正式开源仅一周多,GitHub 星标数已突破 1,500,并成功登顶 HuggingFace 趋势榜——商汤 SenseNova U1 在开发者社区中引发的关注度,与其技术野心一样非同寻常。它的核心突破在于,将多模态理解与生成这两项任务,真正融合进了同一个智能大脑中。
开发者社区为什么如此关注?除了惊叹于其惊艳的效果,更有一个底层问题被反复讨论:为什么这次连 VAE 也被彻底移除了?从 Stable Diffusion 到 FLUX,几乎所有主流扩散模型都依赖变分自编码器(VAE)将图像压缩到潜空间,这已构成近年来图像生成技术栈的基石。然而,SenseNova U1 的 NEO-unify 架构选择直接拆除这一组件,在像素层面进行端到端的语言与视觉联合建模。这并非简单的工程优化,而是一次架构层面的根本性选择。
在 HuggingFace 社区的热门讨论中,诸如「能否在单张 RTX 5090 上运行」、「是否会推出更轻量版本」等极具落地指向性的问题,表明已有大量开发者正在认真进行模型部署与测试。有开发者评价认为,这是「终于有人在原生统一方向上做出了扎实的工程落地」,与此前的伪统一架构有着本质区别。
与此同时,该模型采用 Apache 2.0 协议完全开源,支持商用。发布后不到两周,开发团队已相继推出了8步推理加速版、LoRA 微调版、GGUF 量化版以及低显存 layer-offload 推理模式。如此快速的迭代节奏,也是社区热度持续攀升的重要原因。
01 多模态的「两条腿走路」模式,已持续太久
多模态理解与生成,长期以来一直处于「各自为政」的状态。在多模态理解领域,以 GPT-4V、LLaVA、Qwen-VL 为代表的视觉语言模型(VLM),能够出色地完成图像描述、视觉问答和复杂推理任务;而在图像生成方面,则有 Stable Diffusion、FLUX、DALL-E 3 等扩散模型作为代表。这两条技术路线虽各有突破性进展,但由于长期独立演进,形成了截然不同的架构范式,这也是不争的事实。
变革的转折点出现在 2025 年,GPT-4o 所展现的统一多模态能力,引爆了业界对统一架构的追求——即用一个模型既能理解图像内容,又能生成高质量图像。不过,业界普遍推测,GPT-4o 的图像理解能力仍依赖独立的视觉编码器提取特征,而其自身并非原生地生成高质量图像,而是依赖集成的 DALL-E 3 模块完成。
