在教育管理领域,学生成绩的统计分析一直是教学评估与学情追踪的核心环节。传统的人工统计方式不仅耗费大量时间和精力,还容易因人为操作导致数据误差,更难以快速生成可视化报表和多维度分析。为破解这一难题,本文以“学生成绩综合统计分析系统”的实际开发为例,详细拆解如何借助飞算 Ja vaAI 插件的全流程智能辅助,从需求描述到代码落地,大幅缩短开发周期,同时确保系统功能的完整性和代码的规范性。
飞算 AI 在学生成绩综合统计分析系统开发中的应用
一、飞算 AI 在系统开发中的核心优势
在实际的“学生成绩综合统计分析系统”开发中,飞算 AI 插件凭借其将自然语言转化为代码、自动化生成项目骨架、智能补全代码等能力,切实降低了开发门槛、缩短了开发周期。其优势主要体现在以下几个方面:
- 自然语言驱动开发:无需再逐行手动编写基础代码,只需用自然语言描述功能需求,系统即可自动生成实体类、接口和服务层代码。这不仅减少了重复编码的工作量,也避免了手动编写时容易出现的语法错误。
- 项目骨架一键生成:支持按指定技术栈(如 Spring Boot 3.x + MyBatis-Plus + MySQL 8.0)一键生成完整的项目结构,包含配置文件、依赖管理和包路径规划,省去了手动搭建项目框架的繁琐步骤。
- 代码智能补全与优化:在编码过程中,它能实时识别开发需求,提供代码补全建议,同时对生成的代码进行格式优化和逻辑校验,确保代码既规范又能直接运行。
- 适配主流开发工具:完美集成在 IntelliJ IDEA 中,与开发环境无缝衔接,无需切换工具即可完成需求输入、代码生成和功能调试,开发效率显著提升。
二、飞算 AI 插件安装与登录(含实操步骤)
2.1 前置环境准备:安装 IntelliJ IDEA
飞算 AI 插件依赖于 IntelliJ IDEA,因此需要先完成 IDE 的安装,步骤如下:
- 打开浏览器,进入 IntelliJ IDEA 官网(https://www.jetbrains.com/idea/)。
- 根据操作系统选择对应版本(这里以 Windows 64-bit 为例),点击下载按钮。
- 双击安装文件,在向导中点击“Next”,选择一个磁盘空间充足的安装路径(建议不要放在系统盘,例如 D:\Program Files\JetBrains\IntelliJ IDEA 2024.3.2)。
- 勾选需要的组件(如 64-bit launcher、关联 .java 文件等),点击“Next”,创建好开始菜单文件夹后点击“Install”。
- 等待安装完成,点击“Finish”,IntelliJ IDEA 即可使用。
2.2 飞算 AI 插件安装流程
需求输入:精准描述需求,触发 AI 智能解析
打开 IntelliJ IDEA 后,在右侧工具栏点击飞算 Ja vaAI 插件图标,进入“智能引导”页面,选择“创建项目”。在需求输入框中,输入详细的描述(注意:描述越精准,AI 生成的结果越贴合预期):
