上半年,团队在进行技术咨询时,发现一个普遍痛点:他们利用大模型API搭建了一套“自动回复客服”——用户提问,模型直接作答。上线后却暴露出关键局限——模型知道“要查订单状态”,但它不会主动调用订单接口,只能机械回复“请您登录系统查看订单”。
团队成员忍不住抱怨:这算什么智能?跟一个高级搜索框有什么区别?
这个问题的答案其实很直白:他们做的只是大模型应用,而不是真正的Agent。
也有人反问:Agent不就是加了工具调用吗?这个理解只对了一半。工具调用是必要条件,但并非本质。Agent真正的蜕变,是从“生成答案”进化为“完成任务”。
这篇文章不堆砌概念,直接讲清楚三个关键问题:Agent到底比普通大模型多干了什么活?它的核心机制如何拆解?测试工程师现在能拿它做什么?
一、现象:大模型能聊天,但为什么不能干活
你问GPT:“帮我订一张明天北京到上海的机票。”它会回答:“我无法直接为您订票,建议您访问携程或航司官网。”这并非模型能力不足,而是它被设计成只输出文字。它没有权限、没有工具、没有执行能力。
最近,“AI Agent”这个词突然火了起来。AutoGPT、BabyAGI、LangChain的Agent模块、OpenAI的Assistant API……大家都在说Agent是LLM的下一站。但大部分人实际体验后的感受是:第一,配置复杂;第二,跑起来容易卡在循环里;第三,不知道跟直接调API到底差在哪。
核心原因在于没有理解Agent的工作模式。它不是一个更大的模型,而是一个“模型+执行器+存储器”的编排框架。
可以这样理解:大模型是大脑,Agent是大脑+手+备忘录。没有手的AI,只能聊天,不能干活。
二、本质变化:为什么会这样
普通的大模型应用走的是“单次问答”模式:用户输入→模型推理→输出结果,一次调用结束。模型没有状态,没有目标,也不会主动进行下一步。
Agent则完全不同。它运行一个“目标-规划-执行-观察”的循环。用户说“订机票”,Agent不会直接输出“我做不到”。它会先拆解任务:需要日期、目的地、预算。缺少信息就反问用户。拿到信息后调用查票接口,获取结果后再调用下单接口。每一步都依赖上一步的输出。
本质是把“一次性生成”变成了“多步推理+行动”。这个变化对工程意义重大,因为每一步都可能出错:工具调用失败、返回格式不对、模型理解错误。需要处理的事情比单次调用复杂一个数量级。但回报同样巨大:一个能闭环执行任务的系统,比一个只会回答的系统,价值高不止十倍。
这里需要强调一点:Agent的核心不是“调用工具”,而是“为了达成目标,自主决定下一步做什么”。
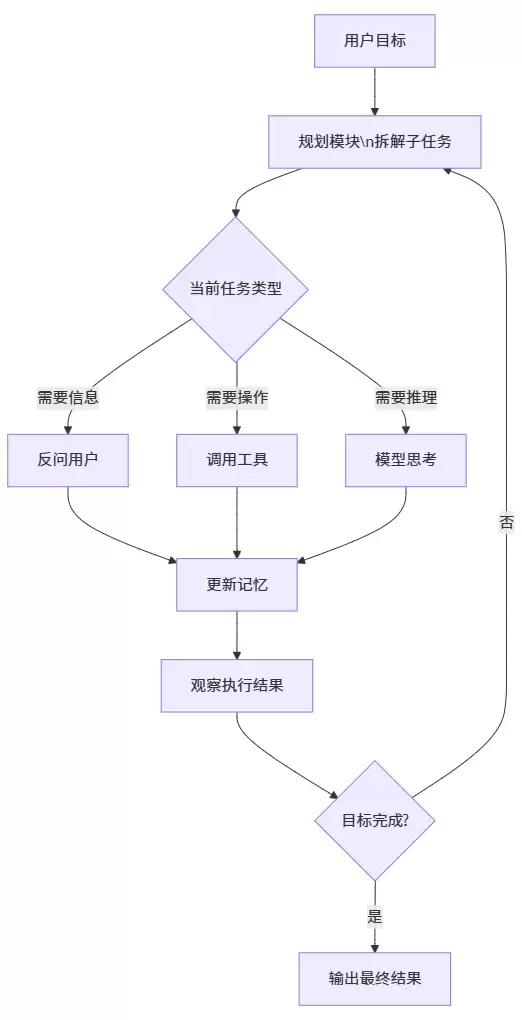
三、核心机制拆解:感知-规划-记忆-工具的四层闭环
一个标准的Agent架构,可以拆成四个模块。用测试工程师能听懂的语言来翻译一下。
第一层:感知
Agent需要知道当前状态——用户说了什么、上一步执行结果是什么、环境有什么变化。在测试场景里,感知可以包括:页面当前显示什么、接口返回了什么、日志里有没有报错。
第二层:规划
这是Agent的“大脑”。大模型把用户目标拆成一系列子任务。比如“测试登录功能”,规划可能是:打开登录页→输入正确账号密码→点击登录→验证跳转到首页→再测错误密码场景。规划可以是一次性生成,也可以是每做完一步重新规划(动态规划)。
第三层:记忆
Agent需要记住做过的事。短期记忆存当前对话的上下文,长期记忆存历史成功案例、工具使用经验。测试场景中,记忆可以让Agent记住:上次这个接口返回的token格式是这样的,下次可以直接复用。
第四层:工具
工具是Agent的“手”。API、数据库、浏览器、命令行、测试框架……任何可以调用的外部能力。关键点是:模型决定“什么时候用哪个工具,传什么参数”,而不是硬编码。