实现路径之所以至关重要,是因为它直接决定了模型的多模态能力是否真正实现了统一。以 GPT-4o 为代表的混合架构,虽然在物理层面上共享了部分参数,但理解与生成在特征表示和计算路径上仍然相对独立。这种不同模块接力完成任务的路径,不可避免地导致了模型冗余、能力割裂以及交互障碍。
02 NEO-unify:真正依靠同一个大脑实现统一
真正「依靠同一个大脑」做到这一切,曾经只是许多研究者的设想,如今被商汤率先变为现实。SenseNova U1 系列模型基于商汤今年 3 月自主研发的 NEO-unify 架构,率先在单一模型架构上实现了多模态理解、推理与生成的统一,完成了从「模态集成」到「原生统一」的范式跨越。
NEO-unify 架构的核心突破在哪里?它彻底摒弃了传统的视觉编码器(VE)和变分自编码器(VAE),直接从像素和文本进行端到端学习。商汤在最新发布的技术文章中将其比喻为:传统架构就像「说不同语言的人组成的工作组」,而 SenseNova U1 更像「一个从一开始就同时掌握多项技能的人」。
这一设计的技术意义在于:VAE 的压缩过程本质上是有损的,开发者为此耗费了大量时间进行参数调优和补丁修正;而 NEO-unify 直接在像素层面建模语言与视觉信息,像素与词语的信息从一开始便处于同一个表征空间,共同参与每一层计算,从而消除了跨模块传递带来的信息损耗。
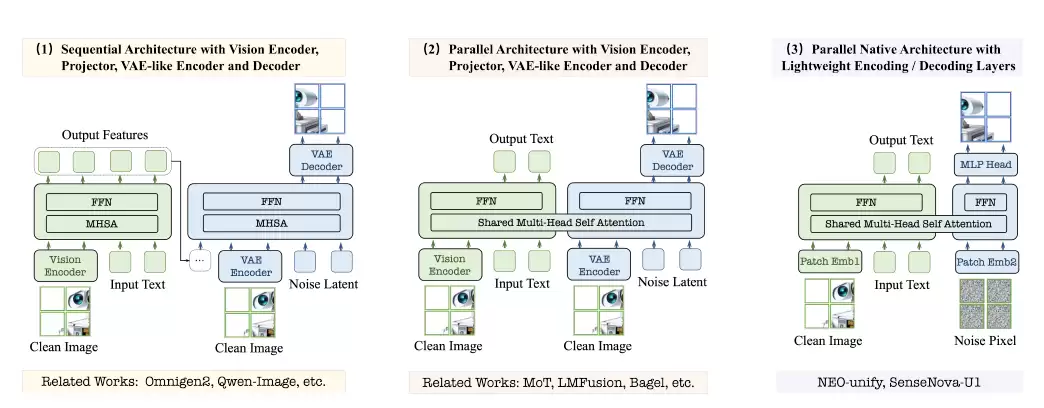
至此,我们才能说真正的端到端统一框架得到了实现。从单次图像生成的效果,到整个多模态模型的智能上限,都与这一里程碑的实现与否密切相关。
本次开源的 SenseNova U1 Lite 包含两种不同规格的模型:
- SenseNova-U1-8B-MoT(稠密骨干网络):理解与生成两条分支参数约为 9.37B / 8.19B
- SenseNova-U1-A3B-MoT(混合专家 MoE 骨干网络):理解分支约 30.54B,生成分支约 8.2B,每 token 激活 top-8 专家,实际活跃参数约 3B
03 模型测评:用数据说话
在商汤最新发布的 U1 技术报告中,一些数据表现格外突出。在涵盖图像理解、图像生成与编辑、空间智能和视觉推理的多项基准测试中,8B-MoT 均达到了同量级开源模型的 SOTA 水平,甚至在部分指标上超越了部分大型商业闭源模型。
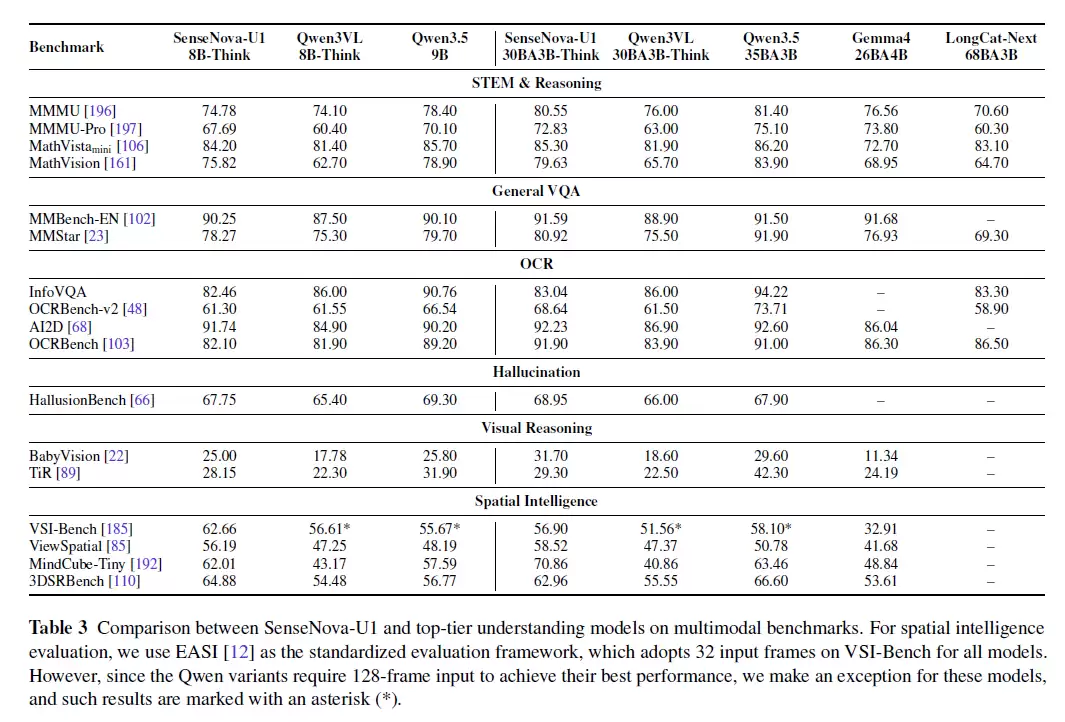
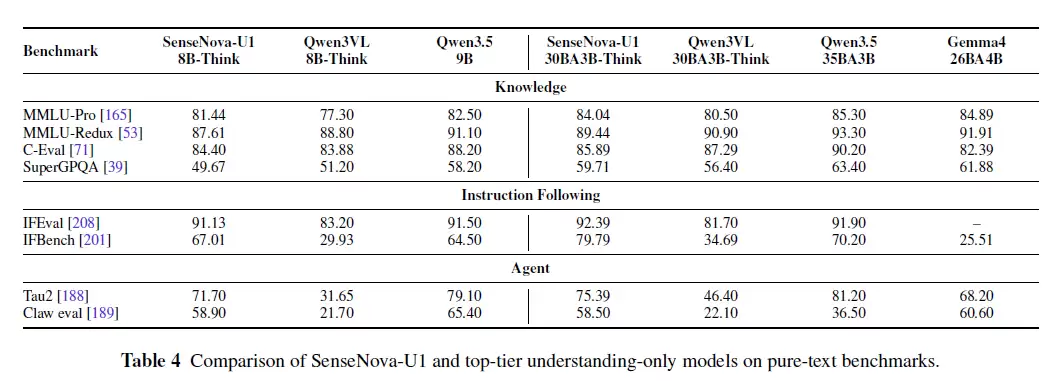
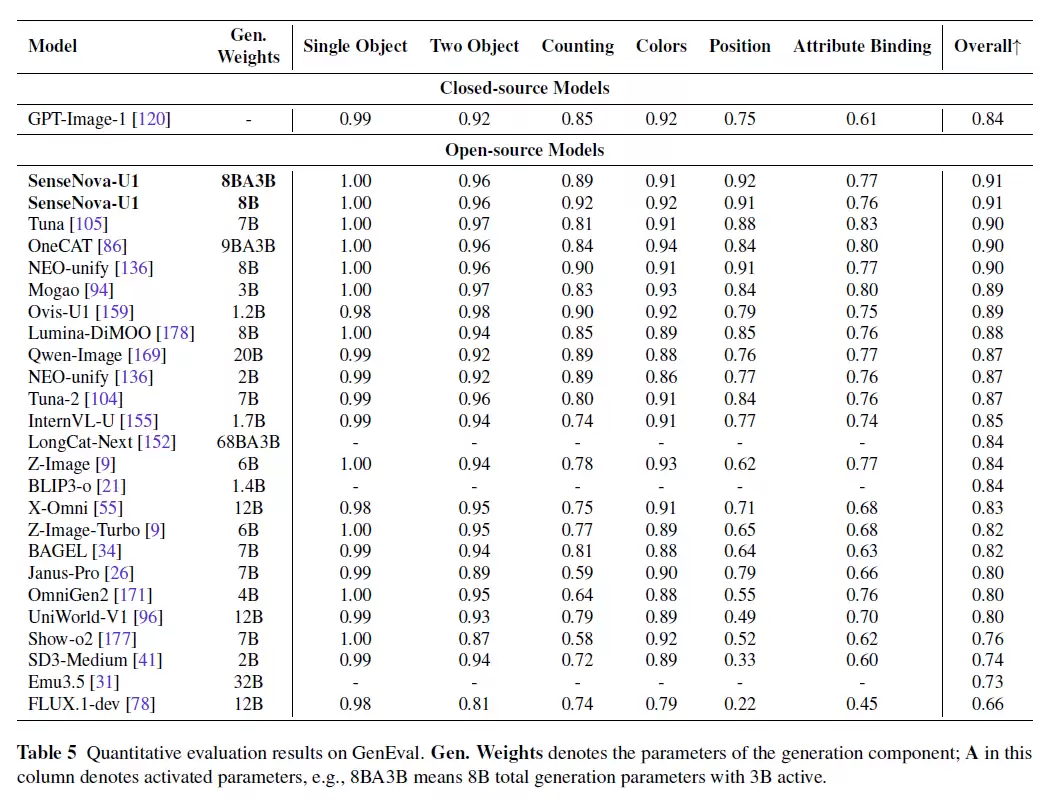
