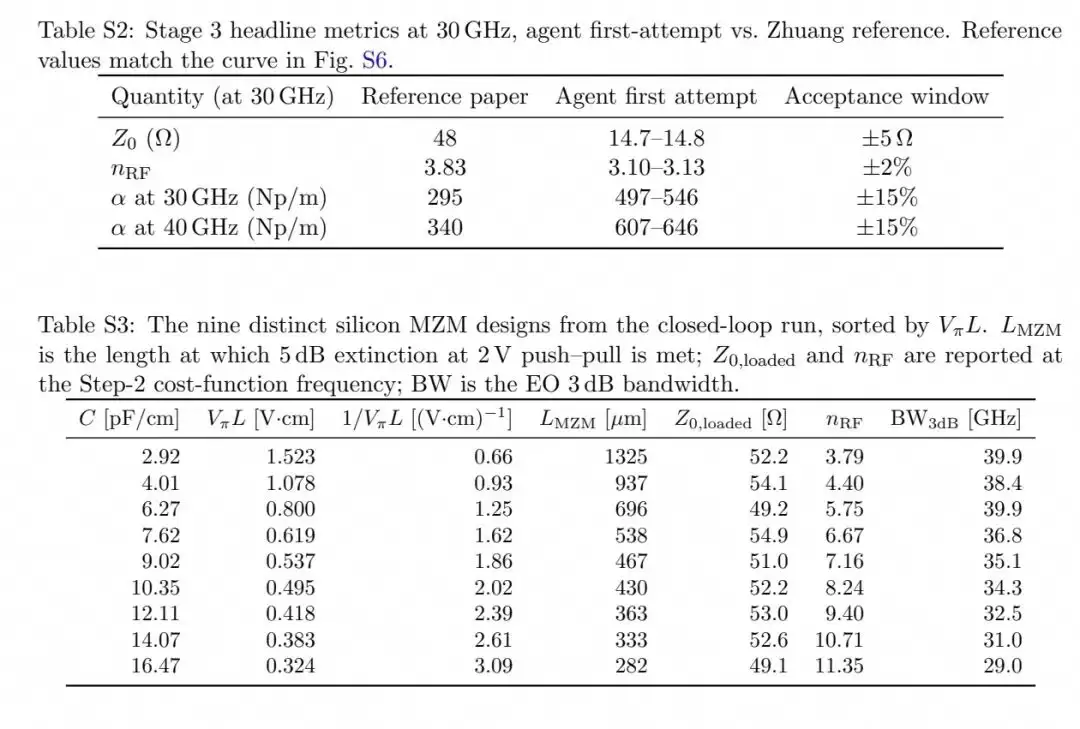
最终,智能体生成了9款性能各异的MZM设计,所有设计的加载特征阻抗都保持在50Ω±10%以内,覆盖了从29GHz到40GHz的完整带宽-效率权衡前沿:最短的282μm器件实现了29GHz带宽与0.324V·cm的VπL,最长的1325μm器件实现了40GHz带宽与1.523V·cm的VπL。
讨论与结论
这项研究首次证明,单一的自主智能体框架可以协调无源器件、有源器件、射频电极与版图布线,跨多个物理域自主设计出达到文献先进水平的光子器件。成功的关键在于两个核心基础:可编程的多物理场仿真与评估工具,以及具备足够代码生成与逻辑推理能力的前沿大语言模型。
与传统梯度下降逆向设计方法相比,智能体驱动的设计是互补而非替代的关系。智能体可以自主调用逆设计优化器作为工具,同时具备逆设计所不具备的能力,包括提出新的参数化方式、切换拓扑结构、处理离散决策(如布线、材料选择)以及制定预算感知的停止规则。
当然,目前这个系统仍然需要人类工程师提供问题定义、验收准则与初始仿真设置。未来的研究方向,是将问题初始化、仿真搭建、指标定义等工作逐步迁移给智能体,再结合流片与测试结果,实现从设计到测量的完整闭环。随着技术不断成熟,工程师的角色也将从监督执行,逐步转变为监督意图。这,才是真正的未来方向。




