SiFive X280处理器数据手册详解与架构深度解析
在AI芯片这个竞争白热化的领域,一款新处理器的出现,往往意味着技术路线的又一次押注。而SiFive Intelligence X280,作为RISC-V生态中首款面向高性能AI/ML场景的处理器IP,它的登场,显然不只是多了一个选项那么简单。它凭借开放架构、多引擎协同设计以及灵活的扩展能力,正试图在数据中心、边缘计算和汽车电子这些传统巨头盘踞的领域,撕开一道创新的口子。
一、技术架构与核心特性
要理解X280的潜力,得先拆解它的技术内核。这可不是简单的CPU堆料,而是一套深思熟虑的协同作战方案。
1. 多引擎协同计算架构
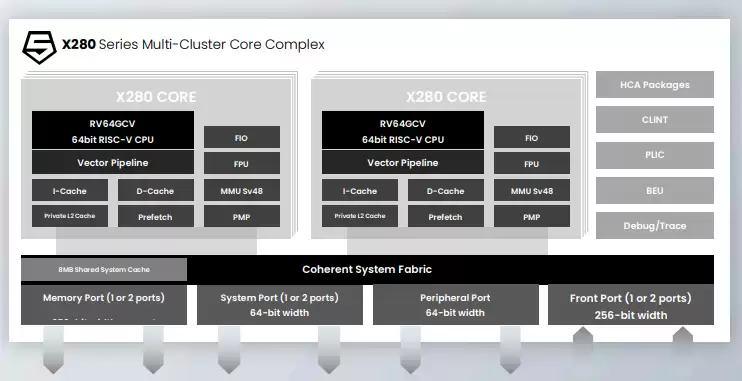
X280的核心思路很清晰:让专业的引擎干专业的事。它采用了标量(RV64GC)、矢量(RVV 1.0)、矩阵(MXU)三引擎融合设计,并支持混合精度运算(INT8/BF16/FP16)。标量引擎负责处理控制逻辑和通用任务,矢量引擎则专注于大规模的并行计算,而矩阵引擎,则是为深度学习中最核心的矩阵乘法运算量身定制的翻跟斗。
更巧妙的是其VCIX(矢量协处理器接口扩展)设计。这个接口允许外部翻跟斗直接访问X280的矢量寄存器文件,实现数据交互延迟仅需数十个周期。这相当于在计算单元之间架设了一条“数据高速公路”,彻底绕过了传统PCIe或内存传输带来的拥堵和延迟瓶颈,让异构计算真正“无缝”起来。
2. 可扩展性与内存优化
单核性能再强,也难敌规模化需求。X280在扩展性上做了充分准备:
• 多集群架构:它支持构建16核的缓存一致集群(Cache-Coherent Complex),单个集群就能提供高达1TB/s的持续内存带宽。更重要的是,通过CHI协议,可以轻松将多个这样的集群扩展起来,以满足大模型推理等对内存带宽和规模极度饥渴的场景。
• 高效缓存设计:私有L1/L2缓存与共享L3缓存的结合,优化了数据流管理,有效减少了冗余的内存访问。有测试数据显示,在MobileNet推理任务中,借助其智能扩展指令,X280能实现标量ISA高达144倍的加速,这背后高效的内存子系统功不可没。
3. 安全与软件生态
硬件再先进,没有软件和安全的支撑也是空中楼阁。X280提供了WorldGuard可信执行环境,并支持ASIL-D级功能安全,这直接瞄准了汽车电子等高可靠性、高安全性的应用场景。在软件层面,它兼容主流的PyTorch/TensorFlow框架,并集成了SiFive Kernel Library(SKL)和OpenXLA PJRT Runtime,大大简化了开发者在异构翻跟斗上的编程难度,让开发者能更专注于算法本身。
SiFive Intelligence
X280 Key Features
- SiFive Intelligence Extensions for ML workloads
- Custom instructions to greatly accelerate Neural Network computation
- Optimized TensorFlow Lite implementation
- Hundreds of Neural Network models ported
- 4.6 TOPS performance
- 512-bit vector register length processor
- Variable length operations, up to 512-bits of data per cycle
- Ideal balance of control logic and data parallel compute
- Decoupled Vector pipeline
- INT8 to INT64 integer data type
- BF16/FP16/FP32/FP64 floating point data type
- Performance benchmarks
- 5.75 CoreMarks/MHz
- 3.25 DMIPS/MHz
- 4.6 SpecINT2k6/GHz
- Built on silicon-proven U7-Series core
- 64-bit RISC-V ISA
- 8-stage dual-issue in-order pipeline
- Coherent multi-core, Linux capable
