AutoMoT双SOTA:B2D与nuScenes上VLM端到端驾驶新思考
大模型为自动驾驶带来的最直接价值是什么?毫无疑问,在于场景理解能力的跃升。它能精准识别前车是否准备变道,预判行人横穿马路的潜在可能,分析施工区域对正常车道的侵蚀,甚至在复杂路口厘清车辆通行的优先顺序。
然而,仅具备“看”的能力是远远不够的。车辆真正的挑战,是在下一个瞬间做出具体操作——是减速滑行还是保持当前时速,是继续跟随前车还是寻找机会绕行。因此,核心问题随之而来:大模型所具备的深层场景认知,究竟该如何高效地赋能驾驶决策与轨迹规划?

引言
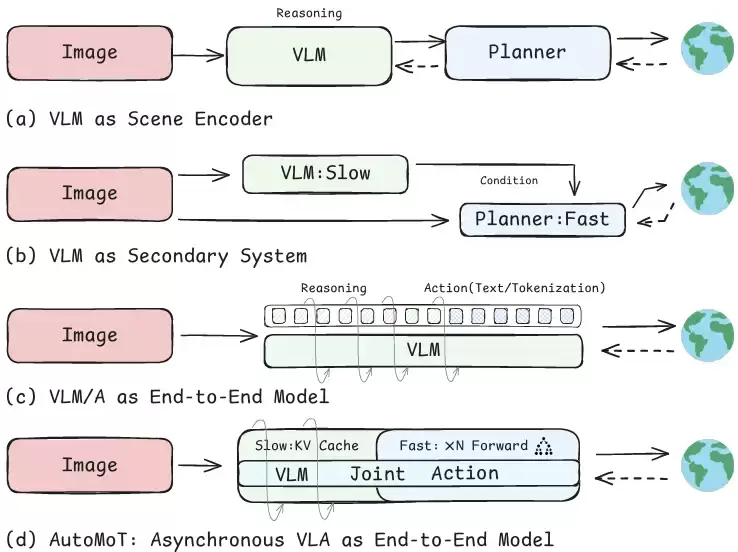
近年来,这一领域的主流技术路线大致可归纳为三类。第一类是将视觉语言模型(VLM)作为场景编码器置于前端,先完成图像理解,再将理解结果传递给后端的规划模块。分工虽然明确,但场景理解和轨迹规划仍是两个彼此割裂的步骤。第二类是将 VLM 作为辅助模块,输出风险判断或驾驶意图等条件信号,真正的实时控制仍由传统规划器完成。这种方案对原有系统的改动较小,但往往浪费了大模型的深度推理能力——复杂的思考过程最终被压缩成几个提示词,很难完整转化为实际动作。
还有一种更为直接的方法,就是将推理与动作整合进同一个视觉-语言-动作(VLA)模型中。理解与动作虽被统一,但实时性问题随之凸显:高层推理可以容忍较慢的速度,而轨迹规划却必须追求极快的响应。如果两者始终同步执行,大模型的推理延迟便会成为系统反应速度的核心瓶颈。
针对这些挑战,来自南洋理工大学 AutoMan Lab、哈佛大学和小米汽车的研究团队提出了 AutoMoT——一个面向端到端自动驾驶的统一视觉-语言-动作模型。该模型将场景理解、轨迹规划和动作决策映射至同一潜在空间,并借助异步推理机制实现“低频理解、高频行动”。具体而言,理解模块负责高层语义建模,动作模块负责决策与轨迹规划,两者通过逐层共享注意力(layer-wise shared attention)在模型内部直接交互。
实验结果表明,AutoMoT 在 Bench2Drive 和 nuScenes 两大基准测试中均取得了业界领先(SOTA)的性能。在 Bench2Drive 闭环评测中,AutoMoT 达到了 87.34 DS / 70.00% SR,加入 Action Refiner 后的 AutoMoT+ 进一步提升至 89.42 DS / 74.09% SR;在 nuScenes 开环规划评测中,其平均碰撞率仅为 0.07%,平均 L2 误差为 0.32。该研究成果已被国际顶级会议 ICML 2026 正式接收。