从上表可以看出,SenseNova U1 成功实现了理解、生成、编辑、交错和智能体能力的一体化融合,形成了相对均衡的能力谱系。在关键数据上,GenEval 总分约为 0.91-0.92,OneIG 中文文字渲染达到 0.977,信息图生成能力领先于多数开放模型,多模态理解 MMMU 得分达 80.55——这些优秀表现均源自同一个模型内部,而非多个专用模型的拼接。
技术报告中一个值得单独强调的结论是:统一架构具备更高的数据效率。NEO-unify 相较于类似的统一模型 BAGEL,在更少的训练 token 下取得了更出色的表现。原因在于原生像素-文本接口减少了跨模块对齐的成本,而 MoT 又使得两类能力能够共享上下文、互相提供监督信号,从而提升了训练数据的利用率。
在生成延迟与平均性能的综合对比中,SenseNova U1 Lite 在保证图像生成质量媲美 Qwen-Image 2.0 Pro、Seedream 4.5 等大型闭源模型的同时,推理响应速度也展现出显著优势,尤其在复杂信息图(Infographic)生成任务中,其控制力超出了预期。
更值得关注的是,作为当前最强的开源图像生成模型之一,SenseNova U1 Lite 的参数量仅为 8B。仅此一点,就意味着它在落地应用方面蕴藏着巨大潜力。
04 实测与部署方案
回到实际生产场景,SenseNova U1 在长文档与数据图表的总结分析、高质量信息图表生成等任务中,拥有广阔的应用空间。我们为此设计了一个有针对性的任务,来检验 SenseNova U1 在实际工作流中的表现。
首先,我们让 U1 绘制一幅云南水彩风景画,并采用连续图文创作输出的方式,展示从线稿到上色完稿的逐步过程。结果显示,SenseNova U1 能够很好地理解要求,进行符合逻辑的连贯输出,并保持画面信息的一致性。

同样是在生产场景中,图文交错生成以及「带图思考」背后的一致性,为 SenseNova U1 带来了更多可能性。在下面的用例中,我们请它为一座建筑群设计了 7 步分镜,覆盖了从二维底图到带有好莱坞级 CG 效果的人视街景。

信息图生成方面,我们先让 SenseNova U1 根据公开信息,制作了一份 5 月院线电影观影指南。

观影指南是一个关键信息高度密集的场景,每部电影的片名、日期、主题等标签都需要保证良好的可读性。在文字渲染准确性的挑战之上,这又对 SenseNova U1 处理多对象结构化排版的能力提出了更高要求。
此时,文字的清晰呈现已成为最基本的要求,更进一步的优秀表现是在高信息密度约束下,仍能保持杂志级的排版审美。平面设计师的排版能力与产品经理的信息架构能力的交叉点,恰恰是最容易暴露 AI 能力短板的地方。