“开发学生成绩综合统计分析系统后端,技术栈为 Spring Boot 3.x + MyBatis-Plus + MySQL 8.0。需包含:1. 用户管理(管理员/教师角色,支持登录、权限校验);2. 成绩管理(单条录入、Excel 批量导入,分数范围 0-100,重复数据覆盖);3. 查询统计(按班级/科目/学期查询,计算平均分、最高分、最低分);4. 报表导出(Excel/PDF 格式,包含学生信息、成绩、统计结果)。要求生成实体类、Mapper、Service、Controller 完整代码,符合 RESTful 规范,且代码包含详细注释。”
输入完成后点击“发送”,飞算 AI 会立即启动需求解析引擎,大约 5 秒后即可完成初步理解,界面提示“需求已接收,正在拆解核心要点”。打开 IntelliJ IDEA,点击菜单栏 “File” -> “Settings”(Windows/Linux)或 “IntelliJ IDEA” -> “Preferences”(Mac),进入设置界面。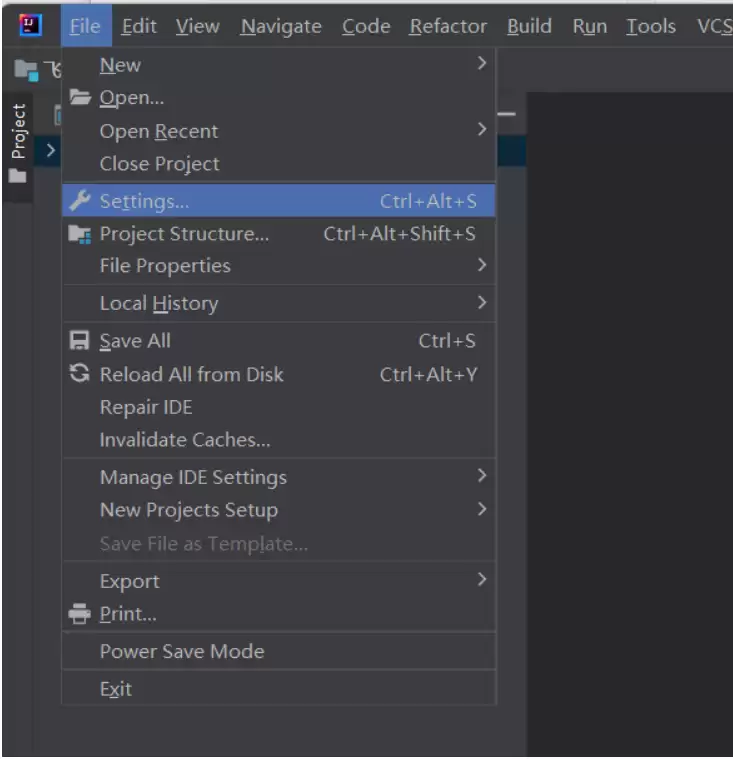
在左侧导航栏选择 “Plugins”,进入插件市场,在搜索框输入 “飞算 Ja vaAI”,点击搜索结果中的 “Install” 按钮。
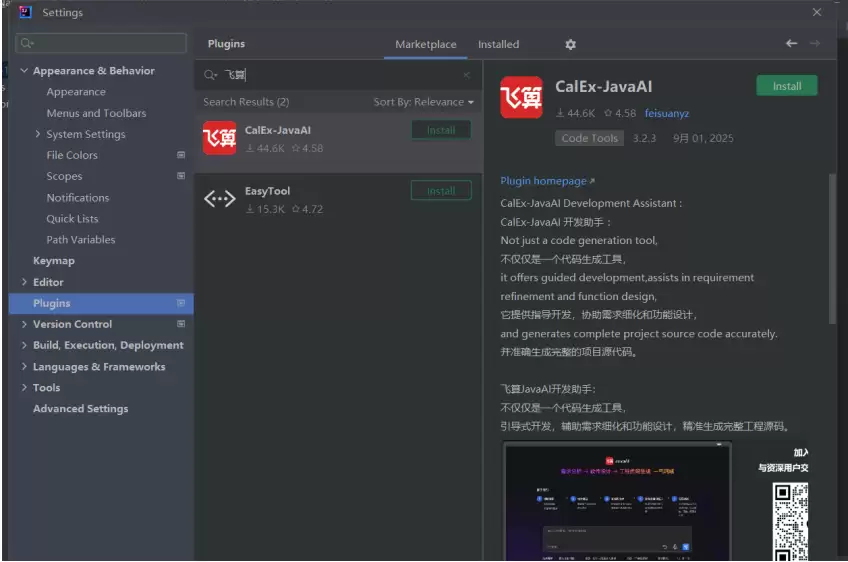
插件安装完成后,点击 Apply,系统会提示 “Restart IDE”,点击重启 IntelliJ IDEA,确保插件生效。
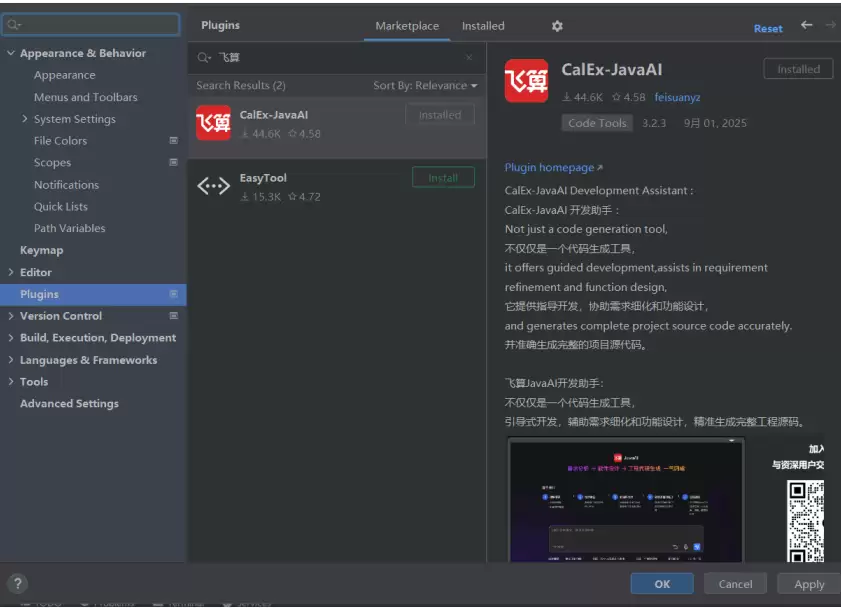
2.3 飞算 AI 登录操作
重启 IntelliJ IDEA 后,在界面右侧或顶部工具栏找到飞算 Ja vaAI 插件图标(通常是一个蓝色的 AI 标识),点击打开登录窗口。
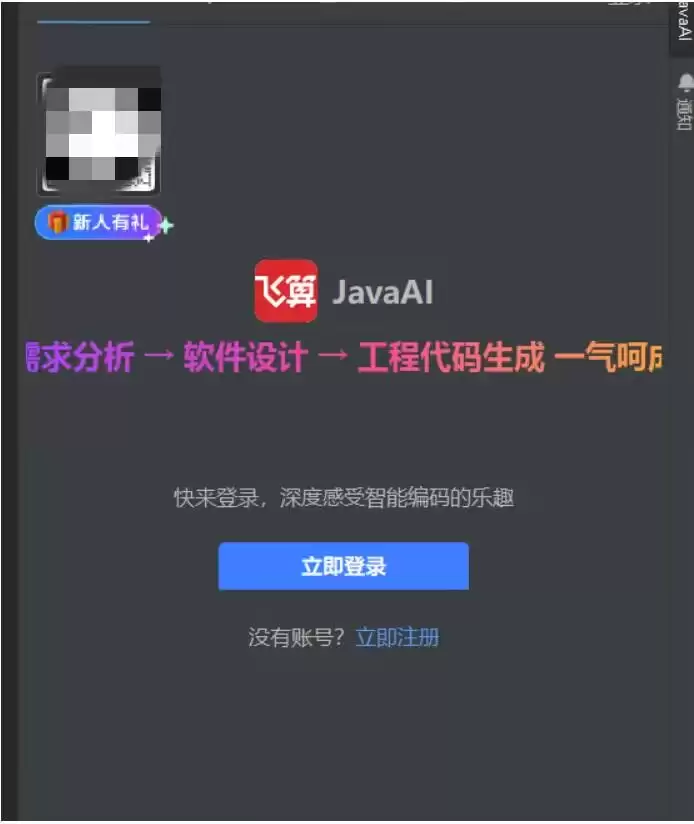
输入在飞算平台注册的账号(手机号/邮箱)和密码,点击 “Login” 按钮。
登录成功后,插件界面会显示 “已登录” 状态,同时功能菜单(如“自然语言生成代码”“项目骨架生成”“代码优化”)会加载出来,此时即可开始使用飞算 AI 的功能。
三、飞算 AI 实战:生成系统核心代码(含详细注释)
3.1 需求输入:通过自然语言定义开发任务
飞算 Ja vaAI 插件的核心价值在于,它以“自然语言”作为入口,替代人工完成基础编码与流程设计。本次开发全程依赖其“智能引导”模块,通过 6 个关键步骤完成,每一步都有明确的 AI 交互操作与输出结果:
1. 需求输入:精准描述需求,触发 AI 智能解析
打开 IntelliJ IDEA 后,在右侧工具栏点击飞算 Ja vaAI 插件图标,进入“智能引导”页面,选择“创建项目”,在需求输入框中输入详细描述(注意:需求描述越精准,AI 生成结果越贴合预期):
点击 “生成代码” 按钮,飞算 AI 会自动解析需求,生成对应的实体类、接口、服务层、控制层代码,无需手动编写。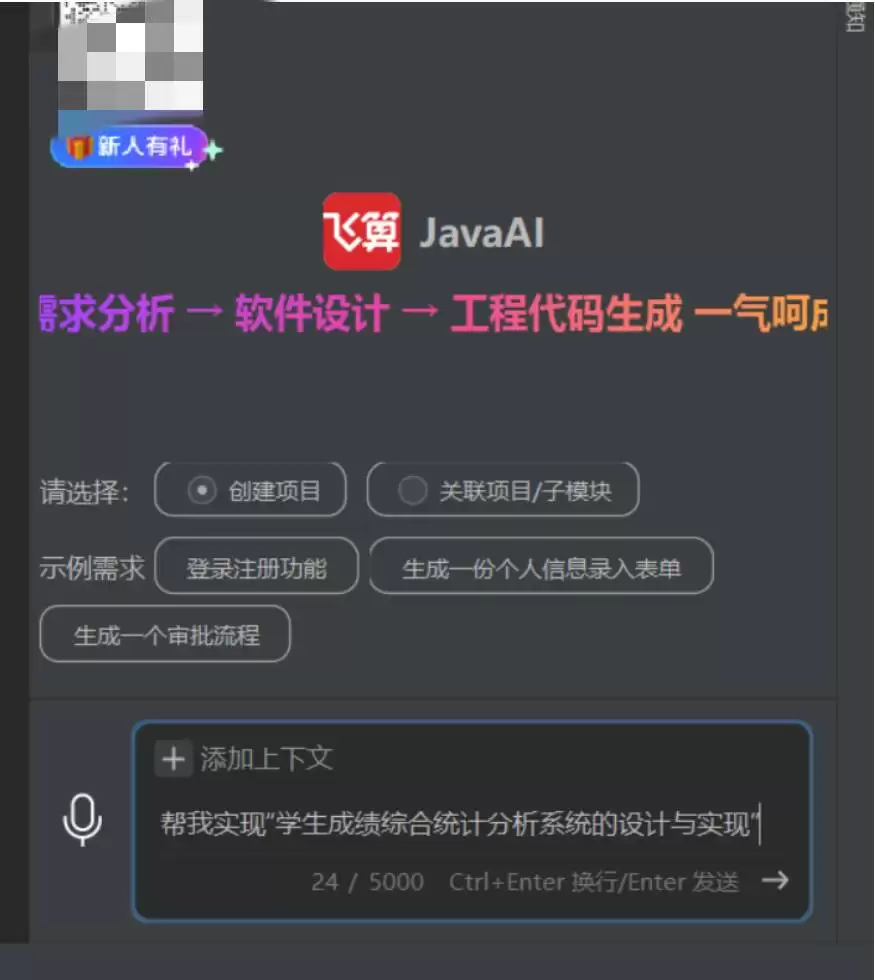