- 论文标题:AutoMoT: A Unified Vision-Language-Action Model with Asynchronous Mixture-of-Transformers for End-to-End Autonomous Driving
- 论文链接:https://arxiv.org/abs/2603.14851
- 项目主页:https://automot-website.github.io/
- 代码链接:https://github.com/OscarHuangWind/AutoMoT
- 模型链接:https://huggingface.co/Oscar-Huang/AutoMoT
- 数据链接:https://huggingface.co/datasets/Oscar-Huang/nuSync
模型架构
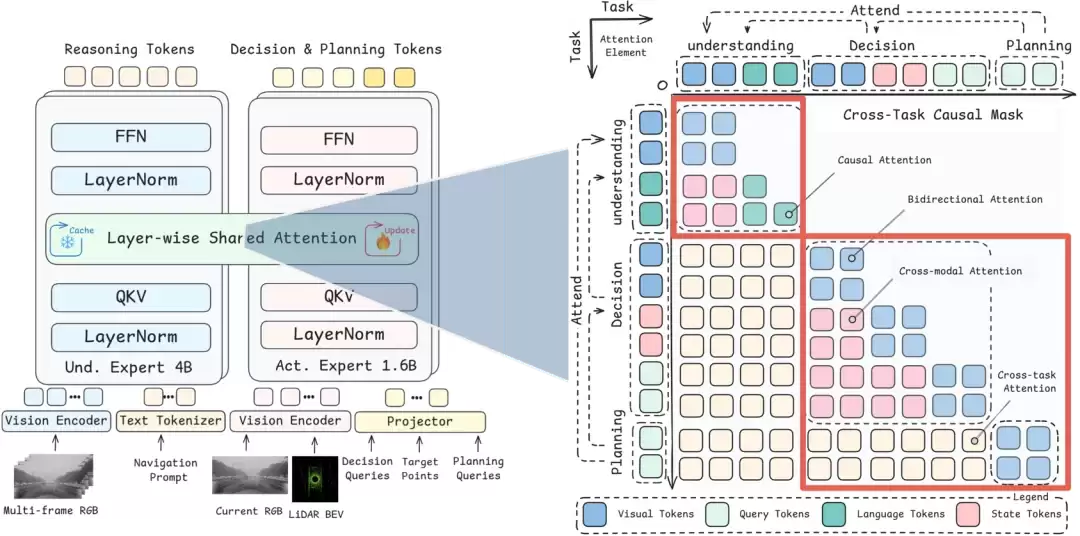
理解、决策与规划的统一
AutoMoT 由两个核心专家模块构成:理解专家(UE)和动作专家(AE)。
如上图左侧所示,UE 是一个拥有 4B 参数的 Qwen3-VL 基座模型,其输入为多帧 RGB 图像与导航提示,输出为推理 token;AE 则是约 1.6B 参数的动作专家,输入包含当前帧的 RGB 图像、激光雷达鸟瞰图(LiDAR BEV)、决策查询、目标点以及规划查询,输出决策与规划 token。
关键在于,UE 与 AE 之间并非传统的层级串联关系。AutoMoT 在每一层引入了逐层共享注意力机制:UE 提供高层场景理解,而 AE 在生成动作时可直接访问这些中间表示。这意味着,UE 的场景理解不再仅仅是输出一段外部文本解释,而是深度参与到动作的生成过程中。
上图右侧展示了 AutoMoT 创新的注意力机制设计。理解(Understanding)、决策(Decision)与规划(Planning)三类任务通过跨任务因果掩码(cross-task causal mask)建立了清晰的信息流:决策模块可以读取理解模块的场景信息,规划模块则能同时读取理解与决策模块的信息;而在各任务内部,则保持双向注意力。如此一来,动作专家并非从零开始学习规划,而是在基座模型已有知识的基础上,学习如何做出决策并生成轨迹。轨迹预测不再是简单的几何曲线拟合,而是由场景语义和驾驶意图共同驱动的结果。
异步推理,通过 KV Cache 复用场景理解
AutoMoT 的异步推理设计,核心目标是解决闭环驾驶场景下的实时性难题。动作规划需要高频刷新,因为自车状态和周围交通参与者的状态瞬息万变;而高层场景理解则具有一定的时间连续性——例如前方的施工区域、慢速行驶的车辆或复杂路口的拓扑关系,不会在几个控制周期内发生根本性改变。
