一、背景
当前,视觉-语言-动作模型已成为推动机器人智能发展的核心架构。然而,主流方案如OpenVLA、π0、CogACT普遍存在一个设计局限:它们依赖单一动作模型处理所有任务。这种“通用型”设计在面对真实世界的复杂机器人操控时,其内在矛盾日益凸显。
问题的核心在于机器人任务本身的二元特性。机器人动作可明确分为两类:一类是手臂的大范围移动,例如将机械臂从一个位置移动到另一个位置,这要求模型具备全局场景理解能力,且运动路径规划相对灵活;另一类是夹爪的精细操作,如精准抓取或放置小型物体,这需要模型将视觉注意力高度集中于局部细节,并对抓取姿态进行毫米级控制,容错空间极小。这两类动作在路径约束、视觉关注焦点及所需数据分布上存在本质差异。强行让一个模型同时承担“宏观导航”与“微观操控”双重职责,往往会导致性能相互制约。
更关键的是,传统方法缺乏智能的任务阶段感知与调度能力。模型无法自主判断当前步骤需要执行哪类动作,从而动态调用最合适的计算资源。在步骤繁多的长时程复杂任务中,错误容易累积,导致最终失败。三星研究院最新提出的DAM-VLA框架,正是针对这一核心挑战。它首次在模型层面将手臂运动与夹爪操作解耦,并引入动态路由与加权机制,为提升机器人操控的精准度与鲁棒性提供了创新解决方案。
二、核心方法
DAM-VLA的架构体现了“专精化”的设计哲学,通过三个协同工作的核心组件,实现了从环境感知到动作执行的高效闭环。
模块一:双通道视觉编码与VLM骨架
模型并行采用DINOv2和SigLIP两种视觉编码器提取图像特征。其创新之处在于对特征流进行了智能分流:常规视觉token用于多模态融合;而DINOv2产生的class token(蕴含全局场景语义)被专门路由至手臂运动模型;其register token(蕴含局部几何细节)则专门服务于夹爪操作模型。语言模型(LLaMA-2)的浅层输出用于动作类型路由决策,深层输出用于具体动作参数生成。这一设计确保了“全局场景理解”与“局部细节感知”信息能够精准送达对应的专家模型。
模块二:VLM驱动的动作路由机制
这是实现动态任务调度的智能中枢。系统利用视觉语言模型的推理能力,实时判断当前任务阶段是需要执行手臂移动还是夹爪操作。通过一个可学习的路由权重参数w,模型动态选择激活对应的专家模型:当w<0.5时,调用手臂运动模型;当w≥0.5时,则调用夹爪操作模型。两个专家模型均为专用的DiT扩散模型,并行训练:手臂模型接收全局特征,预测大范围位移;夹爪模型接收局部特征,精细预测末端抓取姿态。从而实现了“宏观移动与微观操作”的智能按需切换。
模块三:双尺度动作加权机制
为了进一步提升长序列任务的动作连贯性与可靠性,DAM-VLA引入了双层次加权策略。在轨迹级别,采用非对称高斯分布进行加权,任务起始阶段方差较宽(σ=6),临近状态转换点时方差收窄(σ=2)。这模拟了人类在执行精细操作前需要更充分准备的行为模式。在动作块级别,则采用指数衰减加权(γ=0.8),确保近期预测的动作对后续决策具有更高影响力。两层机制协同作用,显著增强了复杂多步任务中动作序列的时序一致性与稳定性。
三、亮点总结
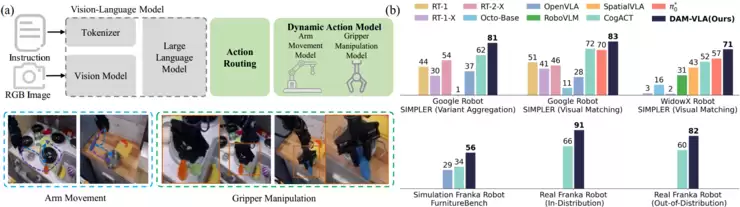
创新点一:真实机器人操控平均成功率86.8%
在Franka机器人执行的抓取-放置任务(共计80次试验)中,DAM-VLA取得了平均86.8%的成功率。这一成绩显著超越了CogACT的62.9%,提升幅度高达23.9个百分点。具体而言,在分布内任务上成功率为91.4%(CogACT为65.7%),在分布外泛化任务上成功率为82.2%(CogACT为60.0%)。无论是在仿真测试还是真实机器人实验中,其性能均全面刷新了现有技术的最高水平。
创新点二:长时程任务最终成功率56%,超越所有基线
在更为复杂的FurnitureBench One-Leg家具组装任务(需要连续5步操控)中,DAM-VLA的最终成功率达到56%。作为对比,CogACT为42%,而OpenVLA仅为29%。深入的消融实验表明,双尺度加权机制是达成这一优异性能的关键。一旦移除此机制,模型性能会出现显著下降,这有力证明了其对维持长时程动作连贯性的核心价值。
创新点三:DINOv2 class/register token分工的关键发现
本研究另一项重要贡献在于,首次通过系统性实验验证了DINOv2视觉编码器中class token与register token天然具备的“全局-局部”信息分工特性。class token更擅长捕捉场景级的整体语义,而register token则包含了物体表面精细的几何与纹理信息。将这两类token分别路由给粗粒度动作和精细操作模型,无需额外的特征对齐训练,即可实现视觉感知与任务阶段的高度自适应匹配。这一发现为未来VLA模型的视觉编码器设计与特征利用提供了宝贵的实证依据和新的优化方向。