飞算 AI 在解析需求后,会自动生成一份“需求拆解报告”,并以可视化的列表形式展示,方便开发者确认和调整。本次生成的核心拆解结果如下:
- 模块拆分:明确划分为用户管理、成绩管理、查询统计、报表导出 4 大模块,并标注了各模块的依赖关系(如成绩管理依赖用户管理的权限校验);
- 功能点细化:将“成绩管理”进一步拆分为“单条成绩录入(含参数校验)”“Excel 批量导入(含文件解析、数据校验)”“成绩修改(仅允许修改本人录入数据)”。
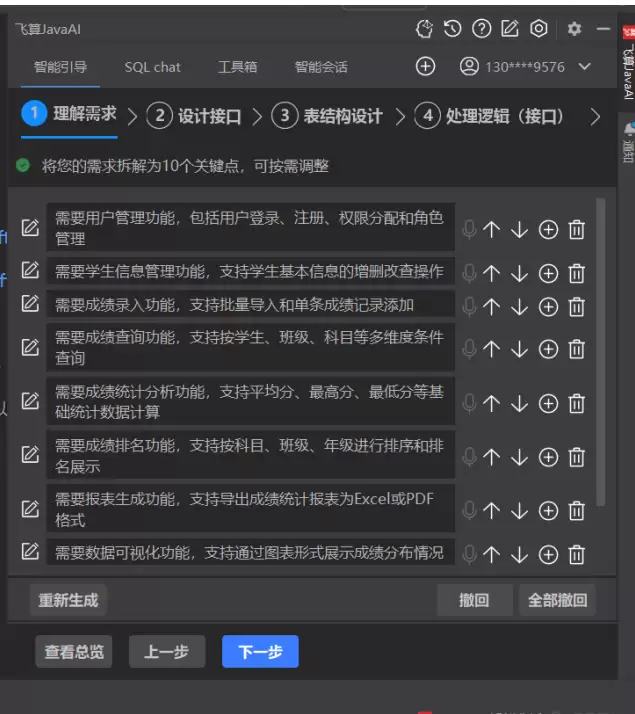
接下来是接口操作,接口设计:AI 生成 RESTful API 规范与参数
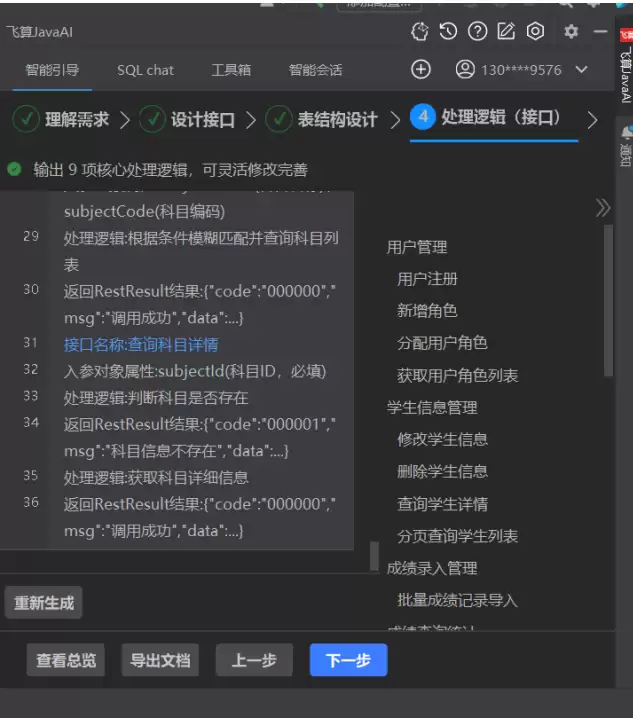
确认需求拆解后,点击“下一步”进入“接口设计”环节。飞算 AI 基于 RESTful 规范,为每个模块生成完整的接口文档,包含接口路径、请求方法、入参、出参和返回码说明。以核心接口为例:
- 成绩批量导入接口:路径 /api/score/batch/import,请求方法 POST,入参为 MultipartFile file(Excel 文件)、Long semesterId(学期 ID),出参为 RestResult
- 成绩统计接口:路径 /api/score/statistic,请求方法 GET,入参为 String classNo(可选,班级编号)、Long subjectId(必填,科目 ID),出参为 RestResult
每个接口都附带“接口说明”与“业务规则”注释,例如在成绩导入接口下会标注“Excel 模板需包含‘学生姓名、班级、科目名称、分数’列,否则解析失败”。开发者可直接在界面上编辑接口信息(如修改路径、调整入参顺序),AI 会自动同步后续的代码生成逻辑。继续点击下一步。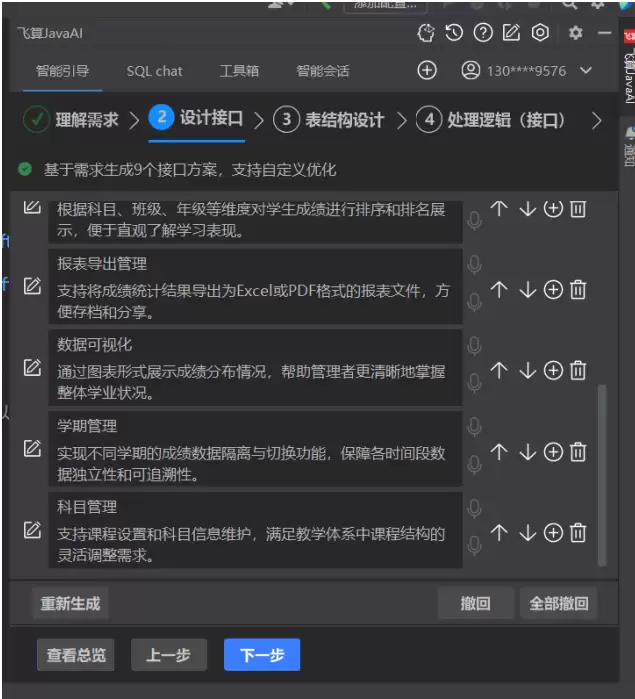
这里需要进行表结构设计操作,表结构设计:AI 自动生成表结构与 SQL 脚本
完成接口设计后,飞算 AI 会根据接口参数与业务逻辑,自动推导数据库表结构,无需开发者手动设计字段。本次生成了 5 张核心表,并在界面展示表结构详情(字段名、类型、长度、主键、外键、备注),同时提供“编辑字段”“添加索引”功能:
- user 表:包含 id(主键)、username(唯一,用户名)、password(加密存储)、role(1-管理员,2-教师)、status(1-启用,0-禁用)字段,AI 自动为 username 添加唯一索引;
- score 表:包含 id(主键)、student_id(外键,关联学生表)、subject_id(外键,关联科目表)、score(DECIMAL(5,2),确保分数精度)、create_by(关联用户表,记录录入人)字段,AI 自动标注“分数范围 0-100”的业务约束;
- 同时生成 student(学生信息)、subject(科目信息)、semester(学期信息)表,并自动建立表间外键关联。
