人工智能究竟能释放多大的能量?这不仅取决于算力、数据与算法架构,更关键的因素在于人的参与与引导。
如今,AI已成为全球规模最大的“在线医生”。无论是年长者还是学生,只要身体稍有不适,许多人首先想到的就是向AI咨询。
AI“行医”已有三年,虽然解决了不少问题,但也随之带来了一系列新的挑战。
许多普通用户难以区分通用AI与专业AI的差别,习惯将日常使用的通用语言模型视为万能工具,由此引发的失误令人痛心:有人手指被夹断后,按照某通用AI的建议用盐水浸泡断指,结果彻底失去了再植机会。而当另一位用户将同样问题抛给专业医疗AI时,得到的明确答案是——千万不可用盐水保存断指。
AI固然好用,但如果把它当作唯一的“主治医师”,对这项仍在快速演进的技术而言,无异于揠苗助长。
更现实且可靠的方案是:先由AI提供初步解答,再邀请真人医生进行复核把关,让专业医生参与关键环节。
01 生物老师能看病吗?
2025年,谷歌推出的一款AI工具——NotebookLM迅速走红。
在众多优秀的通用模型中,这个后起之秀之所以能异军突起,原因很简单:它专业且精准。
NotebookLM仅基于用户上传的有限资料进行回答,就像一位终身只钻研一本专著的学者,其专业性远胜于所谓的“博学家”。如果将同样的资料交给通用AI处理,不仅理解深度不足,甚至会出现大量错误和幻觉。
连查询资料都会出错,通用模型在医疗领域的失误自然也就不足为奇了。它们无疑是全球最强大的模型,但本质上只是“博学家”。如果说专业医疗AI相当于“全科医生”,那么通用AI最多只能算是一名生物老师——甚至可能连生物老师都算不上,充其量是县里的秀才。
生物老师和秀才能够看病吗?或许比普通人强一些,但距离专业医生还差得很远。
相比之下,专业的“硅基医生”——即专为医疗场景设计的AI工具——其准确度优势明显。不久前,长征医院在皮肤科诊间开展了一项100名患者的实测:患者候诊时先用阿福拍照皮肤问题并获得解答,随后再与医生诊断结果比对,发现阿福的识别判断与医生诊断高度吻合,基本一致率超过90%。
即便如此,专业医疗AI依然无法完全替代医生。就像自动驾驶的安全率已经很高,但目前还没有任何一家主流车企敢于宣称实现了L5级完全自动驾驶。因为涉及人身安全,哪怕0.1%的风险也不可容忍。
更何况,当前生成式AI的回答质量高度依赖于提问者的水平。
牛津大学的一项研究显示:在标准化的医疗问答测试中,AI的理论准确率可以达到94.9%。
这个数字看起来相当亮眼?但遗憾的是,那只是理想环境下的表现。当模拟真实临床场景或面向大众提供健康建议时,准确率会大幅下降。
原因很简单:绝大多数用户并不具备提出正确问题的能力。
这是当前大语言模型(LLM)的特性所致——AI医疗结果的准确性很大程度上取决于使用它的人。而当越来越多的普通人将“问AI”变成习惯,我们又怎能要求用户自身具备高超的提问技巧?