因此,AutoMoT 让 UE 周期性更新高层理解,而 AE 则以更高频率生成具体动作。UE 每次完成理解后,会保存对应的键值缓存(KV cache),AE 在后续多个动作步中可以直接基于这些缓存的状态进行多步决策和轨迹规划,无需每一步都重新执行完整的模型推理。
这一设计理念值得关注:AutoMoT 并没有削弱大模型推理的作用,而是重新定义了它参与控制的方式。高层理解依然深刻影响着动作生成,但不再阻塞每一次轨迹的刷新。
实验验证
闭环和开环结果
在 CARLA Bench2Drive 闭环评测中,AutoMoT 取得了 87.34 DS / 70.00% SR 的优异成绩,超越了 SimLingo 的 85.07 / 67.27。在引入 Action Refiner 后,AutoMoT+ 进一步提升至 89.42 DS / 74.09% SR,达到了当前的最优水平。这表明,动作细化模块能够有效提升规划质量与任务完成率,也充分验证了 AutoMoT 在完整路线执行中的出色闭环驾驶能力。
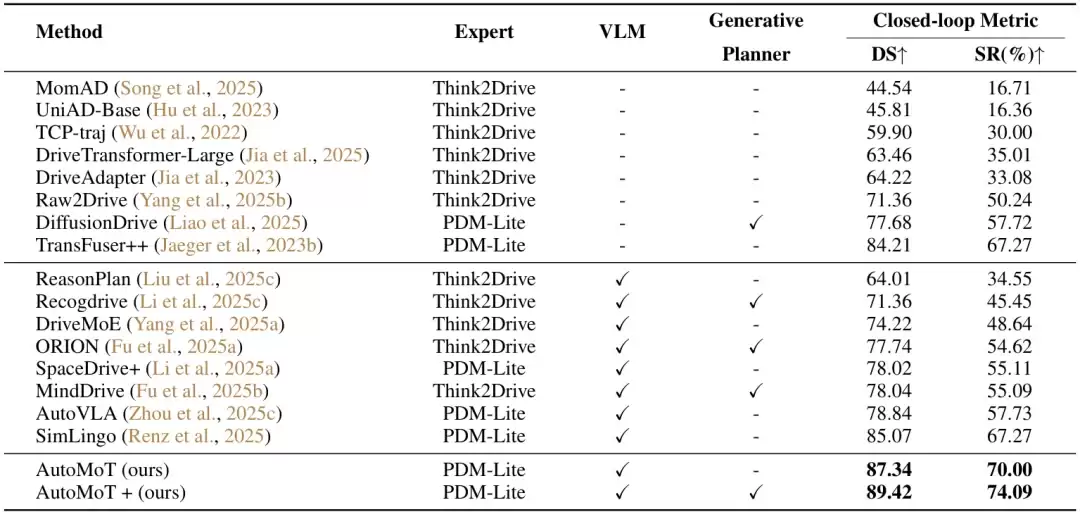
在 nuScenes 开环规划评测中,AutoMoT 在 1秒、2秒、3秒时间尺度上的 L2 误差分别为 0.14、0.29 和 0.54,平均 L2 误差仅为 0.32;对应的碰撞率分别为 0.01%、0.06% 和 0.15%,平均碰撞率低至 0.07%,在安全相关指标上达到了业界领先水平。这说明 AutoMoT 不仅能够保持较低的轨迹预测误差,还能生成更加安全可靠的规划结果。
重新思考基座模型的通用能力:到底要不要完全适配到自动驾驶领域?
AutoMoT 还探讨了一个容易被忽视的深层问题:当预训练基座模型进入自动驾驶领域后,是否需要将其整体微调成一个驾驶专用模型?
在 AutoMoT 的设计哲学中,保留理解专家的预训练能力并不仅仅是为了节省计算资源。随着基座模型能力的不断增强,它们已经具备了强大的通用场景理解、视觉语义建模以及复杂关系推理能力,并在自动驾驶场景理解任务中展现出了卓越水平。
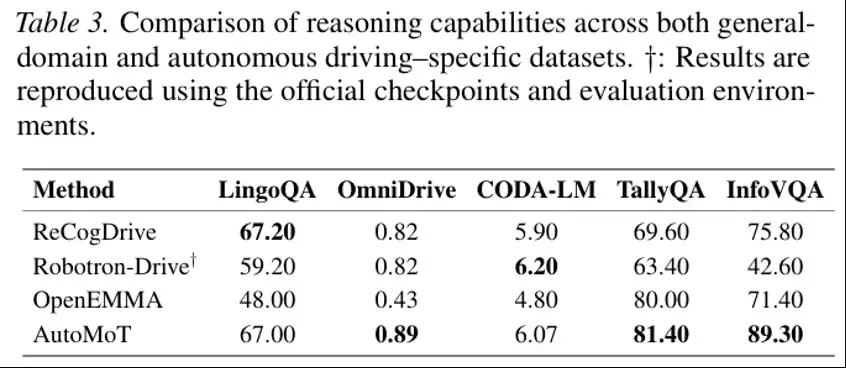
第一组实验比较了 AutoMoT 在自动驾驶任务与通用任务上的推理能力。在自动驾驶场景理解任务中,AutoMoT 在 LingoQA 上达到 67.00 分,接近 ReCogDrive 的 67.20 分;在 OmniDrive 上达到 0.89 分,高于 ReCogDrive 和 Robotron-Drive 的 0.82 分;在 CODA-LM 上达到 6.07 分。与此同时,在 TallyQA 和 InfoVQA 等通用视觉问答任务上,它分别取得了 81.40 分和 89.30 分。这说明,在不将主干网络完全专门化的情况下,AutoMoT 依然能够保持较好的驾驶场景理解能力与通用推理能力。
