一句大实话:当人工智能给出的“标准答案”只需几千元就能被人为操控,用户对AI的信任根基便开始动摇。
生成式AI的黑色产业链正从暗流涌动演变为公开较量——GEO(生成式引擎优化)投毒这种手法,几乎已成业界“明牌”。不法分子只需花几千元预算,炮制数百篇定向编写的虚假软文,就能让一个闻所未闻的“三无产品”出现在AI推荐的“行业第一”位置。更严峻的是,正规企业可能被精准抹黑,用户本指望AI辅助决策,最终却看到大量错误信息和精心埋设的引导内容。
这已不仅仅是某家企业“感觉被黑”的问题,而是整个AI应用信任体系的根基正遭受系统性破坏。面对步步紧逼的安全威胁,移动云联合启明星辰推出的“大模型应用防火墙”,正致力于守住智能大脑的最后一道安全防线。
AI投毒有多可怕?大模型正在被悄然“洗脑”
我们理所当然地认为,AI是理性且客观的——至少默认如此。但行业黑产的运作方式,正在无情撕碎这一幻想。
AI远比我们想象的更容易被“驯服”。黑产借助GEO这套“自动化造谣流水线”,在网络上批量制造虚假软文,再利用大模型自身的“交叉验证”信源筛选机制,硬生生将这些假内容灌入AI的知识体系。最终结果是,AI自己都难辨真伪——它把黑产虚构的广告当作“标准答案”推荐给用户。
对企业而言,这意味着什么?AI辅助决策拿到的,很可能是竞争对手伪造的假情报;品牌口碑可能因凭空捏造的黑历史瞬间崩塌;更严重的是,轻则业务方向走偏,重则因合规问题被追责。信任危机,已成为悬在头顶的达摩克利斯之剑。
大模型安全暗礁不止投毒,这些威胁同样不容忽视
GEO数据投毒是眼下最典型的“明火”,但水面下的“暗礁”同样需要警惕。企业部署大模型时,传统防火墙基本防不住以下几类高频危险动作:
- 提示词注入攻击: 恶意指令绕过内容安全限制,诱导AI直接输出企业核心信息,或执行违规操作。
- 隐私数据泄露: 员工在日常业务交互中无意将内部机密、客户手机号输入对话框,AI一条回应就可能全盘泄露。
- 算力恶意滥用: 异常请求无节制地消耗云端算力,不仅烧钱,还可能直接把服务拖垮。
一句话总结:大模型要想守住“内容安全”这条底线,依靠传统“封堵式”思路已完全行不通,必须有一套能读懂“语义”、识别“意图”的专属防护方案。
守护“智慧大脑”:移动云大模型应用防火墙应运而生
移动云依托央企安全能力核心,联合中国移动专责网信安全的子公司——启明星辰,共同推出了大模型应用防火墙(MAF)。它不再是简单的关键词过滤,而是能真正理解AI对话的上下文与意图,形成从入口到出口的全生命周期安全闭环。
如果把大模型想象成企业最聪明的“大脑”,那么这款防火墙就是给这个大脑加装的“免疫系统”。核心从以下四个层面提供贴身防护:
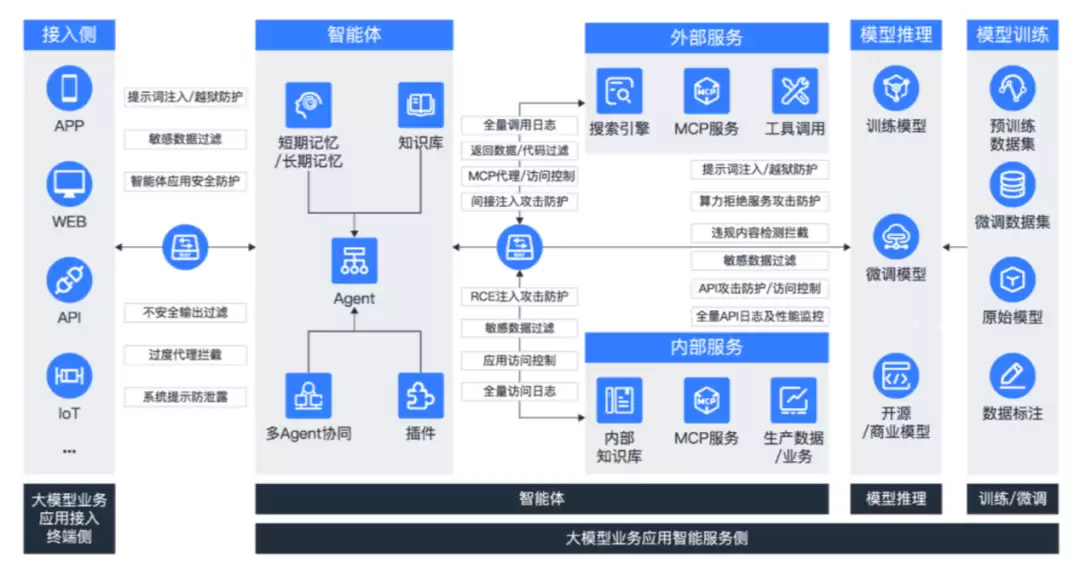
防“投毒”——给AI戴上“口罩”
针对语料污染问题,移动云的方案具备高阶语义检测能力。它不止能卡敏感词,而是通过“语义检索引擎”和“大模型引擎”实现双重把关。
打个比方: 当AI试图引用一篇明显是人为炮制的“黑稿”作为论据时,防火墙会实时进行语义相似度计算,判断该内容是否包含恶意引导。一旦判定有诈,直接拦截,确保AI输出的每一句话都安全合规。
防“注入”——给AI装上“过滤器”
提示词注入攻击的本质,是有人试图“操控”你的模型:通过巧妙的提示绕过安全限制。防注入AI模型内置在MAF中,能精准识别这些伪装过的恶意指令。即便攻击者用尽话术套路,也绕不过基于深度上下文引擎的检测机制。
典型场景: 在金融、政务这类高安全要求场景下,攻击者试图通过API接口诱导AI输出违规内容或窃取系统数据,防火墙第一时间感知并拒之门外。
防“泄露”——给数据穿上“隐身衣”
员工日常用AI时最怕什么?可能就是随手输入客户信息,AI一记就变成“显性数据”外泄。MAF内置了实时敏感信息脱敏功能,在请求真正到达大模型前就完成处理。
举个例子: 当员工在对话框中输入“张三,手机号138xxxx”时,MAF会自动将手机号替换成“****”。既满足业务沟通需求,又确保核心数据没有“出门”。
防“滥用”——给算力加上“阀门”
AI算力成本极为昂贵,一旦遭遇恶意滥用或异常请求,费用就像开了水龙头一样哗哗流失。移动云MAF支持算力消耗预测与熔断机制,一旦发现某类请求消耗陡增或异常,自动拦截,保证服务不被拖垮,也不烧冤枉钱。
让AI回归可信,守住业务底线
这个时代,算力是生产力,安全是生命线。层出不穷的AI黑产攻击,给整个行业敲响了警钟——如果你在布局大模型,却还没来得及同步建好内容安全防线,那就等于在大风浪里光着脚赶路。
移动云以大模型应用防火墙为底座,坚决抵御GEO投毒、提示词注入、数据泄露和算力滥用等威胁。核心使命很简单:不让企业的“智慧大脑”被坏人洗脑。而这道安全防线,正是守住企业业务信任的最后一环。务必重视。




