数据采集与治理,正成为制约具身智能产业发展的核心瓶颈。
试想一下,大语言模型训练可以调用万亿级数据,而具身智能所需的数据却必须从真实物理环境中逐一“采集”回来。采集难度大、成本高昂、数据可用性低、跨本体迁移困难——这几座大山长期压着行业。如何建立高效可复用的采集机制,开放共建高质量数据集,已成为整个产业的当务之急。
近日,自变量机器人开源的一套软硬一体方案——XRZero-G0,正强力回应这些行业痛点。论文发布当周便冲上alphaXiv趋势热榜前十,迅速引发业界广泛关注。该系统通过在硬件层增加头部视角,在软件层构建多视角交叉约束、限位检测和真机成功率检测,搭建起一套科学的数据采集与治理体系。
更值得关注的是,他们同步开放了2000多小时、覆盖3000个任务的多模态全身无本体数据集 G0-Dataset。令人印象深刻的是,实验表明:用10份无本体数据配合1份真机数据混合训练,效果竟然与同等规模的纯真机数据不相上下。采用这些数据训练的模型,不仅摆脱了对固定本体姿态和型号的过拟合,还展现出出色的零样本迁移能力。
这也是国内首个大规模跑通“全身无本体采集→自动质检→混合训练→真机评测”全闭环的工作。可以说,它构建了一条规模化采集数据、形成迭代飞轮的可实践路径。

XRZero-G0 整合无本体数据采集、闭环质检和数据配比方案
软硬一体保障数据高可用,有效率提升至85%以上
先说硬件层面。XRZero-G0做了一个看似简单却关键的改进:增加头部摄像头,并将其数据与腕部两个视角严格对齐。在同等采集量下,训练效率更高,混合收益也明显更稳定。
软件层面的动作更值得深入剖析。它将数据质量管控前置到采集阶段,构建了三层递进的自动质检和筛选机制,不再等到训练时才去处理低质量数据:
第一层,观测层。利用多个视角、多个时间点的数据反复交叉验证,防止视觉与运动的误差被不断放大。第二层,动力学层。将外部动作数据翻译为目标机器人自身可执行的动作,避免自碰撞、关节限位或力矩超限,使数据筛选从“定性”变为100%可验证的流程。第三层,策略层。以真机开放回环执行的成功率,作为数据可用的最终判据。
这套方法论将数据治理从“采集端的工艺优化”延伸到了“训练端的分布对齐”,让无本体数据也能达到与真机数据相当的可信度和可执行性。坦率地说,这为以全身无本体数据为基础的预训练范式,打开了全新的可能。
发明“真机:无本体”数据“黄金配比”,数据成本降低至1/20
在具身智能领域,用真机数据与无本体数据混合训练已成为行业共识。但关键问题在于:两者究竟该以什么比例混合?过去一直缺乏科学依据。
自变量通过后训练阶段的对照实验,得出了一个可复现的答案:10份无本体数据搭配1份真机数据,效果等同于同等规模的纯真机数据。简而言之,无本体数据让模型见多识广,学会常识和动作规划;真机数据则帮助模型“查漏补缺”,修正电机延迟、本体差异、摩擦力等物理细节。两者结合,能将获取训练数据的成本压缩至原来的1/20。
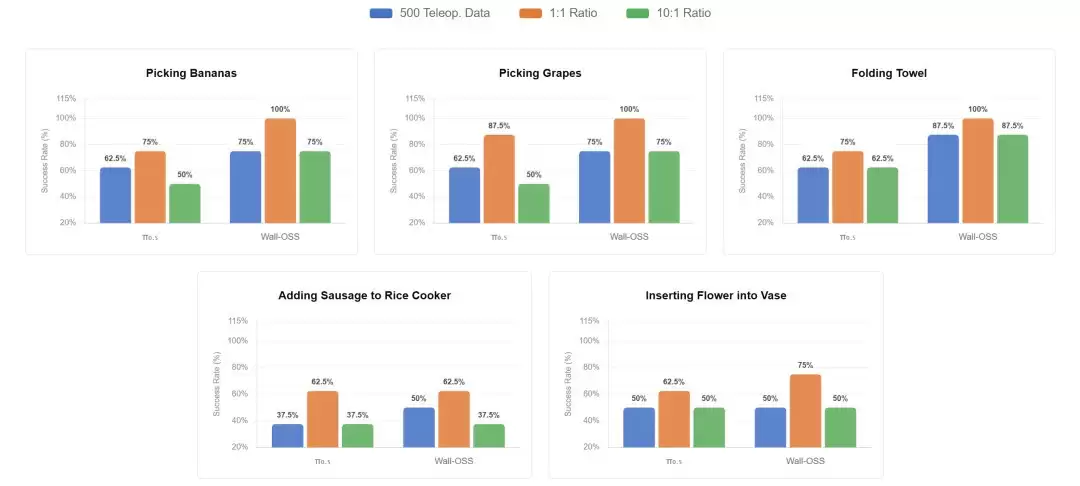
数据配比方案效果实测
更为关键的是,真机实验表明,这种“混合配方”还带来了两个意想不到的优势:一是摆脱了对固定本体姿态的过拟合,能够适应不同工作台角度、站位和视角;二是实现了跨本体的零样本迁移能力,即便在从未“见过”的机器人本体上也能零样本部署,无需针对性微调。
这些实验足以证明,自变量构建的这套数据采集与治理方法,以及将真机和无本体数据混合训练的系统化路径,并非权宜之计,而是能够真正支撑具身模型走向规模化的可行方案。
开放首批无本体数据集,构建具身行业数据基础设施
真实物理环境的数据,正成为具身智能模型发展的“稀缺燃料”。不少企业和团队都在自建采集流程,但这使整个行业陷入了“数据孤岛”的困局。而自变量机器人的选择,是打破这一局面。
目前,第一批无本体数据集已在Huggingface平台上线,技术报告也已发布于arXiv。从硬件搭建、自动化质检流水线到混合数据配比的后训练策略,整套方案均可复现使用。相关论文和数据集的公开,在alphaXiv和国内社区引发了广泛讨论。
或许,这标志着具身智能产业开始告别“盲采盲训”的摸索阶段,向更加系统、更为开放的未来迈进。