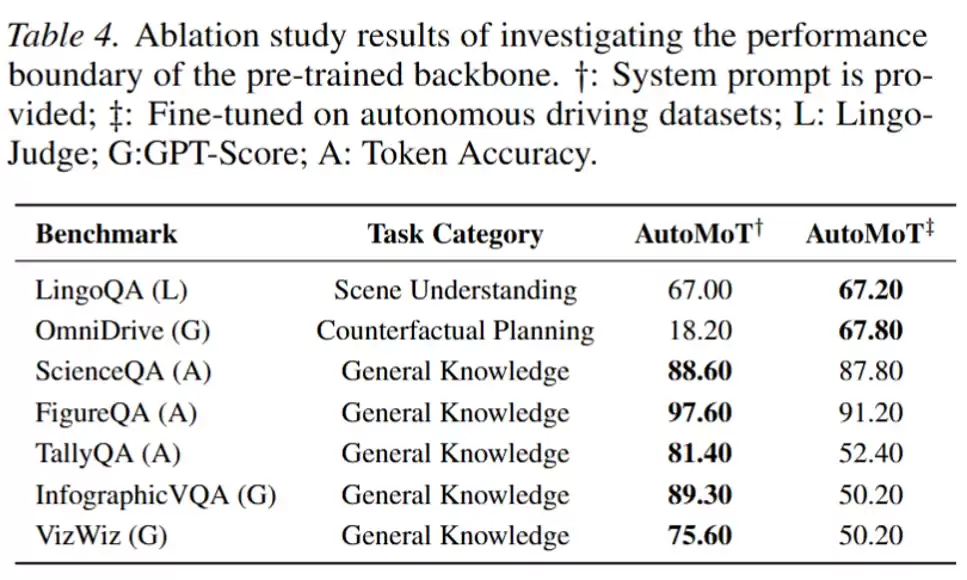
第二组实验则进一步揭示了一个有趣的现象:微调带来的收益并不均匀。对于 LingoQA 这类纯场景理解任务,微调几乎只带来边际提升,分数从 67.00 增至 67.20;但在 OmniDrive 这类更贴近规划和动作层的任务上,提升非常显著,分数从 18.20 跃升至 67.80。这表明,自动驾驶中真正需要强领域适配的部分,更多集中在“如何将场景理解转化为决策和动作”这一关键环节,而非基础的视觉语言理解本身。
然而,整体微调主干网络也会带来显著的代价。微调后,模型在 TallyQA 上的得分从 81.40 骤降至 52.40,在 InfographicVQA 上从 89.30 降至 50.20,在 VizWiz 上从 75.60 降至 50.20。这些结果清晰地表明,如果将整个基座模型深度改造为驾驶专用模型,可能会严重削弱其原本具备的通用理解与复杂推理能力。
因此,AutoMoT 选择了更为明确的分工:理解专家保留预训练视觉语言模型的通用场景理解能力,而动作专家则专门学习自动驾驶中的决策、规划与动作生成。需要强调的是,这并非否定微调的价值,而是主张不同能力应在更合适的模块中进行适配:高层理解能力由理解专家保留,而动作层面的适配则主要由动作专家完成。通过这种设计,整体微调可能带来的通用能力退化问题,得到了巧妙的规避。
结语
AutoMoT 的核心思路,并非让视觉语言模型直接接管驾驶,而是在自动驾驶的视觉-语言-动作系统中,重新组织“理解”与“行动”之间的关系。
因此,AutoMoT 选择保留理解专家的通用理解能力,将自动驾驶中的动作学习任务主要交给动作专家来完成。两者通过逐层共享注意力机制紧密连接,使动作专家在生成决策和轨迹时,能够直接利用理解专家的中间表示,而不仅仅是接收一段外部的文本解释。与此同时,异步推理与键值缓存技术将完整的模型前向推理从每个动作周期中解耦出来,从而显著降低了实时控制中的计算压力。
AutoMoT 为智能驾驶基座模型的适配提供了一种全新的视角。将整个基座模型深度适配到驾驶领域固然有其优势,但往往伴随着更高的标注成本、人力投入与算力开销。AutoMoT 所展现的业界领先性能,则揭示了另一种更高效的可能性:保留基座模型强大的通用场景理解能力,同时将驾驶相关的决策与规划能力交由专门的动作专家进行学习,并通过紧凑的跨模块注意力机制实现二者间的高效协同。这种设计在保持强劲性能的同时,也为面向真实部署的视觉-语言-动作系统提供了一条更具可扩展性的技术路径。
相关攻略