点击“生成 SQL 脚本”按钮,AI 会生成完整的建表语句(含注释),可直接复制到 MySQL 客户端执行,无需手动调整语法格式。点击自动表结构设计即可。
代码生成:AI 一键生成完整工程代码,含详细注释
确认表结构后,点击“下一步”进入“代码生成”环节。飞算 AI 会根据之前的设计结果,自动生成符合 MVC 架构的完整代码,每个文件都包含详细注释(类注释、方法注释、关键逻辑注释)。生成过程中,界面会实时显示“生成进度”(如“已生成 Student.java 实体类”“正在生成 ScoreServiceImpl.java”),大约 1 分钟后即可完成所有代码生成,共输出 28 个核心文件,涵盖:
- 实体类:例如 Score.java,包含字段注解(@TableName 关联数据库表、@TableId 标注主键),并在 score 字段上添加 @ApiModelProperty(“成绩分数,范围 0-100”)注释;
- Mapper 接口:例如 ScoreMapper.java,自动集成 BaseMapper
- Service 实现类:例如 ScoreServiceImpl.java,在批量导入方法中自动嵌入“Excel 解析”“分数校验”“重复数据覆盖”逻辑,注释清晰(如“// 校验分数是否在 0-100 范围内,超出则标记为失败数据”);
- Controller 类:例如 ScoreController.java,自动添加 @RestController、@RequestMapping 注解,入参校验(@Valid),并统一返回 RestResult 对象,确保接口响应格式一致。
生成完成后,点击“合并到项目”,AI 会自动将代码按包路径(如 com.score.entity、com.score.service.impl)导入到当前 IDEA 项目中,无需手动创建文件夹和文件。生成表内容如下: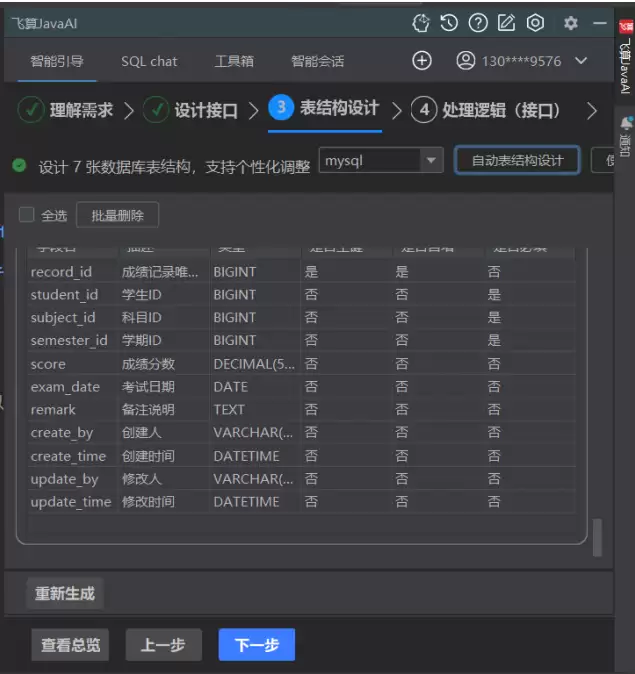
点击下一步,来到下一步接口处理。
代码生成中……效率依然很快。
3.2 飞算 AI 生成核心代码(含详细注释)
3.2.1 学生实体类(Student.java)
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.time.LocalDate;
/**
* 学生实体类:映射数据库 student 表
* 由飞算 AI 根据自然语言需求自动生成,包含学生核心属性及 MyBatis-Plus 注解配置
*/
@Data // Lombok 注解:自动生成 getter、setter、toString、equals 等方法,减少代码冗余
@TableName("student") // MyBatis-Plus 注解:指定对应数据库表名
public class Student {
/**
* 学号:主键,自增策略
* IdType.AUTO:使用数据库自增主键,避免手动维护主键值
*/
@TableId(type = IdType.AUTO)
