Claude Opus的智能感下降了吗?
你大概也有这种体验:它回复速度更快了,但似乎不如从前那么机敏。思考链条缩短了,有时候感觉就像跳过了不少本该仔细推敲的步骤——直接给出结论,却少了那种让人豁然开朗的惊喜效果。
如果只是个别用户这么认为,或许只是偶然感受。但当Reddit、推特以及各大社区里类似的吐槽相继涌现,这件事就不再是单纯的“感觉不对劲”。网络上甚至开始流传一些搞笑段子,说现在的Opus像被拔光鬃毛的雄狮,远远看去跟普通狗没什么两样。
一个更加直白的说法开始蔓延:Opus被削弱了。
这到底是真实情况吗?如果是,为什么会被削弱?
01 推理深度缩减约67%
起初只是零散的议论。有用户指出Claude Opus“变懒了”“表现不如从前”。偶尔犯下低级错误,或是在复杂任务里遗漏几轮推理——那种感觉就像平日里配合无间的同事,突然某天开始漫不经心。
遇到这种情况,多数人的本能反应是自我怀疑:是不是我的prompt写得不到位?还是这类任务本身就不适合它?或许只是偶然的失误吧?
但没过多久,Reddit的Claude讨论区里,相似的反馈开始密集涌现,且描述高度一致:有人说它不再仔细审读代码;有人提到它回答更快,却经常缺失关键环节;还有人发现它在长期任务中更容易“提前收工”,好像默认目标已经达成。

当不同用户在不同场景下反复遭遇同类问题,这就不再是单纯的“主观感受”了。更像是一种行为模式的系统性变迁——模型真的在发生变化。
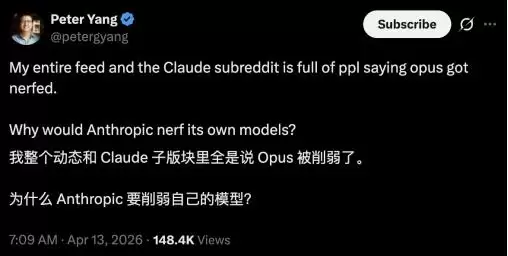
真正让讨论升温的是这个数据:有人在Claude Code的使用过程中,对历史交互日志做了对比,发现模型在复杂任务中的推理过程显著缩短——自2月更新以来,推理深度下降了大约67%。
作者本人坦诚地表示,这个67%是基于签名长度与思考内容长度的相关性估算,并非直接测量结果。加上一月份的日志已被删除,基线对比不够精确。相比之下,报告里更具参考价值的是那些行为层面的变化——比如read:edit(读取代码与修改代码的比率)从6.6降至2.0;3月8日之后,被stop hook捕捉到的违规行为达173次,而此前记录为零。

老实说,数据是否精确到小数点并不关键。重要的是,它让原本模糊的主观体验,第一次被量化为一个可讨论的趋势。
由此,一个新词汇开始在社区流行:“AI shrinkflation”(AI缩水式通胀)。缩水式通胀原本是经济学术语,指商品分量或数量减少而价格不变。放在这里含义也很直接——模型实际提供的能力减少了,但名字还是同一个名字。
02 能力打折,敷衍感从何而来
面对社区的热烈反应,Anthropic并未直接承认“模型变差”。Claude Code的开发负责人Boris给出的解释是,这些变化源于系统层的调整:工具调用方式、推理策略、资源分配机制——而非模型本身能力下降。
他举了个例子:在Claude Code中,部分问题其实源自工具链和系统prompt,并非模型自身;与此同时,在高负载环境下,系统需对算力、token和请求进行管控,自然会影响用户体验。最新版本中,Anthropic引入了一项叫做“自适应推理”(adaptive thinking)的机制——模型会根据任务难度,动态决定是否进行推理以及投入多少推理资源。
也就是说,并非模型变差了,而是模型开始自行判断要用多少算力。

从工程角度看,这是一种合理的优化:简单任务少思考,复杂任务多思考,整体效率自然提升。
但问题在于——效率优化和能力削弱,在用户体验层面并无差别。当一个模型开始更少阅读上下文、更快给出答案、更频繁地提前结束任务,用户感受到的不会是优化,而是敷衍。
更重要的是,这种“自适应推理”在感性上确实让人不太舒服。还是拿人际交往打比方:凭什么一开始好好的,用着用着就觉得我的事情不重要了?
这种不适感很快被另一个变化放大。Claude Mythos Preview——被Anthropic称为“能力跃迁的一代”——在代码与安全任务上表现远超以往,被限制性地提供给少数机构使用,用于加固“全球最关键的软件系统”。当“更强的新模型”与“体感变差的旧模型”同时出现,一个在社区中不断被提及的猜测开始成型:把旧模型削弱再抬升新模型,一捧一踩,显得新模型升级巨大。
这个逻辑没有直接证据,但它正被越来越多用户所接受。
03 模型不再稳定可靠
实际上,类似现象在AI行业并不新鲜。早在2024年就有研究对比了GPT-4在不同时间段的表现,发现同一模型在数月内,推理方式和输出行为都发生了明显变化——被解释为推理策略调整、安全策略收紧、成本与响应速度优化的叠加结果。

抛开阴谋论不谈,即便真的存在资源倾斜,这在AI行业也算常态。无论是OpenAI还是Google,几乎所有公司都会优先优化最新一代模型,而旧模型逐渐被边缘化。算力既是成本,也是生产力。当新模型的能力上限更高、潜在价值更大,将更多资源投入其中,本身就是理性的选择。在这个过程中,旧模型的状态自然发生变化——被“降权”、推理深度被压缩、资源分配被重新调整——这些都可以理解为工程上的取舍。
但理解归理解。新模型不对外开放给大众使用,旧模型又在毫无征兆的情况下变成这样,谁能轻易接受?

从用户视角看,最令人不满的其实不是模型“变蠢”,而是它的“不稳定”。当一个模型从稳定的工具变成一个会不断变化的系统,它自行做出了调整——没有提示,没有版本说明,也没有边界。作为用户,你不知它何时变了,不知它具体变了什么,更不知这种变化是否会影响你正在做的事情。
你只能感受到——它变了,变得不如以前好用了。
而这时候,一个新模型就摆在眼前,看起来更稳定、更可靠。于是选择变得微妙起来:不是你主动选择新模型,而是旧模型的变化将你推向更新的那一个。即便清楚,新模型也可能在某一天变成下一个旧模型,可能在某个节点猝不及防地“优化”成让人难受的版本——但在那一刻,差距已经摆在眼前。




