6月11日消息,AI图像生成领域迎来重要突破:智象未来(HiDream.ai)推出的商用版图像生成模型HiDream-O1-Image-1.5,在全球知名独立AI模型评测平台Artificial Analysis的文生图榜单(Text to Image Leaderboard)中斩获全球第二,综合评分仅次于OpenAI。
值得关注的是,该榜单采用了严格的评测机制:通过匿名对比、用户投票与ELO动态排名方式,最大程度降低品牌认知对结果的影响,真实还原用户在开放生成场景中的偏好判断。相比那些公开品牌信息的测试,这种匿名盲测的权威性和说服力明显更高。
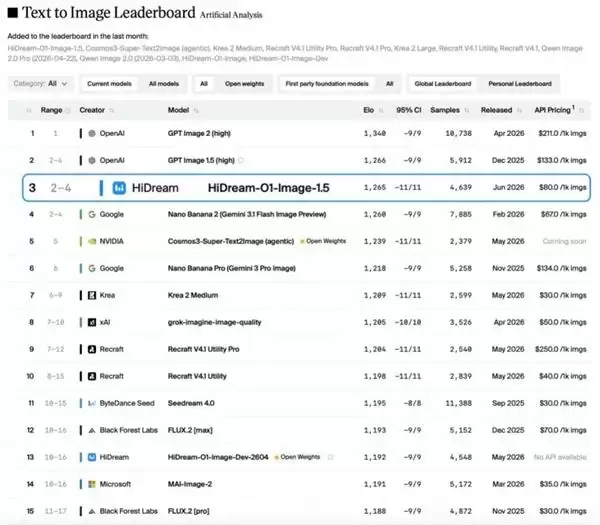
在这一专业评测体系下,HiDream-O1-Image-1.5在超过4000个样本的对比评测中获得1265的ELO评分。这一成绩不仅彰显了模型在图像质量方面的强大竞争力,也体现了其在语义理解、复杂画面生成、文字渲染以及多主体控制等综合能力上的显著提升。
事实上,就在半个月前,智象未来HiDream-O1系列的开源模型HiDream-O1-Image-Dev-2604已在同一榜单的开源模型类别中夺得全球第一。开源版本的成功验证了其像素级原生全模态架构在开放评测与开发者社区中的可行性,为后续商用版本的推出奠定了坚实基础。

此次表现突出的商用版本HiDream-O1-Image-1.5,进一步聚焦于广告营销、品牌设计、电商视觉、游戏内容、影视分镜、IP创作等高要求的商业场景。从实际表现来看,该模型在图像质量、文字渲染、复杂排版、多主体一致性以及视觉叙事能力等方面均展现出卓越实力。
核心技术:原生全模态架构
HiDream-O1-Image-1.5的技术核心在于其原生全模态架构——Unified Transformer(UiT)。
与传统的文生图模型采用的“文本编码器 + VAE + 扩散模型”模块化拼装路径不同,UiT从底层将图像像素、文本Token、视频体素以及音频、动作、空间关系等原始信号映射至同一个共享Token空间,再由同一套Transformer完成理解、生成与推理全流程。

这意味着模型无需在不同模态之间反复转换信息,从而在文字密集排版、多主体生成、分镜叙事等复杂任务中,显著降低了细节损耗和语义错位问题。从理论上看,这种架构在处理高要求的商业场景时具备天然优势。
从更长远的视角来看,智象未来的目标是构建原生全模态世界模型。其核心理念是:一张图像承载着现实世界某一时刻的主体、空间、材质、光影与关系——只有先稳定理解并生成这些静态状态,模型才有能力进一步处理连续时间中的运动、因果、镜头和叙事。
HiDream-O1-Image-1.5的出色表现,在某种程度上验证了UiT架构的可扩展性,也为后续的多图一致性、视频首帧生成乃至长视频生成提供了更稳定的底层能力。这或许才是这一技术突破最有价值的意义所在。