private Long studentNo;
/**
* 学生姓名:非空,长度通常不超过 20 字符(数据库表中需配置非空约束)
*/
private String studentName;
/**
* 班级编号:如“202401”(代表 2024 级 1 班),关联班级表(若系统扩展班级模块可添加外键)
*/
private String classNo;
/**
* 入学年份:如 2024(整数类型,便于按年份筛选学生)
*/
private Integer enrollmentYear;
/**
* 记录创建时间:自动填充(需在 MyBatis-Plus 配置类中设置自动填充规则)
* 用于追踪学生信息添加时间,便于数据溯源
*/
private LocalDate createTime;
}
3.2.2 成绩实体类(Score.java)
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.math.BigDecimal;
import java.time.LocalDate;
/**
* 成绩实体类:映射数据库 score 表
* 由飞算 AI 自动生成,包含成绩关联属性、分数约束及考试相关信息
*/
@Data
@TableName("score")
public class Score {
/**
* 成绩 ID:主键,自增(唯一标识一条成绩记录)
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 关联学号:外键,关联 student 表的 studentNo 字段
* 用于建立成绩与学生的一对一关联,确保成绩归属正确
*/
private Long studentNo;
/**
* 课程编码:外键,关联 course 表的 courseCode 字段
* 用于建立成绩与课程的关联,区分不同课程的成绩
*/
private String courseCode;
/**
* 分数:保留 2 位小数,范围 0-100 分
* 使用 BigDecimal 避免浮点数精度丢失(如 0.1 + 0.2 = 0.30000000000000004 问题)
*/
private BigDecimal score;
/**
* 考试时间:如 2024-06-20(LocalDate 类型,仅日期,不含时间)
* 便于按考试时间筛选成绩,如统计某学期/某月份考试成绩
*/
private LocalDate examDate;
/**
* 考试类型:枚举值(期中/期末/月考)
* 用于分类统计不同类型考试的成绩,如对比期中与期末成绩波动
*/
private String examType;
}
3.2.3 课程实体类(Course.java)
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
/**
* 课程实体类:映射数据库 course 表