- High performance vector memory subsystem
- Memory parallelism provides cache miss tolerance
- Virtual memory support with precise exceptions
- Up to 48-bit addressing
- Multi-core, multi-cluster processor configuration, up to 8 cores
二、性能表现与能效优势
纸上谈兵终觉浅,是骡子是马还得拉出来溜溜。X280在性能与能效的平衡上,给出了颇具竞争力的答案。
• 算力密度:其单核性能可达4.5 SpecINT2k6/GHz(高性能配置),并支持每GHz实现16 TOPS(INT8)或8 TFLOPS(BF16)的算力。这样的算力密度,对于需要高吞吐量的边缘AI推理场景来说,非常具有吸引力。
• 能效比:这可能是X280最锋利的刀刃之一。与传统的GPU方案相比,在提供同等算力的情况下,X280的功耗据称可降低30%以上。对于功耗敏感型的自动驾驶和物联网设备而言,这样的能效提升意味着更长的续航、更小的散热设计和更低的整体运营成本。
• 灵活性:它支持动态矢量长度调整,其512位寄存器可以灵活组合,最高支持到4096位的长向量运算。这种灵活性允许芯片设计者根据特定的工作负载优化硬件资源,在提升运算效率的同时,有效控制芯片面积和功耗,实现定制化与高效能的统一。
三、应用场景与典型案例
技术最终要落地于场景。X280的触角,已经伸向了几个关键领域。
1. 数据中心AI加速
一个标志性的案例是谷歌。谷歌在其TPU系统中,采用了X280作为配套的管理节点。通过前述的VCIX接口,X280直接连接谷歌自研的MXU(脉动矩阵乘法器),实现了AI负载的灵活、高效分配。X280在这里扮演“大脑”角色,负责运行Linux系统和管理代码,而MXU则作为强力的“肌肉”执行核心计算。这种协同,显著提升了大语言模型(如Llama)的推理效率。
2. 边缘计算与消费电子
• 智能摄像头/AR设备:在这些设备上,实时性就是生命。X280的矢量单元能够高效处理图像识别与语音交互任务,例如在MobileNet任务中实现24倍于纯标量架构的加速,让端侧AI响应更快、更智能。
• 汽车电子:车规级要求极为严苛。X280-A版本专门为此设计,支持ADAS系统的实时目标检测,并符合ISO 26262 ASIL-D标准。目前,它已被多家一线汽车零部件供应商所采用,这无疑是对其可靠性和性能的强力背书。
3. 异构计算平台
X280还可以与SiFive的P系列高性能CPU(如P870)组成混合架构,这种思路类似于Arm的big.LITTLE设计。在数据中心环境中,这种架构可以实现高效的任务调度与能效优化,让合适的核心处理合适的任务。
四、行业影响与未来趋势
X280的出现,其意义超越了一款产品本身,更像是一枚投入平静湖面的石子,激起了层层涟漪。
1. 挑战传统架构垄断
其开放的RISC-V生态,正吸引着像谷歌、特斯拉这样的巨头尝试用它来替代部分传统的NVIDIA GPU或Arm方案。谷歌放弃自研TPU管理核心,转而采用“X280+VCIX”架构,就是一个明确的信号:开放、灵活的架构能节省大量开发周期,并带来更高的设计自由度。
2. 推动RISC-V进入高性能市场
长期以来,RISC-V给人的印象多停留在微控制器(MCU)领域。X280通过其强大的矢量扩展与多核集群设计,成功将RISC-V的应用边界推向了数据中心和自动驾驶等高性能计算场景,显著缩小了与x86/Arm在这些高端领域的差距。
3. 生态合作与标准化
独木难成林。SiFive正与谷歌合作,积极推动RISC-V对Android系统的兼容性。同时,它也深度参与制定RISC-V的UEFI、SBI等基础系统规范。这些举措都在加速RISC-V整个软件与应用生态的成熟,为像X280这样的高性能芯片铺平道路。
总结
总而言之,SiFive Intelligence X280凭借其开放架构、多引擎协同、高能效比这三大核心优势,已然成为RISC-V生态冲击主流AI芯片市场的一个里程碑。它与谷歌TPU的深度整合、满足车规级要求的安全特性,以及灵活的可扩展能力,不仅验证了RISC-V在高性能场景下的技术可行性,更在推动一场从边缘到云端的全栈AI计算范式革新。随着生成式AI与自动驾驶需求的爆炸式增长,一个更加异构、开放的计算时代正在到来,而X280,很可能成为构建这个新时代的关键组件之一。
相关攻略

