TensorFlow Lite Micro多输入输出支持实现教程
随着边缘AI技术的广泛应用,将复杂的神经网络模型部署到资源受限的嵌入式设备已成为常态。一个关键的技术挑战随之浮现:如何在极其有限的内存资源下,高效处理多路输入数据并生成多路输出结果?这正是多模态识别、多任务学习等前沿AI应用的核心需求。
然而,当前的开发实践却面临一个明显的瓶颈。包括NXP eIQ在内的许多主流MCU SDK中,TensorFlow Lite Micro的典型应用默认仅支持“单输入单输出”模型。这种局限性不仅严重制约了开发者的模型选型,更在面对需要融合图像与传感器数据、或同时输出分类与定位信息的复杂场景时,显得捉襟见肘。
因此,本系列文章旨在系统性地解决这一问题。我们将从架构设计到代码落地,手把手为TensorFlow Lite Micro构建一套完善、易用且高效的多输入多输出支持框架。
为何必须支持多输入多输出?
你或许会质疑,单输入单输出模型在简单分类任务中不是已经足够了吗?确实如此。但当我们着眼于更实际、更复杂的边缘AI应用场景时,单一数据流的假设便不再成立:
1. 多模态融合模型
例如,结合摄像头图像与IMU惯性数据来精准识别物体姿态,或融合麦克风音频与视觉信息进行情绪状态分析。这类模型天然依赖多个异构数据源作为输入。
2. 检测与识别复杂模型
以YOLO目标检测模型为例,它需要同步输出类别概率、边界框坐标及置信度。现代人脸识别模型也常需一并输出人脸特征向量和五官关键点坐标。这些都是典型的多输出应用。
3. 多任务学习模型
设计一个模型同时完成图像分类与目标定位(回归),或构建能联合进行语音识别与情感分析的统一网络。这类高效设计旨在共享特征、提升效率,其输入与输出必然是多元的。
问题的核心在于,如果底层的推理框架代码只能访问模型的第一个输入张量,或仅能读取第一个输出张量,那么模型其余精心设计的结构便完全失效,变得毫无用武之地。
回顾常见SDK中典型的“单输入”实现代码:
uint8_t* MODEL_GetInputTensorData(tensor_dims_t* dims, tensor_type_t* type){
TfLiteTensor* inputTensor = s_interpreter->input(0); // 仅支持第一个输入
return GetTensorData(inputTensor, dims, type);
}显然,此类接口已无法满足现代边缘AI模型的复杂需求。接下来,我们将以此为契机,开始设计一套全新的、支持多输入多输出的软件架构。
一. 架构设计思路
我们的目标是为TFLM注入完整的多输入多输出能力,同时确保现有项目能够无缝迁移,避免大规模重构。为此,我们确立了四大核心设计原则:
向后兼容:确保所有原有的单输入单输出接口功能完好,不破坏任何现有代码。
类型安全:通过强类型检查机制,杜绝运行时因数据类型不匹配导致的程序崩溃。
轻量高效:最大限度减少额外的内存消耗与计算开销,契合嵌入式环境的严苛要求。
易于使用:提供简洁、直观的API接口,显著降低开发者的学习与集成成本。
二. 系统整体架构
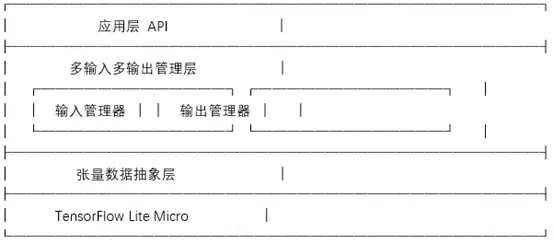
上图清晰地展示了系统的整体架构。这套设计方案主要致力于攻克三个核心难题:
统一管理所有输入输出张量:系统化地组织并管理模型的所有输入和输出张量,而非仅处理第一个。
抽象张量元数据:将张量的维度信息、数据类型、内存地址指针等关键信息进行封装与抽象,提供统一的访问入口。
提供友好的上层API:向应用层暴露一组清晰、易用的函数接口,方便开发者高效地获取和填充数据。
三. 关键数据结构设计
为了有效管理多个张量的信息,我们需要设计几个核心的数据结构。它们将成为“输入管理器”与“输出管理器”的功能基石。
(1)张量维度结构体
typedef struct {
int size; // 维度数量
int data[MAX_TENSOR_DIMS]; // 各维度具体大小
} tensor_dims_t;(2)张量数据类型枚举
typedef enum {
kTensorType_FLOAT32,
kTensorType_UINT8,
kTensorType_INT8
} tensor_type_t;(3)多张量信息结构体(核心)
typedef struct {
int count; // 张量总数
tensor_dims_t dims[MAX_INPUT_TENSORS]; // 维度信息数组
tensor_type_t types[MAX_INPUT_TENSORS]; // 数据类型数组
uint8_t* data[MAX_INPUT_TENSORS]; // 数据指针数组
} multi_tensor_info_t;这个multi_tensor_info_t结构体是整个多张量支持方案的核心,它高效打包了所有相关张量的关键元信息与数据指针。
四. API接口设计(预览)
基于上述数据结构,我们可以规划出一套供应用层调用的核心API接口。
(1)基础信息查询
// 获取输入/输出张量的总数
int MODEL_GetInputTensorCount(void);
int MODEL_GetOutputTensorCount(void);(2)单张量访问接口
// 按索引获取特定张量的数据指针及其元信息(维度、类型)
uint8_t* MODEL_GetInputTensorData(int index, tensor_dims_t* dims, tensor_type_t* type);
uint8_t* MODEL_GetOutputTensorData(int index, tensor_dims_t* dims, tensor_type_t* type);(3)批量获取所有张量信息
// 一次性获取所有输入或输出张量的完整信息包,便于批量操作
status_t MODEL_GetAllInputTensors(multi_tensor_info_t* input_info);
status_t MODEL_GetAllOutputTensors(multi_tensor_info_t* output_info);(4)支持差异化预处理
// 支持根据张量索引执行不同的数据预处理(如量化、归一化、格式转换)
void MODEL_ConvertInput(uint8_t* data, tensor_dims_t* dims, tensor_type_t type, int tensor_index);此接口极具实用价值,它允许开发者针对模型的不同输入(例如,图像输入需要归一化,而传感器数据输入需要量化),采用完全独立的预处理流水线。
五. 结语与下期预告
本文从深入剖析边缘AI对多输入多输出的迫切需求出发,逐步构建了一套支持该功能的完整软件架构。我们明确了关键的设计原则,规划了清晰的系统结构,设计了核心的数据类型,并预览了主要的API接口。
通过实施这套方案,我们能够在确保百分百向后兼容的前提下,让TensorFlow Lite Micro轻松驾驭更复杂的AI模型。这将极大拓展边缘AI的应用边界,减少为适配复杂模型而产生的重复开发工作,并显著提升整个项目的工程化效率与可维护性。
在接下来的第二篇文章中,我们将正式进入代码实现阶段。内容将涵盖完整的头文件设计、类型与接口的具体声明,以及张量管理、数据访问等核心功能模块的具体实现。敬请期待。
相关攻略