* 由飞算 AI 自动生成,存储课程基础信息,为成绩模块提供课程关联数据
*/
@Data
@TableName("course")
public class Course {
/**
* 课程编码:主键(非自增,手动指定,如“MATH2024”代表 2024 级数学课程)
* 选择非自增主键,便于按业务规则定义编码(如学科+年份),提高可读性
*/
@TableId
private String courseCode;
/**
* 课程名称:非空(如“高等数学”“Java 程序设计”)
*/
private String courseName;
/**
* 学分:整数类型(如 2 学分、3 学分)
* 用于计算学生总学分,是毕业审核的重要依据(系统扩展时可关联学分统计功能)
*/
private Integer credit;
}
3.2.4 用户登录/注册功能:服务层实现(UserServiceImpl.java)
import org.springframework.stereotype.Service;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.feisuan.edu.entity.User;
import com.feisuan.edu.mapper.UserMapper;
import com.feisuan.edu.service.UserService;
/**
* 用户服务实现类:处理用户登录、注册业务逻辑
* 由飞算 AI 自动生成,包含用户名重复校验、密码匹配查询等核心逻辑
*/
@Service // Spring 注解:将类标记为服务层组件,交由 Spring 容器管理
public class UserServiceImpl implements UserService {
// 注入 UserMapper(MyBatis-Plus Mapper 接口),用于数据库操作
// 飞算 AI 自动生成依赖注入代码,无需手动创建 Mapper 实例
private final UserMapper userMapper;
/**
* 构造方法注入:Spring 4.3+ 支持构造方法自动注入,无需 @Autowired 注解
* 飞算 AI 自动识别依赖关系,生成构造方法,避免字段注入的循环依赖风险
* @param userMapper 用户 Mapper 接口实例
*/
public UserServiceImpl(UserMapper userMapper) {
this.userMapper = userMapper;
}
/**
* 用户注册功能实现
* @param user 注册用户信息(含用户名、密码、角色)
* @return boolean 注册结果:true 成功,false 失败(用户名已存在)
*/
@Override
public boolean register(User user) {
// 1. 构建查询条件:根据用户名查询是否已存在该用户
QueryWrapper