这个循环会一直跑,直到目标达成或遇到无法处理的错误。这就是为什么Agent有时候会陷入无限循环,工程上需要加最大迭代次数和早停机制的原因。
四、典型案例对比:同样是查天气,普通API vs Agent
普通API调用
你写代码:调用天气API,解析JSON,输出温度。代码固定,只能做这一件事。如果用户问“明天北京会下雨吗”,你的代码需要先判断意图、提取城市和日期,然后调用对应API。每增加一个能力,就要改代码。
Agent方式
你给Agent配两个工具:get_weather(city, date) 和 get_city_code(city_name)。用户问:“明天上海适不适合出门?”Agent自己推理:出门需要知道温度和降水概率。然后调用get_city_code(“上海”)拿到城市代码,再调用get_weather(代码, “明天”)。拿到结果后,模型根据“降水概率>50% 不适合”的规则输出“不建议出门,因为明天下雨”。你没写任何意图识别和分支逻辑,Agent自己组合了工具。
扩展到测试场景:假设你要测一个订单流程。给Agent配的工具是:click(element)、input_text、assert_exists、capture_screenshot。你输入:“测试一个用户从商品详情页加入购物车到下单成功的完整流程,断言最后出现‘订单已提交’。”Agent自己规划步骤:打开详情页→点击加入购物车→进入购物车→点击结算→填写地址→提交订单→断言“订单已提交”。中间如果某个元素找不到,Agent可以尝试其他定位方式,或者截图问你。
记住一点:Agent不是帮你省掉写代码,而是帮你省掉“把业务步骤翻译成代码”这个脑力活。
五、工程落地启示:测试场景里Agent最快能帮上忙的三个地方
如果你现在就想试试Agent,不用从头造。从这三个场景切入,投入产出比最高。
场景一:自动生成测试数据
传统方式:写SQL或调用数据构造接口,硬编码各种边界值。Agent方式:给Agent一个数据库写权限(只写测试库),说“生成100个用户,包含正常、特殊字符、超长三种类型”。Agent自己写INSERT语句并执行。
场景二:UI自动化自愈
传统UI自动化最头疼的是元素定位变化。Agent可以这样做:当Playwright找不到元素时,把页面截图和DOM传给Agent,Agent分析后给出新的定位表达式,或者用视觉识别直接点击。实测下来,对于常见布局变化,Agent能自动修复约60%的定位失效。
场景三:接口测试的智能断言
传统接口断言:写死预期值,比如“code=0, msg=success”。Agent可以把断言升级为语义检查。调用订单查询接口后,Agent验证返回的订单状态是否符合业务逻辑(比如已支付订单不能再次支付)。这种复杂约束,用代码写很啰嗦,Agent理解自然语言就能判断。
对于个人学习,推荐从LangChain或Semantic Kernel的Agent示例开始,跑通一个“工具调用”的Demo。不用多复杂,一个天气查询就够了。跑通之后,你就能理解Agent的循环逻辑。对于团队落地,不要一上来就做多Agent协作。先做一个单Agent、两个工具的POC,跑通后再加复杂度。
六、用一个问题收尾
这半年见过不少团队尝试Agent,成功的不多。失败的原因几乎一样:他们把Agent当成“更智能的API”,没有为它设计“观察-反馈”的环境和足够清晰的工具接口。Agent只有在“工具稳定、反馈明确、目标可拆解”的场景下才能发挥价值。
所以在你开始动手之前,不妨先问问自己:你现在手上有哪个测试任务,可以拆成3到5个明确的步骤,并且每个步骤都能通过一个工具(API、数据库、浏览器)完成?如果找得到,Agent就能帮你把它自动跑起来。如果找不到,先去做任务拆解——那是比学Agent更底层的能力。