针对TensorFlowLiteMicro仅支持单输入单输出的限制,本文设计了一套支持多输入多输出的轻量高效软件架构。该架构通过统一管理张量、抽象元数据并提供简洁API,在确保向后兼容与类型安全的同时,使嵌入式设备能够高效部署和运行多模态融合、检测及多任务学习等先进边缘AI模型。

TensorFlow无法调用GPU通常由CUDA版本不匹配导致。需按顺序确保显卡驱动、CUDA、cuDNN与TensorFlow版本严格对应。具体步骤包括:检查并更新驱动,安装指定版本的CUDAToolkit并配置环境变量,部署对应cuDNN库文件,创建独立Python环境安装TensorFlow。最后通过代码验证GPU是否被成功识别,完成深度学习环境搭建。

SkillsVote研究提出AI智能体技能生命周期管理方案:从开源平台收集技能,经评估筛选构建高质量技能库。任务执行前通过侦察机制推荐相关技能,执行后进行归因分析提取可复用经验。经验经聚合与路由决策后受控更新技能库。实验表明,该方法能显著提升AI在终端与编程任务上的表现,核心在于通过。

Tensor art是什么? Tensor art是一个集成了AI模型社区与在线生成功能的免费图像创作平台。其核心优势在于“完全免费”和“在线操作”——用户无需下载任何软件或配置本地硬件,打开浏览器即可直接使用海量模型生成高质量图像。 平台架构主要包含两大核心模块:首先,它是一个活跃的AI模型共享社

在AI艺术创作领域,各类工具与平台不断涌现,但能够同时实现技术先进性与创作灵活性的选择却不多。今天我们将深入探讨的Tensor Art,正是一个在专业创作者社群中日益受到重视的AI艺术生成平台。该平台本质上是一个融合了前沿机器学习技术与计算机视觉算法的数字创作工坊,用户只需输入创意描述文本或上传参考
热门专题







热门推荐

为什么不能满仓操作?仓位管理是风险控制的第一道防线 在加密市场的惊涛骇浪中,一个核心原则被反复验证:满仓操作,无异于将自己置于毫无退路的悬崖边缘。它背后潜藏着五大风险:市场不确定性下的单点暴露、心理压力导致决策失衡、错失动态再平衡机会、杠杆叠加加剧爆仓、链上痕迹削弱抗审查能力。理解这些风险,是构建稳

对于成长型企业而言,部署AI的最大挑战往往不在于技术本身,而在于算力成本宛如一笔糊涂账——每月支出多少、流向何处、下月预算如何规划,几乎全凭估算。联想最新推出的百应AI 3 0版本,正是精准回应了这一难题。 本次,联想首次为成长型企业打造了一套覆盖全链路的词元经济解决方案,其核心理念极为简洁:将算力

上周,金山办公在武汉举办了WPS AI NEXT线下路演,现场发布的新一代WPS多维表格,凭借一份硬核成绩单引发行业关注。在权威表格智能体评测榜单SpreadSheetBench最新排名中,WPS多维表格的AI智能引擎位列全球第二,仅次于谷歌,充分展现了国产办公软件的AI实力。 当前,多维表格赛道竞

宗门联赛S3赛季引入三线对抗机制,增加排兵布阵博弈;新增战术设计可禁用特定秘术,强化情报收集。同时加入挂机功能降低参与门槛,匹配机制优化提升公平性,位面加速缩短比赛耗时,满足不同玩家需求。

车队运营团队普遍面临两个核心痛点:工具碎片化、手动流程耗时严重。在近期举办的Vision 26峰会上,Motive一口气发布了集成硬件与人工智能的多项创新方案,矛头直指这两个痼疾,将其物理AI运营平台的边界大幅外扩。从本质上看,这套新方案要解决的是一个老问题:如何把散落在不同系统里的数据整合到一个统