微软提出基于认知科学启发的新记忆框架Mnemis,通过建构式层级图索引与双系统检索(快慢思考)克服传统RAG的语义相似度局限。该方法在LoCoMo和LongMemEval-S基准上分别取得93 9%和91 6%准确率,均达SOTA,已被ACL2026主会议接收。

大语言模型的应用浪潮正席卷而来,但一个核心的瓶颈也日益凸显:AI始终缺乏真正有效的长期记忆能力。目前主流的解决方案——检索增强生成(RAG),虽然能快速调取历史信息,但其依赖的语义相似度检索存在一个根本性缺陷:“语义相似”并不等同于“逻辑相关”。这导致检索结果常常不完整、无法识别信息间的深层关联,更

今日,小米汽车正式推出名为Xiaomi Auto World Model的全新框架,为自动驾驶领域的世界模型技术演进开辟了创新路径。此举标志着行业技术正从初级的“环境感知”阶段,向具备“认知推理与场景演化”能力的高阶形态深度迈进。 简而言之,该框架的核心创新在于,它首次实现了三维场景重建与动态视频生

小米汽车发布全新世界模型框架,将三维重建与视频生成深度耦合,解决了几何保真与内容多样性的矛盾。该一体化设计使两者协同增益,在Waymo等基准测试中全面领先。它应用于合成数据生成、仿真测试与智能座舱,能高效预测环境演化,提升辅助驾驶系统对极端场景的应对能力。

一、背景 当前,视觉-语言-动作模型已成为推动机器人智能发展的核心架构。然而,主流方案如OpenVLA、π0、CogACT普遍存在一个设计局限:它们依赖单一动作模型处理所有任务。这种“通用型”设计在面对真实世界的复杂机器人操控时,其内在矛盾日益凸显。 问题的核心在于机器人任务本身的二元特性。机器人动
热门专题







热门推荐

为什么不能满仓操作?仓位管理是风险控制的第一道防线 在加密市场的惊涛骇浪中,一个核心原则被反复验证:满仓操作,无异于将自己置于毫无退路的悬崖边缘。它背后潜藏着五大风险:市场不确定性下的单点暴露、心理压力导致决策失衡、错失动态再平衡机会、杠杆叠加加剧爆仓、链上痕迹削弱抗审查能力。理解这些风险,是构建稳

对于成长型企业而言,部署AI的最大挑战往往不在于技术本身,而在于算力成本宛如一笔糊涂账——每月支出多少、流向何处、下月预算如何规划,几乎全凭估算。联想最新推出的百应AI 3 0版本,正是精准回应了这一难题。 本次,联想首次为成长型企业打造了一套覆盖全链路的词元经济解决方案,其核心理念极为简洁:将算力

上周,金山办公在武汉举办了WPS AI NEXT线下路演,现场发布的新一代WPS多维表格,凭借一份硬核成绩单引发行业关注。在权威表格智能体评测榜单SpreadSheetBench最新排名中,WPS多维表格的AI智能引擎位列全球第二,仅次于谷歌,充分展现了国产办公软件的AI实力。 当前,多维表格赛道竞

宗门联赛S3赛季引入三线对抗机制,增加排兵布阵博弈;新增战术设计可禁用特定秘术,强化情报收集。同时加入挂机功能降低参与门槛,匹配机制优化提升公平性,位面加速缩短比赛耗时,满足不同玩家需求。

车队运营团队普遍面临两个核心痛点:工具碎片化、手动流程耗时严重。在近期举办的Vision 26峰会上,Motive一口气发布了集成硬件与人工智能的多项创新方案,矛头直指这两个痼疾,将其物理AI运营平台的边界大幅外扩。从本质上看,这套新方案要解决的是一个老问题:如何把散落在不同系统里的数据整合到一个统