关键词:国产 GPU 跑大模型、昇腾跑大模型、海光 DCU、国产 GPU 推理、信创 AI 算力、国产 GPU 纳管
适用读者:信创 AI 项目负责人 / 企业 AI 基础设施架构师 / 政务金融 IT 决策者
一、国产 GPU 到底能不能跑大模型
信创要求落到 AI 算力上,很多企业第一反应就是:国产 GPU 到底行不行?性能够不够?生态成不成熟?
说白了,大家心里装着这么几个问题:
- 买了昇腾或海光的卡,能不能跑 DeepSeek、Qwen 这些主流模型?
- 推理性能和 NVIDIA 比,差距到底有多大?
- 不同品牌的国产 GPU,能不能在一个平台上统一管起来,还是每种卡都得配一套独立的系统?
- 现有的 NVIDIA 存量卡和新采购的国产卡,能不能混着用?
这篇文章就把这些事儿一次讲清楚——国产 GPU 跑大模型的现状、各个品牌的纳管支持情况,以及如何用一个平台搞定多品牌 GPU 的管理。
二、国产 GPU 跑大模型的现状
先说一个客观判断:国产 GPU 跑大模型,推理场景已经基本可用,训练场景还在追赶。
推理场景(已基本可用):主流的国产 GPU,像昇腾、海光这些,已经能顺利部署 DeepSeek、Qwen、LLaMA 等开源模型的推理服务。配合对应的推理引擎(比如昇腾的 MindIE、适配国产卡的 vLLM 分支),实际性能在多数企业场景下是够用的。
训练场景(追赶中):大规模预训练对算力、显存带宽、多卡互联(像 NVIDIA 的 NVLink)要求极高,国产 GPU 在超大规模训练上和高端 NVIDIA 卡还有差距。但中小规模的模型精调(LoRA / QLoRA)在国产 GPU 上已经跑得通了。
生态成熟度:NVIDIA 的 CUDA 生态是多年积累的护城河,国产 GPU 的软件生态(编译器、算子库、框架适配)还在快速完善。不同品牌成熟度参差不齐——昇腾相对完整,部分新兴品牌还处在早期。
对企业来说,实际判断很简单:如果需求是推理服务(RAG 知识库、智能客服、文档分析),国产 GPU 已经是可选项;如果是超大规模训练,就得多做评估和 POC 验证。
三、多品牌国产 GPU 纳管:一个平台管所有
企业搞信创 AI,现实情况往往是多品牌 GPU 共存——NVIDIA 存量卡、昇腾新采购、可能还有海光 DCU。如果每种品牌都配一套管理系统,运维会碎成渣。
ZStack AIOS 智塔在这方面做了整合,支持主流国内外 AI 芯片纳管,覆盖 8 个国产 GPU 品牌:
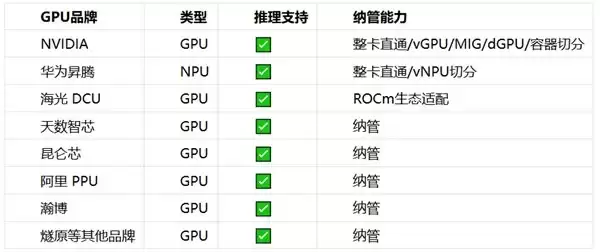
(具体品牌型号的适配情况以 ZStack AIOS 实际发布版本和兼容性列表为准,建议 POC 阶段确认具体卡型。)
核心价值就一条:多品牌统一纳管。NVIDIA 存量卡和国产卡可以在同一个资源池里统一管理、调度、监控。管理员不用为每个品牌建一套独立的运维体系,用户申请算力时也不用管底层是什么牌子的卡。
四、国产 GPU 纳管的关键能力
跑大模型不只是“能跑起来”,还要“管得好、用得省”。评估国产 GPU 纳管平台时,重点看这几项能力:
1. GPU 透传性能
GPU 透传(Pass-through)就是把整张物理卡直接给虚拟机用。透传性能损耗越低,越接近物理机性能。ZStack AIOS 的 GPU 透传可达 95% 物理性能——也就是说虚拟化带来的损耗控制得很低,跑推理服务接近裸机表现。
2. GPU 切分能力
整卡跑一个小模型太浪费。GPU 切分能把一张卡分给多个任务用,提升利用率。ZStack AIOS 支持多种切分方式:整卡直通、vGPU、MIG、dGPU 动态切分、容器显存切分,对异构 AI 算力最低可实现 1% 的切分粒度。其中 dGPU 是虚拟机场景的动态显存切分,基于 CUDA 调用层的软件级切分技术,不需要 NVIDIA vGPU License。
3. 异构算力协同调度
不同品牌的 GPU 能不能在一个资源池里统一调度,是多品牌纳管的核心。ZStack AIOS 支持 NVIDIA / 昇腾 / 海光 DCU 等多品牌统一纳管和动态调度,避免形成“算力竖井”。