因此,引入真人医生参与把关,自然成为更优的解决方案。
02 AI有多强,取决于人
每一位独立坐诊的医生,都是从“打杂”起步的。作为人类创造的学生,AI也没有理由不遵循医生的成长规矩。
就像刚刚毕业的医学生一样,AI完全可以参与医疗健康服务,但真正的“主治医生”角色,仍需由真人担任。
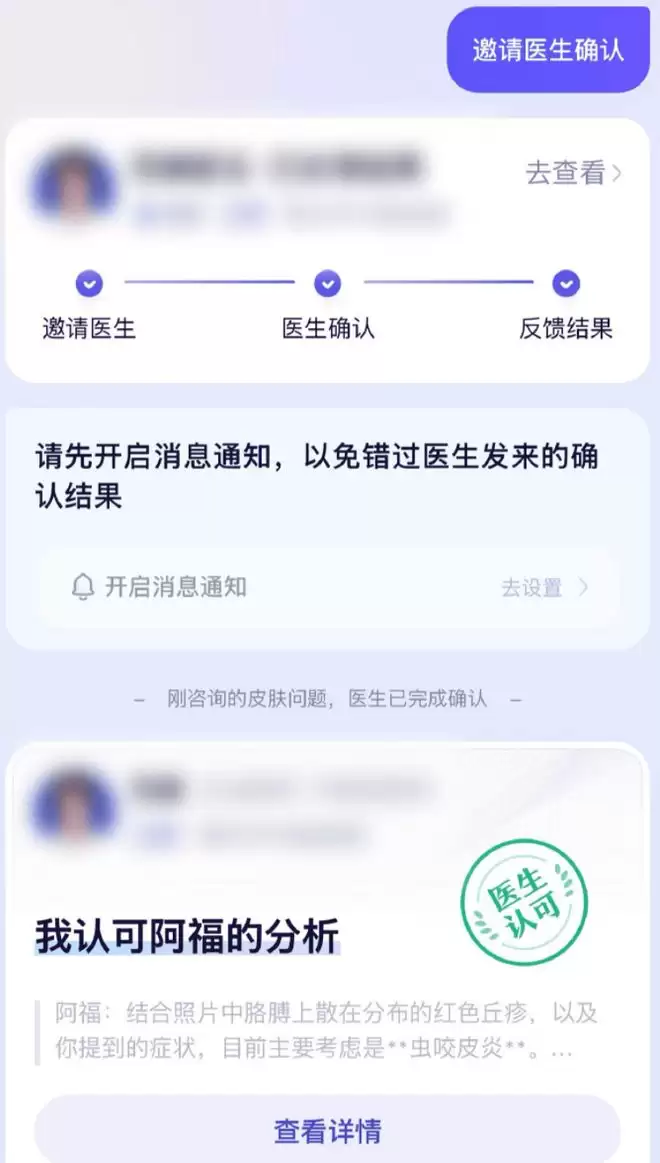
最近,阿福新尝试的“医生把关”功能引发了广泛关注。用户拍摄皮肤问题后,AI会先给出解答,随后可以邀请三甲医院的医生进行复核,为结果再加一道保障。
这一医生把关功能目前仍处于探索阶段,暂时仅适用于皮肤类咨询。其最直接的价值在于大幅提升准确度——专业医生与专业AI的双重确认,显然比单纯依赖AI更可靠。
如果医生认为患者提供的信息不够充分,还可以进一步引导用户补充资料。这是目前真人相较于AI的一大优势:虽然AI名字中含有“生成式”三个字,但它非常依赖用户的主动引导。
曾预言互联网未来的凯文·凯利认为,未来最好的医疗服务既不会单纯来自AI,也不会单纯来自真人医生,而是两者的有机结合。“AI+医生”,是他眼中最理想的医疗模式。

真人医生与AI的协作才刚刚拉开序幕。未来这一模式能拓展到多少领域,能衍生出哪些新型服务,目前还无法预知。
但可以确定的是,真人的介入,有望从整体上优化AI医疗的体验。准确度、流畅度、效率以及用户体验,都可能因为真人医生的参与而得到显著提升。
不久前,诺贝尔物理学奖得主Giorgio Parisi借助Claude证明了一个12年来未被证实的猜想。在整个论证过程中,他不断为AI指引方向,甚至及时纠正了AI的错误推理。这个故事充分说明:尽管AI实力强劲,但人的价值同样不可替代。

AI由人类创造,也由人类使用。它能释放出多大的能量,既取决于算力、数据和算法架构,更取决于人本身的智慧与判断。