为了进一步测试 SenseNova U1 的结构化叙事与设计能力,我们又让它制作了一份介绍《甄嬛传》中经典「滴血验亲」场景的信息图,并巧妙地将关键台词融入设计之中。

两份信息图都没有任何模板套用的痕迹,每一页都做到了根据内容密度自适应排版,信息图表和数据可视化都有相应的视觉呈现,字体、颜色、元素比例在视觉效果上也非常协调。
这两项任务的真正难点有两个。首先是异构素材的知识合并能力——公开信息来源涵盖了文本、图像等多种格式,要生成一份高质量的信息图,SenseNova U1 需要让重叠的知识点相互印证、合并,最终得到差异化的分层信息。没有真正的理解能力,就无法做到这一点。其次是逻辑感——尽管提示词非常简练,SenseNova U1 却能自主地对搜集的内容进行取舍,找到一条合理的叙述逻辑。这一点在总结「滴血验亲」剧情的用例中体现得尤为明显。
看惯了汉字在 AI 图片中被扭曲成麻花,SenseNova U1 在如此高密度的信息输出下,文字渲染准确率已经达到了落地级别。手工制作信息图甚至 PPT,或许很快将变成一项正在消失的技能。
05 ComfyUI 快速部署方案:5 分钟上手
在 SenseNova U1 的最近一次更新中,商汤正式上线了 ComfyUI 部署支持。开发者可以将 U1 作为自定义节点直接嵌入 ComfyUI 工作流,实现从「提示词构建→图像生成→结果预览」的全链路可视化操作。值得一提的是,U1 在 ComfyUI 中提供了「带图思考」的交错生成节点,使复杂逻辑的可视化推理过程一目了然。
环境要求
- Python ≥ 3.10,ComfyUI 最新版
- GPU:推荐 16GB 显存(8B-MoT 标准版)
- 低显存用户:8B-MoT-GGUF 版本可在 8GB 显存下运行;支持 layer-offload,进一步降低显存占用
安装步骤
# 1. 进入 ComfyUI 的 custom_nodes 目录
cd ComfyUI/custom_nodes
# 2. 克隆最新仓库
git clone https://github.com/OpenSenseNova/SenseNova-U1
# 3. 安装依赖(推荐 uv)
uv pip install -r requirements.txt
# 4. 配置 API Key(本地推理可跳过此步)
export SENSENOVA_API_KEY=your_key_here
