在正式启动A股上市辅导后,这家港交所上市公司的上海AI团队MiniMax,于昨天(6月1日)再度放出重磅消息——全新一代通用大模型MiniMax M3正式登场。那么,M3究竟解决了哪些实际痛点?当前的大模型在读取超长文档、处理复杂代码时,往往存在越往后越遗忘、计算成本高且速度慢的问题。M3正是瞄准这些核心短板而来。作为国内首个将前沿编程能力、1M超长上下文、原生多模态三大能力“打包”于一体的AI大模型,这一技术突破引发业内热议:M3是否直接对标美国Anthropic公司今年4月发布的Claude Opus 4.7?后者以极致指令遵循、高清视觉、深度推理和专业代码著称。客观来看,M3目前未必全面超越Opus 4.7,但它的竞争策略截然不同——开源路线叠加超高性价比。

从实测数据来看,开源的M3在综合能力上已非常逼近Claude Opus 4.7。例如,在专门衡量编程能力的SWE-Bench Pro评测基准中,MiniMax M3直接超越了OpenAI的GPT-5.5与谷歌的Gemini 3.1 Pro,距离Opus 4.7仅一步之遥。另一个值得关注的亮点是M3的“原生多模态”特性。许多大模型训练到后期才硬性加入图像、视频理解能力,而M3从训练初始阶段就将文本、图像、视频等多种模态混合训练。这好比在双语环境中成长的孩子,语言驾驭能力天然更胜一筹。
技术底牌:自研稀疏注意力架构MSA
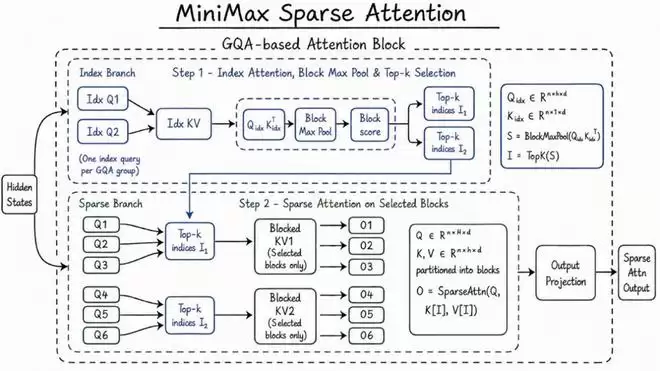
全球大模型竞争已进入白热化阶段,各家若想保持领先优势,关键在于当Agent(智能体)的任务复杂度不断升级时,模型如何实现更长的上下文、更稳定的记忆,同时大幅降低推理成本。M3的底气源于MiniMax自主研发的稀疏注意力架构MSA(MiniMax Sparse Attention)。相比传统的全注意力机制,MSA在长上下文场景下显著降低了计算开销,并将上下文窗口直接拉升到100万token——相当于两本中文长篇小说的体量。这意味着,在长文档分析、复杂代码仓库解析、多轮任务协作等场景中,M3能够保留更完整的信息链路,不会读到后面就忘了前文的重点。更关键的是,MiniMax一贯的性价比优势依旧突出:M3的单token计算量仅为上一代模型的大约二十分之一。干的活差不多,计算量却差了一个数量级。
值得一提的是这家公司的研发节奏:去年6月刚发布M1,第四季度便密集推出M2和M2.1,今年2月又放出M2.5,如今M3已正式亮相。AI行业的终极竞争拼的是智能进化的速度,从这一节奏来看,上海这家人工智能企业的研发效率确实无可挑剔。