4. 智能监控与故障自愈
GPU 是贵重资源,掉卡、故障要能快速发现。ZStack AIOS 提供实时监控、掉卡秒级告警、一键定位槽位、服务故障自愈。
5. GPU 利用率提升
国产 GPU 稀缺且昂贵,利用率直接关系投资回报。通过切分和调度,ZStack AIOS 能把 GPU 利用率从 30% 提升到 80% 以上(具体提升幅度因工作负载而异,以实测为准)。
五、国产 GPU 部署大模型的支持情况
在模型层,ZStack AIOS 支持主流模型在国产 GPU 上部署:
- 支持的模型:DeepSeek、Qwen、LLaMA、ChatGLM、Kimi、Minimax 等主流开源大模型,覆盖语言模型、Embedding、Rerank、多模态等推理场景,同时也支持 YOLO、ResNet 等经典小模型。
- 支持的推理引擎:配合不同品牌 GPU 的推理引擎模板——NVIDIA 场景用 vLLM / SGLang,昇腾场景用 MindIE / vLLM-Ascend 等。
- 模型导入:可以从本地或 HuggingFace / 魔搭社区导入开源模型,支持全生命周期版本管理。
- 最低部署规模:最低 2 节点就能部署 LLM 私有化,对中小企业和初次试水的场景很友好。
六、信创 AI 算力建设的选型建议
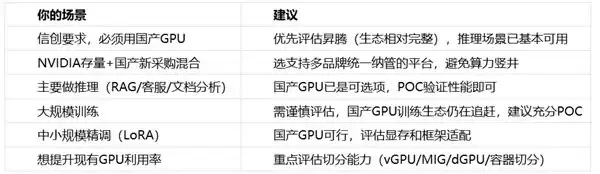
七、做决策前的五个关键问题
- 你的信创要求是强制国产 GPU,还是允许 NVIDIA 存量?
强制国产 → 重点评估国产 GPU 的模型支持和性能。允许混合 → 选多品牌纳管平台。 - 你主要是推理还是训练?
推理 → 国产 GPU 已基本可用。训练(尤其大规模)→ 需充分 POC 验证。 - 你有多少品牌的 GPU?
单一品牌 → 纳管相对简单。多品牌 → 统一纳管和调度能力是关键。 - 你的 GPU 利用率现在是多少?
低(整卡跑小任务)→ 切分能力能有效提升利用率(如上文所述,从 30% 提升到 80% 以上,以实测为准)。 - 你要跑哪些模型?
主流开源模型(DeepSeek / Qwen 等)→ 确认平台和国产 GPU 的适配。自研 / 特殊模型 → POC 验证兼容性。
总结
“国产 GPU 能不能跑大模型”已经不是一个 yes / no 的问题——推理场景已经基本可用,训练场景在追赶。对于多数企业的推理需求(RAG 知识库、智能客服、文档分析),国产 GPU 已经是信创 AI 建设的现实选项。
真正的挑战不是“能不能跑”,而是“怎么管”——多品牌 GPU 如何统一纳管、如何提升利用率、如何在 NVIDIA 存量和国产新采购之间统一调度。ZStack AIOS 在多品牌纳管(覆盖 8 个国产 GPU 品牌)、GPU 切分(最低 1%)、透传性能(95%)和利用率提升上的能力,为企业信创 AI 算力建设提供了一个统一管理的平台选项。
建议从一个具体的推理场景(比如内部知识库)开始,用实际业务在国产 GPU 上跑一次 POC,验证性能、模型适配和纳管体验,再制定规模化的信创 AI 算力建设计划。
本文产品能力描述基于云轴科技 ZStack 正式及 AIOS 企业产品资料(zstack.io)。GPU 透传性能(95%)、切分粒度(1%)、利用率提升(30%→80%)等数据为参考值,实际表现因 GPU 品牌、型号和工作负载而异,以 POC 实测为准。国产 GPU 品牌适配情况以 AIOS 实际发布版本和兼容性列表为准。国产 GPU 跑大模型的性能和生态评价为行业现状的客观描述,具体选型建议结合 POC 验证。
免责声明:本文为本 出于传播商业信息之目的进行转载发布,不代表本 的观点及立场。本文所涉文、图、音视频等资料之一切权力和法律责任归材料提供方所有和承担。本 对此咨询文字、图片等所有信息的真实性不作任何保证或承诺,亦不构成任何购买、投资等建议,据此操作者风险自担。