# 5. 启动 ComfyUI,拖入 workflow_demo.json 即可运行
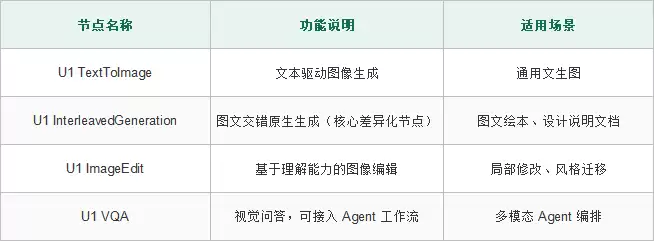
核心节点说明
加速与量化选项
- 8 步推理加速版(SenseNova-U1-8B-MoT-8step-preview):在大多数场景下生成质量接近基础模型,推理速度大幅提升
- LoRA 微调版(SenseNova-U1-8B-MoT-LoRA-8step-V1.0):支持风格定制与场景适配
- GGUF 量化版:由社区贡献者提供,权重已发布于 HuggingFace,适合消费级 GPU 本地推理
对于偏好免安装体验的用户,商汤还同步提供了办公小浣熊的体验渠道,无需 GPU,直接在浏览器中即可试用 U1 的核心功能。
06 生产级任务的新选择
过去一年,主流大模型厂商在多模态理解侧的表现已逐渐趋同,GPT-4V、Gemini Pro、Qwen-VL 等模型在图像理解、视频解析、文档理解等任务上的差距日益缩小。然而,生成侧始终是短板——理解一个数据集后,再生成信息图或制作一份 PPT,往往需要调用多个专用模型串联完成,这不仅导致延迟高、风格一致性差,而且交付质量也参差不齐。
SenseNova U1 的差异化优势正体现在这里。将 SenseNova U1 置于当前多模态的竞争格局中,几乎找不到与之完全相同的定位:
- GPT 系列多模态理解能力一流,但原生图像生成依然依赖独立模块,走的是专用模型协作的路线
- Qwen-VL 开源生态庞大,但生成能力以文本输出为主
- DeepSeek-V4 行业翘首以盼,但多模态生成并非其核心卖点
此前头部玩家的核心能力多集中在理解侧,而 SenseNova U1 率先实现了生成与理解的原生融合。在端到端交付已成为 Agent 落地共识的今天,只要理解与生成之间还存在跨模块的鸿沟,就会在落地层面表现为交付质量和生产效率的真实痛点。SenseNova U1 以一己之力,将这场围绕「交付」的竞争,提升到了底层架构创新的高度。
技术阶段的代差本身就意味着生产力的提升。SenseNova U1 针对企业办公场景进行了定向优化,将信息图、PPT、研究报告这类高频交付物作为重要战场,技术优势直接转化为落地能力。正因如此,SenseNova U1 才能在已经是一片红海的图像生成市场中占据一席之地,成为生产级任务的全新选择。
07 结语
NEO-unify 的核心创新,在于让语言和视觉在同一个表征空间里共同参与每一层计算。此后,模型在生成图像时,并非在「翻译」文字指令,而是在同一个思维框架之下,使语言与视觉信息作为一个统一的复合体被直接建模。