SiFiveIntelligenceX280是RISC-V生态中首款面向高性能AI ML场景的处理器IP。它采用标量、矢量、矩阵三引擎协同架构,支持灵活扩展与高效内存设计,提供高算力密度与优异能效比。该处理器已应用于数据中心AI加速、边缘计算及汽车电子等领域,凭借开放架构与生态合作,正推动RISC-V进入高性能计算市场并挑战传统方案。

pUniFind是多模态蛋白质组学基础模型,首次统一开放式肽段-谱图评分与零样本从头测序。基于超1亿条谱图训练,通过跨模态学习对齐谱图与序列信息。实验显示其在多个数据集中鉴定肽段数量超越传统方法,免疫肽组学提升42 6%,并能高效识别修饰与隐藏肽段,显著提升鉴定灵敏度与可信度。

近期,PC Games Hardware 进行了一项引人关注的性能对比测试,其结果令人颇感意外:英特尔新一代 Bartlett Lake 系列的旗舰型号酷睿9 273PQE,在多项游戏基准测试中,竟然未能超越四年前发布的酷睿 i9-13900K。 单从规格参数来看,酷睿9 273PQE 其实颇具亮点

5月12日,市场研究机构Omdia发布了一份由分析师夏茂森撰写的最新报告,深入剖析了软银与OpenAI成立合资公司这一重磅动作。报告的核心观点很明确:软银这次押注名为“Cristal Intelligence”的AI平台,绝非一时兴起,而是一场融合了宏大战略愿景与精密风险计算的复杂棋局。 事情是这样

在麒麟操作系统上使用 IntelliJ IDEA 进行软件开发时,若遇到缺少特定语言支持、框架集成或辅助功能的情况,这通常并非操作系统或 IDE 本身的缺陷,而往往是由于相关插件未安装、未启用,或与当前 IDE 版本及系统架构不兼容所致。无需担忧,遵循以下步骤,即可轻松为你的 IntelliJ ID
热门专题







热门推荐

《Paralives》开发商承诺所有后续更新永久免费,拒绝付费DLC模式。15人小团队依靠首发销售额即可支撑多年运营,无需依赖额外内容包维持开发,展现了与《模拟人生》系列不同的差异化竞争思路。

2025年5月28日,比亚迪王朝网全新力作——宋Ultra DM-i正式推向市场,共推出5款配置车型,官方售价区间为12 99万至15 99万元。此次定价策略极具突破性:一款拥有310公里纯电续航能力的中型插电混动SUV,直接下探至13万元级别市场。作为王朝网络的新旗舰,该车明确瞄准高频出行需求场景

先来关注一个有趣的细节:苹果首款折叠屏手机,传闻将于今年秋季正式亮相。产品命名可能为iPhone Ultra,也有媒体称之为iPhone Fold——无论最终叫什么,这都将标志着苹果在折叠形态领域首次“出手”。 近日,配件厂商iFunSmart已率先上架iPhone Ultra的首批保护壳——这绝非

山寨币ETF迎来批量上市潮,首批项目市场表现如何?一文分析 Binance币安 欧易OKX ️ Huobi火币️ 最近,市场出现了一个不容忽视的新动向:XRP、DOGE、LTC、HBAR等现货ETF已经悄然登陆美国市场。与此同时,A VAX、LINK等资产的同类产品也正在审批流程中。进入11月以来,

近日,公司对SteamDeck1TBOLED版涨价300美元至949美元,上架短短不到24小时便再度售罄。据外界分析,该公司从中国大量补货并分批投放库存,高溢价未影响众多玩家的抢购热情与速度,其人气极其旺盛无比足以支撑快速清空。