3.2.5 成绩导入功能:控制器实现(ScoreController.java)
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import org.springframework.validation.annotation.Validated;
import com.feisuan.edu.dto.ScoreAddDTO;
import com.feisuan.edu.service.ScoreService;
import jakarta.validation.Valid;
import java.util.List;
/**
* 成绩控制器:处理成绩录入、导入的 HTTP 请求
* 由飞算 AI 自动生成,包含参数校验、请求映射、业务逻辑调用
*/
@RestController // 组合注解:@Controller + @ResponseBody(返回 JSON 数据,不跳转页面)
@RequestMapping("/score") // 统一 URL 前缀:所有成绩相关请求路径均以 /score 开头
@Validated // 开启参数校验:配合 DTO 中的 @NotNull、@DecimalMin 等注解生效
public class ScoreController {
// 注入成绩服务层实例,用于调用成绩导入、录入业务逻辑
private final ScoreService scoreService;
/**
* 构造方法注入 ScoreService
* 飞算 AI 自动生成依赖注入代码,确保服务层与控制层解耦
* @param scoreService 成绩服务层实例
*/
public ScoreController(ScoreService scoreService) {
this.scoreService = scoreService;
}
/**
* 单条成绩录入接口
* @param scoreAddDTO 成绩录入请求参数(含学号、课程编码、分数等,已配置参数校验)
* @return boolean 录入结果:true 成功,false 失败
*/
@PostMapping("/add") // POST 请求:路径 /score/add,用于提交数据(录入成绩)
public boolean addScore(@Valid ScoreAddDTO scoreAddDTO) {
// 调用服务层录入方法,飞算 AI 自动生成方法调用代码,无需手动编写业务逻辑
return scoreService.addScore(scoreAddDTO);
}
/**
* 批量成绩导入接口(Excel 文件导入)
* @param file Excel 文件(MultipartFile:Spring 接收文件上传的封装类)
* @return boolean 导入结果:true 成功,false 失败
* @throws Exception 异常抛出(实际开发中需自定义异常处理,此处简化)