统一架构打破了理解与生成之间的信息壁垒,消除了模块边界本身带来的信息损耗。当理解和生成成为同一种认知能力的两面时,协同效应就不再是刻意设计的结果,而只是统一表征自然涌现的属性。这些革新共同支撑了应用层面的全新体验:统一架构首先意味着更强的复杂指令遵循能力,同时多轮交互中跨模态推理的可视化也增强了输出的可解释性,对于抽象推理过程尤其如此。
商汤还在技术报告中通过一系列消融实验,回答了一个核心问题:理解与生成的统一是否带来了真正的收益?
实验结论非常明确:统一架构在表示能力、训练稳定性和数据效率上确实有实质收益,而非一种折中方案。
- 原生像素-文本设计能同时保留语义和像素信息。实验验证了 encoder-free 架构不仅能够学到理解所需的语义表示,也能支持像素级重建与编辑。即使冻结理解分支,生成路径仍能恢复细节并完成较好的图像编辑——这说明理解端训练的内在表征并不只是「理解 token」,也具备生成所需的细粒度信息。
- MoT 让理解与生成协同工作,而非互相干扰。在联合 mid-training 和 SFT 阶段,即使生成数据和理解数据共同训练,理解能力仍能保持稳定,而生成能力收敛得更快。MoT 的参数解耦加上共享注意力上下文,能够有效降低理解与生成之间的内在冲突。
- 统一架构具备更高的数据效率。NEO-unify 相较于类似的统一模型 BAGEL,在更少的训练 token 下取得了更出色的表现。原因在于原生像素-文本接口减少了跨模块对齐成本,MoT 又让两类能力共享上下文、互相提供监督信号,从而提高了训练数据的利用率。
单个模型替代专用模型协作的传统范式,能够显著降低存储、计算和部署成本,但这还只是原生架构革命性的一角。
而更深层的意义在于,原生统一的多模态智能,仍然是一条被寄予厚望的 AGI 之路。多模态智能的未来突破,并不只是简单的规模扩大,更重要的是朝着深度融合方向发展的内核架构创新。今天,底层范式和模型架构的创新正变得越来越珍贵。开原生统一架构之先河的 SenseNova U1,或许会有与其历史地位相匹配的表现——而这,才刚刚开始。
- SenseNova U1 项目地址:https://github.com/OpenSenseNova/SenseNova-U1/
- SenseNova-Skills 项目地址:https://github.com/OpenSenseNova/SenseNova-Skills