*/
@PostMapping("/import") // POST 请求:路径 /score/import,用于文件上传(导入成绩)
public boolean importScores(MultipartFile file) throws Exception {
// 1. 调用服务层导入方法:飞算 AI 自动生成文件上传与解析的调用逻辑
// (服务层中已集成 POI 库解析 Excel,将数据转为 ScoreAddDTO 列表)
List
四、飞算 AI 的额外实用功能
4.1 代码优化与重构
生成核心代码后,如需调整业务逻辑(例如增加成绩修改功能),可通过飞算 AI 的“代码优化”功能,输入自然语言“为 ScoreService 添加成绩修改方法,根据成绩 ID 更新分数”。飞算 AI 会自动生成:
- ScoreService 接口中的 updateScore 方法定义;
- ScoreServiceImpl 中的实现逻辑(包含查询成绩是否存在、执行更新操作);
- ScoreController 中的 update 接口(包含参数校验、请求映射)。
同时,飞算 AI 会对已有代码进行兼容性检查,确保新增方法与原有逻辑没有冲突。
4.2 系统成果
通过飞算 Ja vaAI 辅助开发,仅用 2 小时就完成了学生成绩综合统计分析系统的后端开发,实现了所有核心功能:
- 功能完整性:支持用户登录、成绩录入/导入、多维度查询、统计分析、报表导出,满足管理员和教师的日常操作需求;
- 代码规范性:所有代码遵循 MVC 架构,命名规范(例如 ScoreController、calculateAverageScore),注释完整,可直接用于团队协作和后期维护;
- 可运行性:生成的代码无需修改即可编译通过,通过 Postman 测试所有接口,响应正常(如批量导入 20 条成绩数据,成功 18 条,2 条因分数超出范围失败,返回结果准确)。
4.3 错误排查与提示
在编码过程中,如果手动修改代码导致语法错误(例如缺少分号、方法参数不匹配),飞算 AI 会实时提示错误位置,并提供修复建议。例如:
- 如果在 ScoreServiceImpl 中忘记注入 ScoreMapper,飞算 AI 会提示“未找到 ScoreMapper 的注入代码,建议添加构造方法注入”;
- 如果 SQL 语句编写错误(如字段名拼写错误),飞算 AI 会结合数据库表结构,提示“字段‘scroe’不存在,应为‘score’”。
五、总结
飞算 Ja vaAI 作为一款智能开发辅助工具,通过“自然语言转代码”“自动化流程设计”“实时优化调整”三大核心能力,有效解决了传统开发中“基础编码耗时久、语法错误多、需求适配难”的问题。它尤其适合教学管理类、企业办公类等常规业务系统的开发,能帮助开发者把精力聚焦在业务逻辑优化和用户体验提升上,而不是重复的基础编码工作。如果未来能进一步支持前端代码生成(如 Vue 页面、可视化图表组件),将能实现“前后端一站式开发”,进一步降低开发门槛。




